

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
作者丨武廣
學校丨合肥工業大學碩士生
研究方向丨影象生成
視覺和聽覺存在著緊密的關聯,同時空下視覺和聽覺不僅在語意上存在著一致性,在時序上也是對齊的。失聰患者可以利用視覺資訊做出判斷,盲人也可以利用聽覺資訊做出判斷,而一般正常人對事物的決策往往是結合視覺和聽覺協同完成的。
達特茅斯學院和 Facebook 聯合發表於 NeurIPS 2018 的這篇文章正是透過對視覺和聽覺資訊做同一性判斷,在整體上最佳化視覺特徵和聽覺特徵提取網路,在獨立模態下也提高了各自的任務準確率。不同於我們之前說的 Look, Listen and Learn [1],這篇論文不僅僅在語意上判斷視覺和聽覺的一致性,還在時序上做了嚴格對齊判斷。


論文引入
日常休閑娛樂很多人喜歡看電影,有時看電影的過程中會出現畫面和音訊對不上的情況,這會大大降低觀影體驗。為什麼我們會察覺到畫面和音訊對不上呢?
這就是人類潛意識裡已經建立了視覺和聽覺上對應的關係,一旦客觀現象中視覺和聽覺資訊對應不上,我們立馬就會發現哪裡出現了問題。人類不僅僅可以察覺畫面和音訊對應不上,結合已有的知識甚至可以推斷是畫面延遲了還是音訊延遲了。
目前機器學習大部分還是停留在單一模態下資訊的分析和學習,比如計算機視覺是一個大的研究方向,音訊分析和處理又是一個方向。然而,機器如果想更進一步的智慧化,必須要像人類一樣,利用多模態去分析和學習,結合不同模態下的資訊和聯絡做出判斷和決策。
已經有越來越多的研究者關註到了多模態資訊的學習,跨模態檢索、遷移學習、多模態資訊聯合決策、跨模態轉換等。視覺和聽覺這兩個模態,本身就是嚴格關聯的,只要物體運動了,視覺上的變化勢必會帶來聽覺上聲音的產生,如何結合視覺和聽覺資訊去提高視覺任務和聽覺任務的處理,正是我們今天要看的這篇論文的核心。
如何去結合視覺和聽覺資訊呢?論文采用的方式是“視聽覺時間同步”英文縮寫為 AVTS (Audio-Visual Temporal Synchronization),就是在語意和時序上對視覺和聽覺資訊做對齊判斷,如果視覺資訊和聽覺資訊不僅在語意上是關聯的(影片和聲音是可以對上的)而且在時序上也是對齊的(影片和聲音不存在延遲,是對齊關係的)就判斷為同步資訊,否則認為是非同步。最佳化決策結果,則會提高視覺和聽覺特徵提取網路,特徵提取好了自然在獨立的任務上可以取得改善。
筆者在之前的論文解讀中對 Look, Listen and Learn 一文簡稱為![]() 做過分析 [2],
做過分析 [2],![]() 也是對視覺和聽覺資訊做關聯性判斷,但是判斷視覺和聽覺關聯上僅僅是透過語意上是否關聯判斷的,而論文 AVTS 則是在此基礎上考慮到影片的時序資訊,進一步嚴格了視覺和聽覺的同步性判斷。
也是對視覺和聽覺資訊做關聯性判斷,但是判斷視覺和聽覺關聯上僅僅是透過語意上是否關聯判斷的,而論文 AVTS 則是在此基礎上考慮到影片的時序資訊,進一步嚴格了視覺和聽覺的同步性判斷。
利用影片和音訊之間的相關性作為特徵學習的方法,在訓練過程中是不引入人為標簽的,拿來影片和音訊只需要知道是否是同步的不需要任何其它的標簽就可以最佳化整體網路,這種方式符合自監督學習方法,所以論文的標題特意強調文章是在自監督下完成同步性判斷的。
這對於處理影片這樣的大資料集是可觀的,一旦利用 AVTS 自監督方式預訓練好特徵提取網路可以在微調階段發揮出更好的效果的同時,不引入額外的標註開銷。
總結一下 AVTS 的優勢:
-
視覺聽覺在語意和時序同步性判斷;
-
視聽覺相關性判斷,實現了自監督學習特徵提取;
-
預訓練 AVTS 模型在視覺資訊和聽覺資訊獨立任務上取得了提高。
AVTS模型
VTS 模型是對視覺資訊和聽覺資訊在語意和時序上同步性的判斷,判斷結果是二分類問題,要麼同步要麼不同步,我們先看一下模型框架:
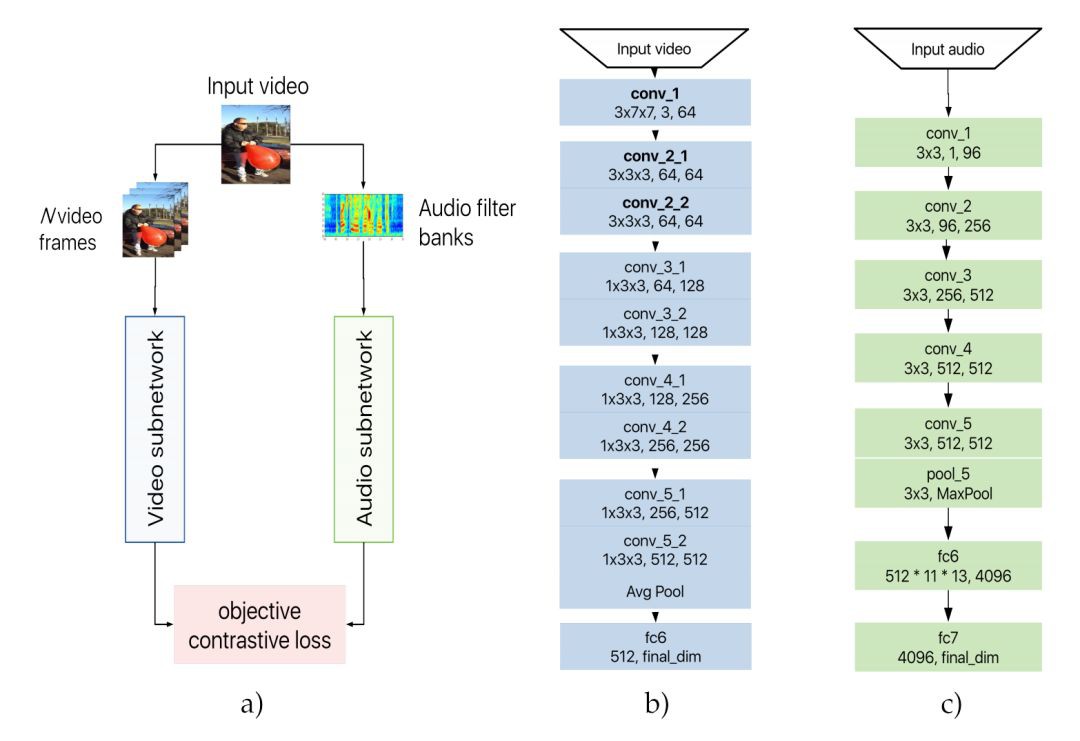
由上圖 (a) 所示,AVTS 模型採取的是雙流結構,一路是影片特徵提取網路,一路是音訊特徵提取網路,對提取得到的特徵利用對比度損失進行最佳化。
整體上看 AVTS 還是很容易理解的,我們要強調一下具體的實現。
我們先從模型最佳化的訓練集說起。 整體訓練集定義為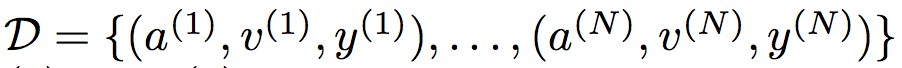 由 N 個標記的音訊影片對組成。其中 a(n) 表示音訊第 n 個樣本,v(n) 表示影片第 n 個樣本(影片由連續幀組成),標簽 y(n)∈{0,1} 表示影片和音訊是否同步,0 為不同步,1 為同步。
由 N 個標記的音訊影片對組成。其中 a(n) 表示音訊第 n 個樣本,v(n) 表示影片第 n 個樣本(影片由連續幀組成),標簽 y(n)∈{0,1} 表示影片和音訊是否同步,0 為不同步,1 為同步。
訓練集選擇同一影片下時序對應的影片和音訊為同步的正例,對於負例,定義不同影片下影片和音訊為簡單負例,同一影片下時序不同步的為硬(“hard”)負例,硬負例下時序相差太遠的定義為超硬負例,我們由下圖可以進一步理解正負例定義原則。

最佳化 AVTS 模型中,論文作者一開始直接採用交叉熵損失進行最佳化,發現從頭開始學習時很難在這種損失下實現模態間的融合,透過最小化對比度損失可以獲得更一致和穩健的最佳化,在正對上產生小距離,在負對上產生更大距離:
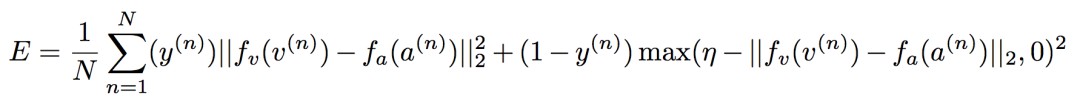
其中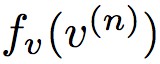 為影片提取的特徵表示,
為影片提取的特徵表示,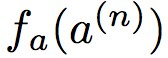 為音訊提取的特徵表示,對於標簽 y(n)=1 時,此時最小化對比度損失E時需要與盡可能相近,也就是希望同步的影片特徵和音訊特徵儘量相近。
為音訊提取的特徵表示,對於標簽 y(n)=1 時,此時最小化對比度損失E時需要與盡可能相近,也就是希望同步的影片特徵和音訊特徵儘量相近。
對於非同步的影片-音訊對,即 y(n)=0 時,對應到公式的後一項,只有當與距離越遠的時候,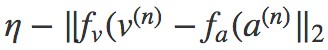 才會比 0 要小,此時 max 達到最佳值 0,其中 η 為邊際超引數。
才會比 0 要小,此時 max 達到最佳值 0,其中 η 為邊際超引數。
對於影片特徵提取網路 (b),文章採用 2D 和 3D 摺積網路結合實現,我們簡單分析一下 3D 摺積網路,對於 (b) 圖中對應的是前 2 個摺積塊,後 3 個摺積塊為 2D 摺積網路,最後一層為全連線層。
3D 摺積網路下影片輸入是包含幀的,這裡輸入的影片幀為 3,長寬為 7 × 7,通道數為 3,batchsize 為 64。論文解釋為在特徵提取的後半部分將不再依靠時間軸,這時候可以直接利用 2D 摺積網路,論文稱這種方法為混合摺積架構(MC),實驗也驗證了混合架構效能要好些。
對於音訊資訊,先要對音訊資訊提取對應的聲譜圖然後再對其利用2D摺積網路做特徵提取,網路結構為 (c) 圖展示。
課程方式訓練
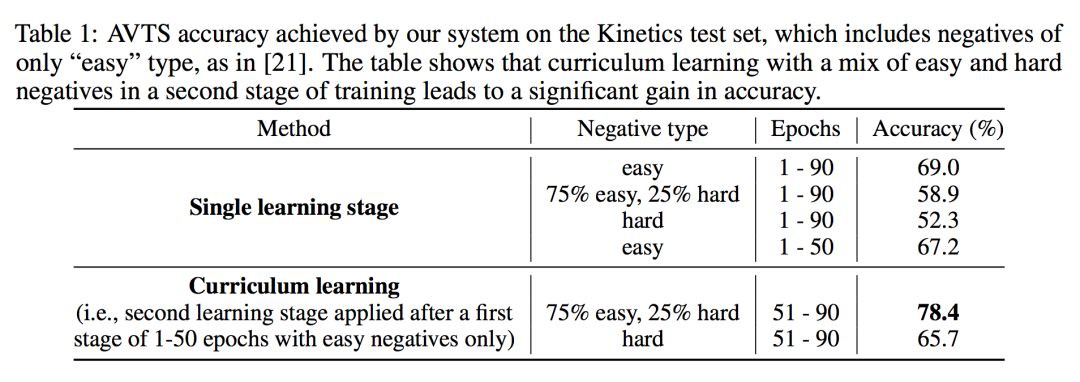
論文在訓練模型的時候發現,如果一開始對負例的選擇上簡單負例和硬負例按 3:1 訓練時,訓練效果很一般。論文認為一開始讓模型去區分硬負例有些太難了,文章採用循序漸進增進難度的方式。
論文實驗發現在前 50 個 epoch 下負例只選擇簡單負例,在 51-90 epoch 下簡單負例和硬負例按 3:1 訓練時,模型效果最佳。這個也符合人類的學習方式,一上來就做難題不僅打擊自信,基礎也不能打扎實,只有掌握了充分的基礎知識後,再做些難題才能錦上添花。
論文對比了設定課程的效果:
實驗
訓練上邊際超參 η 為 0.99,訓練在四塊 GPU 機器上完成,每個 GPU 有一個小批次的 16 個樣本。每次損失值在超過 5 個時期內沒有減少時,學習率將縮放 0.1。
在驗證視覺訊號和聽覺訊號同步性問題,論文做了與![]() 的對比:
的對比:
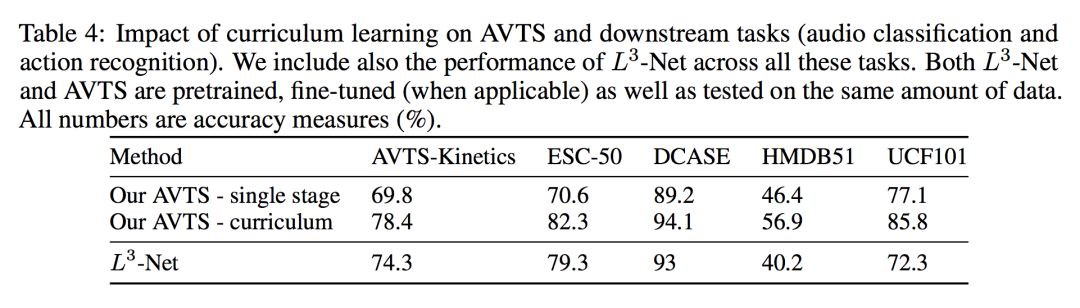
在評估視覺特徵效能時,正如預期的那樣,使用動作類標簽對 Kinetics 資料集進行預訓練可以提高 UCF101 和 HDMB51 的準確度。但是,這會佔用 500K 影片剪輯上手動標記的巨大成本。相反,AVTS 預訓練是自監督的,因此它可以應用於更大的資料集而無需額外的人工成本。
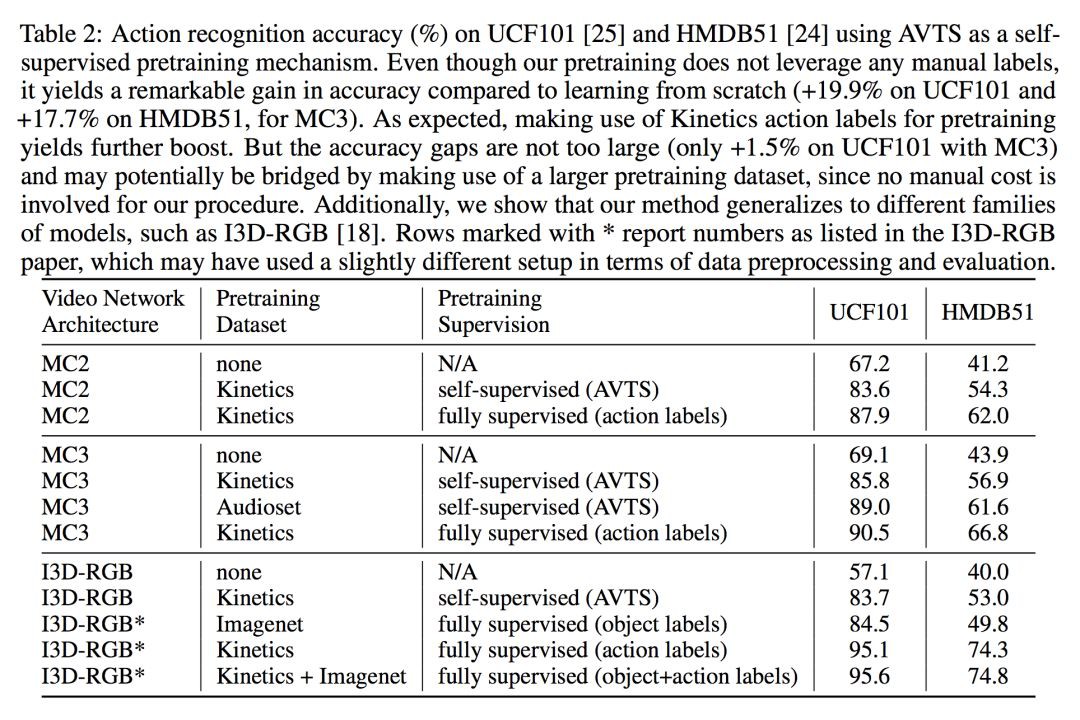
在評估聽覺特徵效能時,直接在音訊特徵提取的 conv_5 AVTS 功能上訓練多類一對一線性 SVM,以對音訊事件進行分類。透過對樣本中的分數求平均來計算每個音訊樣本的分類分數,然後預測具有較高分數的類。
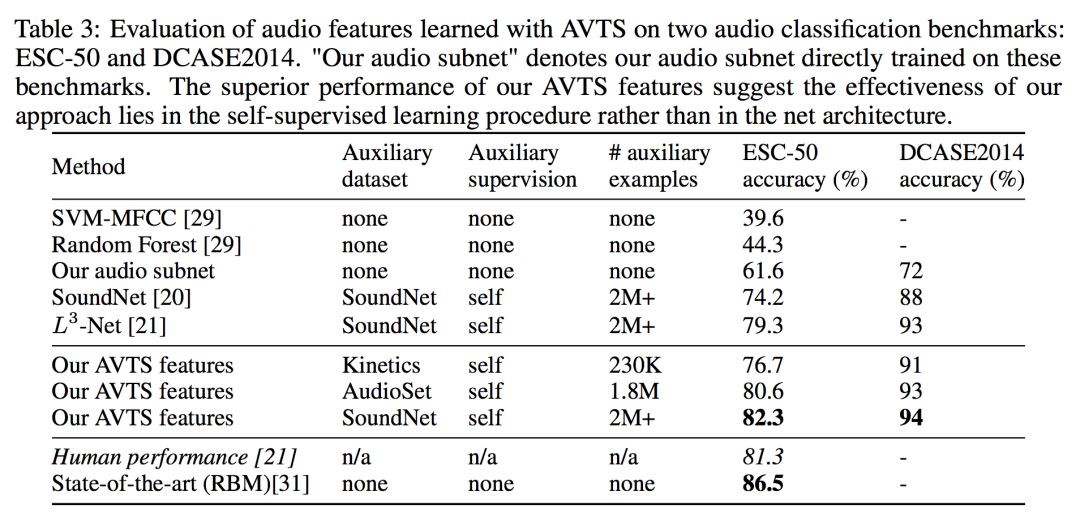
可以看到,AVTS 在音訊分類任務上取得了比人工稍好的效果。更多實驗,可以進一步閱讀原文。
總結
視聽覺時間同步(AVTS)的自監督機制可用於學習音訊和視覺領域的模型,透過視覺和聽覺上的相關性實現視覺和聽覺上效能的提高,視覺和聽覺上的關聯,對於視覺下運動分析可以很好的結合聽覺上的特徵資訊進一步提高判別和識別的準確。可以想象。視聽覺結合對於提高分類和識別任務上還有進一步提升空間。
參考文獻
[1] Relja Arandjelović and Andrew Zisserman. ook, Listen and Learn. In ICCV 2017.
[2] www.paperweekly.site/papers/notes/594
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:
讓你的論文被更多人看到 如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。 總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。 PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
 #投 稿 通 道#
#投 稿 通 道#