-
etcd is a distributed reliable key-value store for the most critical data of a distributed system…
-
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
service KV {rpc Range(RangeRequest) returns (RangeResponse) {option (google.api.http) = {post: "/v3beta/kv/range"body: "*"};}rpc Put(PutRequest) returns (PutResponse) {option (google.api.http) = {post: "/v3beta/kv/put"body: "*"};}}
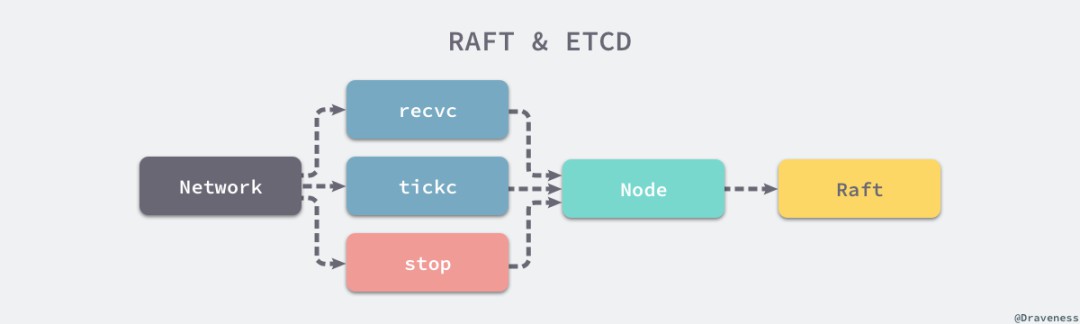
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/node.go#L190-225func StartNode(c *Config, peers []Peer) Node {r := newRaft(c)r.becomeFollower(1, None)r.raftLog.committed = r.raftLog.lastIndex()for _, peer := range peers {r.addNode(peer.ID)}n := newNode()go n.run(r)return &n}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/node.go#L291-423func (n *node) run(r *raft) {lead := Nonefor {if lead != r.lead {lead = r.lead}select {case m := n.recvc:r.Step(m)case n.tickc:r.tick()case n.stop:close(n.done)return}}}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L636-643func (r *raft) tickElection() {r.electionElapsed++if r.promotable() && r.pastElectionTimeout() {r.electionElapsed = 0r.Step(pb.Message{From: r.id, Type: pb.MsgHup})}}
func (r *raft) tickHeartbeat() {r.heartbeatElapsed++r.electionElapsed++if r.heartbeatElapsed >= r.heartbeatTimeout {r.heartbeatElapsed = 0r.Step(pb.Message{From: r.id, Type: pb.MsgBeat})}}
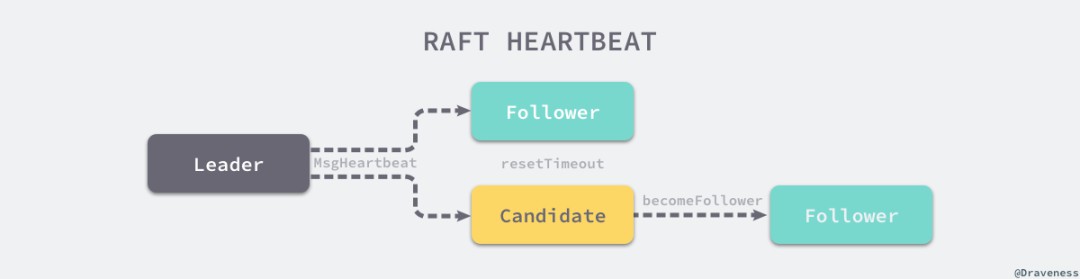
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L931-1142func stepLeader(r *raft, m pb.Message) error {switch m.Type {case pb.MsgBeat:r.bcastHeartbeat()return nil// ...}//...}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L518-534func (r *raft) sendHeartbeat(to uint64, ctx []byte) {commit := min(r.getProgress(to).Match, r.raftLog.committed)m := pb.Message{To: to,Type: pb.MsgHeartbeat,Commit: commit,Context: ctx,}r.send(m)}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L1191-1247func stepFollower(r *raft, m pb.Message) error {switch m.Type {case pb.MsgHeartbeat:r.electionElapsed = 0r.lead = m.Fromr.handleHeartbeat(m)// ...}return nil}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L1146-1189func stepCandidate(r *raft, m pb.Message) error {// ...switch m.Type {case pb.MsgHeartbeat:r.becomeFollower(m.Term, m.From) // always m.Term == r.Termr.handleHeartbeat(m)}// ...return nil}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L636-643func (r *raft) tickElection() {r.electionElapsed++if r.promotable() && r.pastElectionTimeout() {r.electionElapsed = 0r.Step(pb.Message{From: r.id, Type: pb.MsgHup})}}
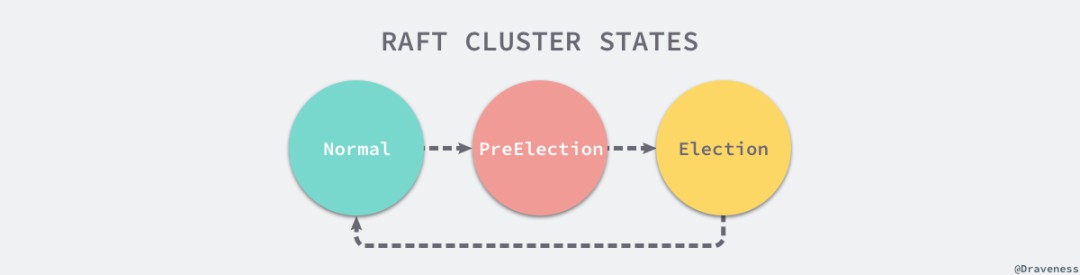
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L785-927func (r *raft) Step(m pb.Message) error {// ...switch m.Type {case pb.MsgHup:if r.state != StateLeader {if r.preVote {r.campaign(campaignPreElection)} else {r.campaign(campaignElection)}} else {r.logger.Debugf("%x ignoring MsgHup because already leader", r.id)}}// ...return nil}
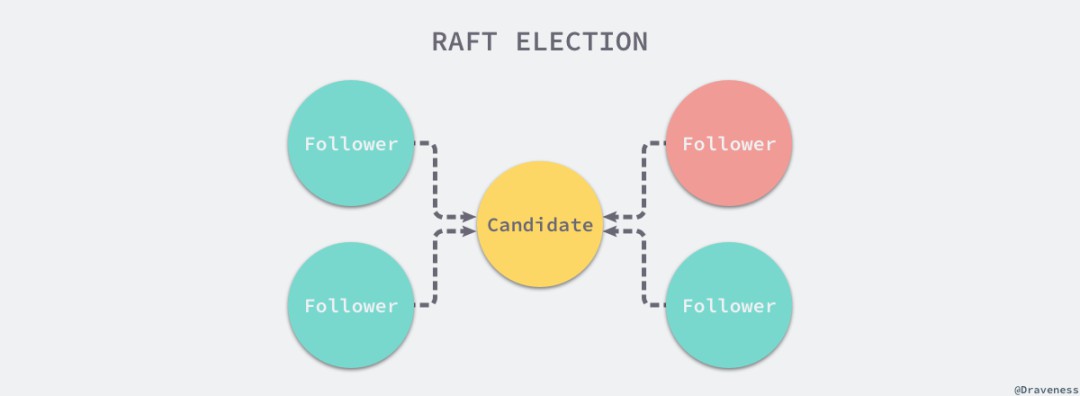
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L730-766func (r *raft) campaign(t CampaignType) {r.becomeCandidate()if r.quorum() == r.poll(r.id, voteRespMsgType(voteMsg), true) {r.becomeLeader()return}for id := range r.prs {if id == r.id {continue}r.send(pb.Message{Term: r.Term, To: id, Type: pb.MsgVote, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx})}}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L785-927func (r *raft) Step(m pb.Message) error {// ...switch m.Type {case pb.MsgVote, pb.MsgPreVote:canVote := r.Vote == m.From || (r.Vote == None && r.lead == None)if canVote && r.raftLog.isUpToDate(m.Index, m.LogTerm) {r.send(pb.Message{To: m.From, Term: m.Term, Type: pb.MsgVoteResp})r.electionElapsed = 0r.Vote = m.From} else {r.send(pb.Message{To: m.From, Term: r.Term, Type: pb.MsgVoteResp, Reject: true})}}// ...return nil}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L1146-1189func stepCandidate(r *raft, m pb.Message) error {switch m.Type {// ...case pb.MsgVoteResp:gr := r.poll(m.From, m.Type, !m.Reject)switch r.quorum() {case gr:r.becomeLeader()r.bcastAppend()// ...}}return nil}
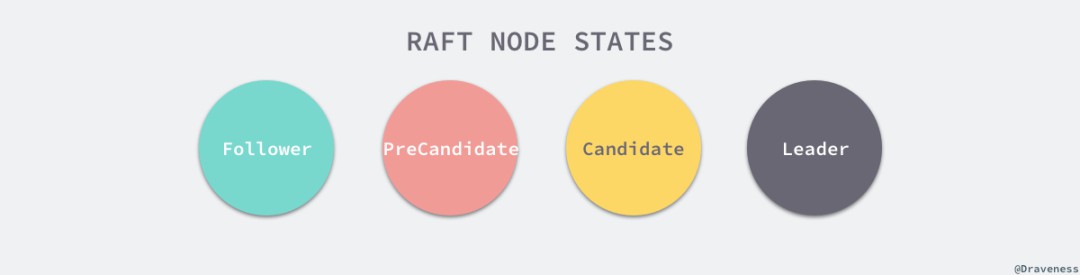
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L671-678func (r *raft) becomeFollower(term uint64, lead uint64) {r.step = stepFollowerr.reset(term)r.tick = r.tickElectionr.lead = leadr.state = StateFollower}// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L636-643func (r *raft) tickElection() {r.electionElapsed++if r.promotable() && r.pastElectionTimeout() {r.electionElapsed = 0r.Step(pb.Message{From: r.id, Type: pb.MsgHup})}}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L680-691func (r *raft) becomeCandidate() {r.step = stepCandidater.reset(r.Term + 1)r.tick = r.tickElectionr.Vote = r.idr.state = StateCandidate}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L708-728func (r *raft) becomeLeader() {r.step = stepLeaderr.reset(r.Term)r.tick = r.tickHeartbeatr.lead = r.idr.state = StateLeaderr.pendingConfIndex = r.raftLog.lastIndex()r.appendEntry(pb.Entry{Data: nil})}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/raft/raft.go#L646-669func (r *raft) tickHeartbeat() {r.heartbeatElapsed++r.electionElapsed++if r.electionElapsed >= r.electionTimeout {r.electionElapsed = 0if r.checkQuorum {r.Step(pb.Message{From: r.id, Type: pb.MsgCheckQuorum})}}if r.heartbeatElapsed >= r.heartbeatTimeout {r.heartbeatElapsed = 0r.Step(pb.Message{From: r.id, Type: pb.MsgBeat})}}
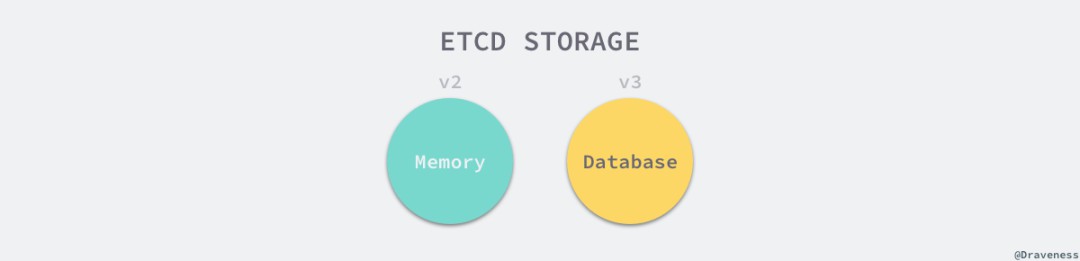
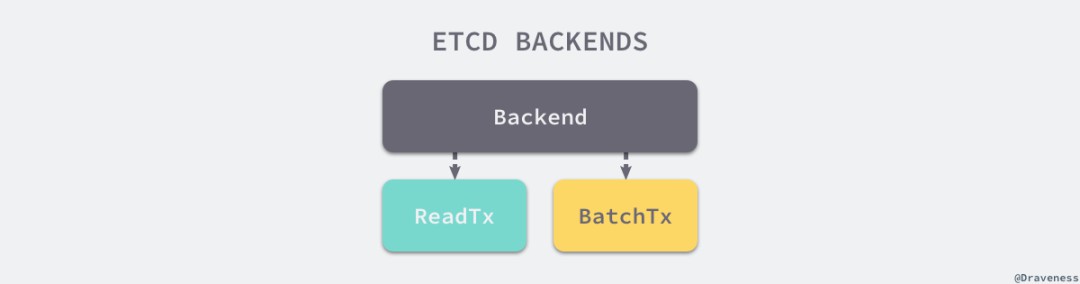
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/backend.go#L51-69type Backend interface {ReadTx() ReadTxBatchTx() BatchTxSnapshot() SnapshotHash(ignores map[IgnoreKey]struct{}) (uint32, error)Size() int64SizeInUse() int64Defrag() errorForceCommit()Close() error}

// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/backend.go#L80-104type backend struct {size int64sizeInUse int64commits int64mu sync.RWMutexdb *bolt.DBbatchInterval time.DurationbatchLimit intbatchTx *batchTxBufferedreadTx *readTxstopc chan struct{}donec chan struct{}lg *zap.Logger}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/read_tx.go#L30-36type ReadTx interface {Lock()Unlock()UnsafeRange(bucketName []byte, key, endKey []byte, limit int64) (keys [][]byte, vals [][]byte)UnsafeForEach(bucketName []byte, visitor func(k, v []byte) error) error}// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L28-38type BatchTx interface {ReadTxUnsafeCreateBucket(name []byte)UnsafePut(bucketName []byte, key []byte, value []byte)UnsafeSeqPut(bucketName []byte, key []byte, value []byte)UnsafeDelete(bucketName []byte, key []byte)Commit()CommitAndStop()}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/backend.go#L137-176func newBackend(bcfg BackendConfig) *backend {bopts := &bolt.Options{}bopts.InitialMmapSize = bcfg.mmapSize()db, _ := bolt.Open(bcfg.Path, 0600, bopts)b := &backend{db: db,batchInterval: bcfg.BatchInterval,batchLimit: bcfg.BatchLimit,readTx: &readTx{buf: txReadBuffer{txBuffer: txBuffer{make(map[string]*bucketBuffer)},},buckets: make(map[string]*bolt.Bucket),},stopc: make(chan struct{}),donec: make(chan struct{}),}b.batchTx = newBatchTxBuffered(b)go b.run()return b}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/backend.go#L289-305func (b *backend) run() {defer close(b.donec)t := time.NewTimer(b.batchInterval)defer t.Stop()for {select {case t.C:case b.stopc:b.batchTx.CommitAndStop()return}if b.batchTx.safePending() != 0 {b.batchTx.Commit()}t.Reset(b.batchInterval)}}
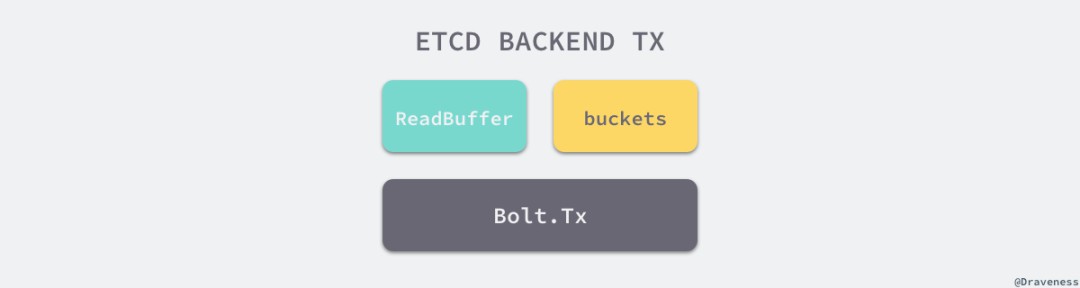
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/read_tx.go#L38-47type readTx struct {mu sync.RWMutexbuf txReadBuffertxmu sync.RWMutextx *bolt.Txbuckets map[string]*bolt.Bucket}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/read_tx.go#L52-90func (rt *readTx) UnsafeRange(bucketName, key, endKey []byte, limit int64) ([][]byte, [][]byte) {if endKey == nil {limit = 1}keys, vals := rt.buf.Range(bucketName, key, endKey, limit)if int64(len(keys)) == limit {return keys, vals}bn := string(bucketName)bucket, ok := rt.buckets[bn]if !ok {bucket = rt.tx.Bucket(bucketName)rt.buckets[bn] = bucket}if bucket == nil {return keys, vals}c := bucket.Cursor()k2, v2 := unsafeRange(c, key, endKey, limit-int64(len(keys)))return append(k2, keys...), append(v2, vals...)}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L121-141func unsafeRange(c *bolt.Cursor, key, endKey []byte, limit int64) (keys [][]byte, vs [][]byte) {var isMatch func(b []byte) boolif len(endKey) > 0 {isMatch = func(b []byte) bool { return bytes.Compare(b, endKey) < 0 }} else {isMatch = func(b []byte) bool { return bytes.Equal(b, key) }limit = 1}for ck, cv := c.Seek(key); ck != nil && isMatch(ck); ck, cv = c.Next() {vs = append(vs, cv)keys = append(keys, ck)if limit == int64(len(keys)) {break}}return keys, vs}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L40-46type batchTx struct {sync.Mutextx *bolt.Txbackend *backendpending int}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L243-246type batchTxBuffered struct {batchTxbuf txWriteBuffer}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L65-67func (t *batchTx) UnsafePut(bucketName []byte, key []byte, value []byte) {t.unsafePut(bucketName, key, value, false)}// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L74-103func (t *batchTx) unsafePut(bucketName []byte, key []byte, value []byte, seq bool) {bucket := t.tx.Bucket(bucketName)if err := bucket.Put(key, value); err != nil {plog.Fatalf("cannot put key into bucket (%v)", err)}t.pending++}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L144-169func (t *batchTx) UnsafeDelete(bucketName []byte, key []byte) {bucket := t.tx.Bucket(bucketName)err := bucket.Delete(key)if err != nil {plog.Fatalf("cannot delete key from bucket (%v)", err)}t.pending++}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L184-188func (t *batchTx) Commit() {t.Lock()t.commit(false)t.Unlock()}// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/backend/batch_tx.go#L210-241func (t *batchTx) commit(stop bool) {if t.tx != nil {if t.pending == 0 && !stop {return}start := time.Now()err := t.tx.Commit()rebalanceSec.Observe(t.tx.Stats().RebalanceTime.Seconds())spillSec.Observe(t.tx.Stats().SpillTime.Seconds())writeSec.Observe(t.tx.Stats().WriteTime.Seconds())commitSec.Observe(time.Since(start).Seconds())atomic.AddInt64(&t.backend.commits, 1)t.pending = 0}if !stop {t.tx = t.backend.begin(true)}}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/index.go#L68-76func (ti *treeIndex) Get(key []byte, atRev int64) (modified, created revision, ver int64, err error) {keyi := &keyIndex{key: key}if keyi = ti.keyIndex(keyi); keyi == nil {return revision{}, revision{}, 0, ErrRevisionNotFound}return keyi.get(ti.lg, atRev)}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/index.go#L84-89func (ti *treeIndex) keyIndex(keyi *keyIndex) *keyIndex {if item := ti.tree.Get(keyi); item != nil {return item.(*keyIndex)}return nil}
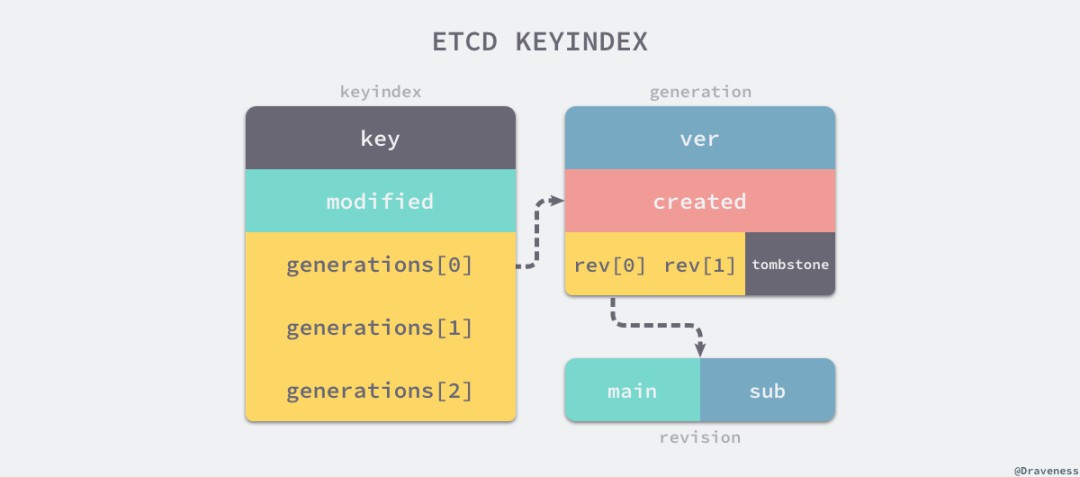
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/key_index.go#L149-171func (ki *keyIndex) get(lg *zap.Logger, atRev int64) (modified, created revision, ver int64, err error) {g := ki.findGeneration(atRev)if g.isEmpty() {return revision{}, revision{}, 0, ErrRevisionNotFound}n := g.walk(func(rev revision) bool { return rev.main > atRev })if n != -1 {return g.revs[n], g.created, g.ver - int64(len(g.revs)-n-1), nil}return revision{}, revision{}, 0, ErrRevisionNotFound}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/key_index.go#L127-145func (ki *keyIndex) tombstone(lg *zap.Logger, main int64, sub int64) error {if ki.generations[len(ki.generations)-1].isEmpty() {return ErrRevisionNotFound}ki.put(lg, main, sub)ki.generations = append(ki.generations, generation{})return nil}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore_txn.go#L112-165func (tr *storeTxnRead) rangeKeys(key, end []byte, curRev int64, ro RangeOptions) (*RangeResult, error) {rev := ro.Revrevpairs := tr.s.kvindex.Revisions(key, end, rev)if len(revpairs) == 0 {return &RangeResult{KVs: nil, Count: 0, Rev: curRev}, nil}kvs := make([]mvccpb.KeyValue, int(ro.Limit))revBytes := newRevBytes()for i, revpair := range revpairs[:len(kvs)] {revToBytes(revpair, revBytes)_, vs := tr.tx.UnsafeRange(keyBucketName, revBytes, nil, 0)kvs[i].Unmarshal(vs[0])}return &RangeResult{KVs: kvs, Count: len(revpairs), Rev: curRev}, nil}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/index.go#L106-120func (ti *treeIndex) Revisions(key, end []byte, atRev int64) (revs []revision) {if end == nil {rev, _, _, err := ti.Get(key, atRev)if err != nil {return nil}return []revision{rev}}ti.visit(key, end, func(ki *keyIndex) {if rev, _, _, err := ki.get(ti.lg, atRev); err == nil {revs = append(revs, rev)}})return revs}
func (ki *keyIndex) get(lg *zap.Logger, atRev int64) (modified, created revision, ver int64, err error) {g := ki.findGeneration(atRev)if g.isEmpty() {return revision{}, revision{}, 0, ErrRevisionNotFound}n := g.walk(func(rev revision) bool { return rev.main > atRev })if n != -1 {return g.revs[n], g.created, g.ver - int64(len(g.revs)-n-1), nil}return revision{}, revision{}, 0, ErrRevisionNotFound}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/index.go#L53-66func (ti *treeIndex) Put(key []byte, rev revision) {keyi := &keyIndex{key: key}item := ti.tree.Get(keyi)if item == nil {keyi.put(ti.lg, rev.main, rev.sub)ti.tree.ReplaceOrInsert(keyi)return}okeyi := item.(*keyIndex)okeyi.put(ti.lg, rev.main, rev.sub)}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/key_index.go#L77-104func (ki *keyIndex) put(lg *zap.Logger, main int64, sub int64) {rev := revision{main: main, sub: sub}if len(ki.generations) == 0 {ki.generations = append(ki.generations, generation{})}g := &ki.generations[len(ki.generations)-1]if len(g.revs) == 0 {g.created = rev}g.revs = append(g.revs, rev)g.ver++ki.modified = rev}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore_txn.go#L252-309func (tw *storeTxnWrite) delete(key []byte) {ibytes := newRevBytes()idxRev := revision{main: tw.beginRev + 1, sub: int64(len(tw.changes))}revToBytes(idxRev, ibytes)ibytes = appendMarkTombstone(tw.storeTxnRead.s.lg, ibytes)kv := mvccpb.KeyValue{Key: key}d, _ := kv.Marshal()tw.tx.UnsafeSeqPut(keyBucketName, ibytes, d)tw.s.kvindex.Tombstone(key, idxRev)tw.changes = append(tw.changes, kv)}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore.go#L321-433func (s *store) restore() error {min, max := newRevBytes(), newRevBytes()revToBytes(revision{main: 1}, min)revToBytes(revision{main: math.MaxInt64, sub: math.MaxInt64}, max)tx := s.b.BatchTx()rkvc, revc := restoreIntoIndex(s.lg, s.kvindex)for {keys, vals := tx.UnsafeRange(keyBucketName, min, max, int64(restoreChunkKeys))if len(keys) == 0 {break}restoreChunk(s.lg, rkvc, keys, vals, keyToLease)newMin := bytesToRev(keys[len(keys)-1][:revBytesLen])newMin.sub++revToBytes(newMin, min)}close(rkvc)s.currentRev = revcreturn nil}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore.go#L486-506func restoreChunk(lg *zap.Logger, kvc chan revKeyValue, keys, vals [][]byte, keyToLease map[string]lease.LeaseID) {for i, key := range keys {rkv := r evKeyValue{key: key}_ := rkv.kv.Unmarshal(vals[i])rkv.kstr = string(rkv.kv.Key)if isTombstone(key) {delete(keyToLease, rkv.kstr)} else if lid := lease.LeaseID(rkv.kv.Lease); lid != lease.NoLease {keyToLease[rkv.kstr] = lid} else {delete(keyToLease, rkv.kstr)}kvc rkv}}
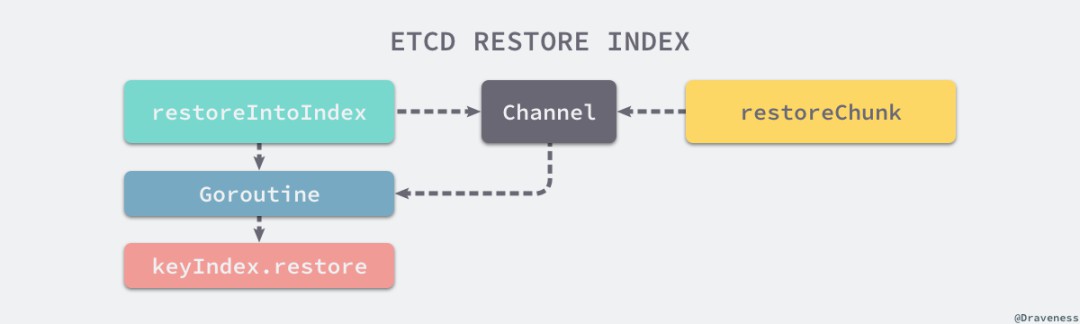
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore.go#L441-484func restoreIntoIndex(lg *zap.Logger, idx index) (chan revKeyValue, chan int64) {rkvc, revc := make(chan revKeyValue, restoreChunkKeys), make(chan int64, 1)go func() {currentRev := int64(1)defer func() { revc currentRev }()for rkv := range rkvc {ki = &keyIndex{key: rkv.kv.Key}ki := idx.KeyIndex(ki)rev := bytesToRev(rkv.key)currentRev = rev.mainif ok {if isTombstone(rkv.key) {ki.tombstone(lg, rev.main, rev.sub)continue}ki.put(lg, rev.main, rev.sub)} else if !isTombstone(rkv.key) {ki.restore(lg, revision{rkv.kv.CreateRevision, 0}, rev, rkv.kv.Version)idx.Insert(ki)}}}()return rkvc, revc}
恢復記憶體索引的相關程式碼在實現上非常值得學習,兩個不同的函式透過 Channel 進行通訊並使用 goroutine 處理任務,能夠很好地將訊息的『生產者』和『消費者』進行分離。
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kv.go#L100-125type KV interface {ReadViewWriteViewRead() TxnReadWrite() TxnWriteHash() (hash uint32, revision int64, err error)HashByRev(rev int64) (hash uint32, revision int64, compactRev int64, err error)Compact(rev int64) (chan struct{}, error)Commit()Restore(b backend.Backend) errorClose() error}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/kvstore_txn.go#L32-40func (s *store) Read() TxnRead {s.mu.RLock()tx := s.b.ReadTx()s.revMu.RLock()tx.Lock()firstRev, rev := s.compactMainRev, s.currentRevs.revMu.RUnlock()return newMetricsTxnRead(&storeTxnRead{s, tx, firstRev, rev})}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/watchable_store.go#L45-65type watchableStore struct {*storemu sync.RWMutexunsynced watcherGroupsynced watcherGroupstopc chan struct{}wg sync.WaitGroup}
func (s *watchableStore) syncWatchers() int {curRev := s.store.currentRevcompactionRev := s.store.compactMainRevwg, minRev := s.unsynced.choose(maxWatchersPerSync, curRev, compactionRev)minBytes, maxBytes := newRevBytes(), newRevBytes()revToBytes(revision{main: minRev}, minBytes)revToBytes(revision{main: curRev + 1}, maxBytes)tx := s.store.b.ReadTx()revs, vs := tx.UnsafeRange(keyBucketName, minBytes, maxBytes, 0)evs := kvsToEvents(nil, wg, revs, vs)wb := newWatcherBatch(wg, evs)for w := range wg.watchers {w.minRev = curRev + 1eb, ok := wb[w]if !ok {s.synced.add(w)s.unsynced.delete(w)continue}w.send(WatchResponse{WatchID: w.id, Events: eb.evs, Revision: curRev})s.synced.add(w)s.unsynced.delete(w)}return s.unsynced.size()}
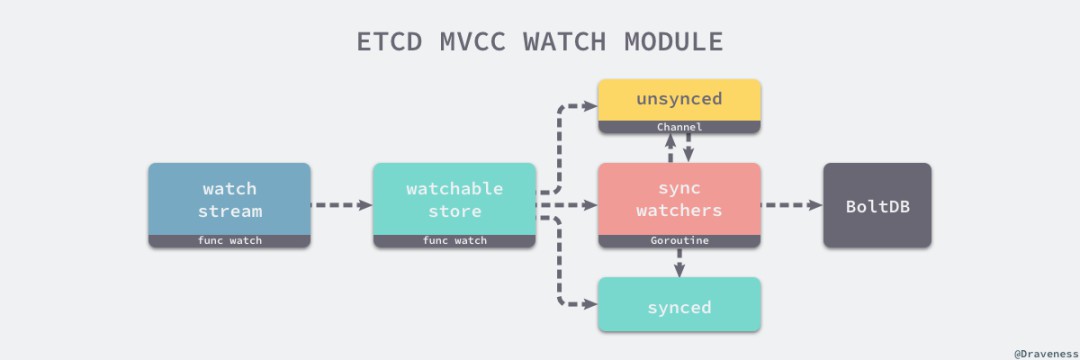
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/watcher.go#L108-135func (ws *watchStream) Watch(id WatchID, key, end []byte, startRev int64, fcs ...FilterFunc) (WatchID, error) {if id == AutoWatchID {for ws.watchers[ws.nextID] != nil {ws.nextID++}id = ws.nextIDws.nextID++}w, c := ws.watchable.watch(key, end, startRev, id, ws.ch, fcs...)ws.cancels[id] = cws.watchers[id] = wreturn id, nil}// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/mvcc/watchable_store.go#L111-142func (s *watchableStore) watch(key, end []byte, startRev int64, id WatchID, ch chan WatchResponse, fcs ...FilterFunc) (*watcher, cancelFunc) {wa := &watcher{key: key,end: end,minRev: startRev,id: id,ch: ch,fcs: fcs,}synced := startRev > s.store.currentRev || startRev == 0if synced {s.synced.add(wa)} else {s.unsynced.add(wa)}return wa, func() { s.cancelWatcher(wa) }}
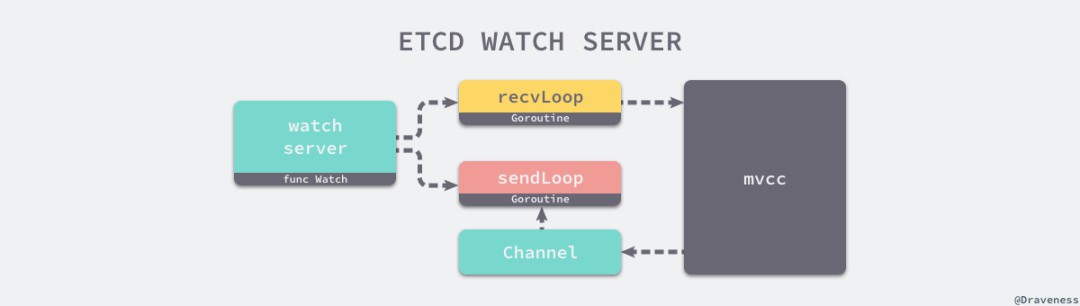
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/etcdserver/api/v3rpc/watch.go#L136-206func (ws *watchServer) Watch(stream pb.Watch_WatchServer) (err error) {sws := serverWatchStream{// ...gRPCStream: stream,watchStream: ws.watchable.NewWatchStream(),ctrlStream: make(chan *pb.WatchResponse, ctrlStreamBufLen),}sws.wg.Add(1)go func() {sws.sendLoop()sws.wg.Done()}()go func() {sws.recvLoop()}()sws.wg.Wait()return err}
// https://sourcegraph.com/github.com/etcd-io/etcd@1cab49e/-/blob/etcdserver/api/v3rpc/watch.go#L220-334func (sws *serverWatchStream) recvLoop() error {for {req, err := sws.gRPCStream.Recv()if err == io.EOF {return nil}if err != nil {return err}switch uv := req.RequestUnion.(type) {case *pb.WatchRequest_CreateRequest:creq := uv.CreateRequestfilters := FiltersFromRequest(creq)wsrev := sws.watchStream.Rev()rev := creq.StartRevisionid, _ := sws.watchStream.Watch(mvcc.WatchID(creq.WatchId), creq.Key, creq.RangeEnd, rev, filters...)wr := &pb.WatchResponse{Header: sws.newResponseHeader(wsrev),WatchId: int64(id),Created: true,Canceled: err != nil,}select {case sws.ctrlStream wr:case sws.closec:return nil}case *pb.WatchRequest_CancelRequest: // ...case *pb.WatchRequest_ProgressRequest: // ...default:continue}}}
func (sws *serverWatchStream) sendLoop() {for {select {case wresp, ok := sws.watchStream.Chan():evs := wresp.Eventsevents := make([]*mvccpb.Event, len(evs))for i := range evs {events[i] = &evs[i] }canceled := wresp.CompactRevision != 0wr := &pb.WatchResponse{Header: sws.newResponseHeader(wresp.Revision),WatchId: int64(wresp.WatchID),Events: events,CompactRevision: wresp.CompactRevision,Canceled: canceled,}sws.gRPCStream.Send(wr)case c, ok := sws.ctrlStream: // ...case progressTicker.C: // ...case sws.closec:return}}}