百度推出飛槳(PaddlePaddle)後,不少開發者開始轉向國內的深度學習框架。但是從程式碼的轉移談何容易,之前的工作重寫一遍不太現實,成千上萬行程式碼的手工轉換等於是在做一次二次開發。
現在,有個好訊息:無論Caffe、TensorFlow、ONNX都可以輕鬆遷移到飛槳平臺上。雖然目前還不直接遷移PyTorch模型,但PyTorch本身支援匯出為ONNX模型,等於間接對該平臺提供了支援。
然而,有人還對存在疑惑:不同框架之間的API有沒有差異?整個遷移過程如何操作,步驟複雜嗎?遷移後如何保證精度的損失在可接受的範圍內?
大家會考慮很多問題,而問題再多,歸納一下,無外乎以下幾點:
API差異:模型的實現方式如何遷移,不同框架之間的API有沒有差異?如何避免這些差異帶來的模型效果的差異?
模型檔案差異:訓練好的模型檔案如何遷移?轉換框架後如何保證精度的損失在可接受的範圍內?
預測方式差異:轉換後的模型如何預測?預測的效果與轉換前的模型差異如何?
飛槳開發了一個新的功能模組,叫X2Paddle(Github見參考1),可以支援主流深度學習框架模型轉換至飛槳,包括Caffe、Tensorflow、onnx等模型直接轉換為Paddle Fluid可載入的預測模型,並且還提供了這三大主流框架間的API差異比較,方便我們在自己直接復現模型時對比API之間的差異,深入理解API的實現方式從而降低模型遷移帶來的損失。
下麵以TensorFlow轉換成Paddle Fluid模型為例,詳細講講如何實現模型的遷移。
TensorFlow-Fluid的API差異
在深度學習入門過程中,大家常見的就是手寫數字識別這個demo,下麵是一份最簡單的實現手寫數字識別的程式碼:
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder("float", [None, 10])
cross_entropy = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits = y,labels = y_))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(1, 1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
大家看這段程式碼裡,第一步是匯入mnist資料集,然後設定了一個佔位符x來表示輸入的圖片資料,再設定兩個變數w和b,分別表示權重和偏置來計算,最後透過softmax計算得到輸出的y值,而我們真實的label則是變數y_。
前向傳播完成後,就可以計算預測值y與label y_之間的交叉熵。
再選擇合適的最佳化函式,此處為梯度下降,最後啟動一個Session,把資料按batch灌進去,計算acc即可得到準確率。
這是一段非常簡單的程式碼,如果我們想把這段程式碼變成飛槳的程式碼,有人可能會認為非常麻煩,每一個實現的API還要一一去找對應的實現方式,但是這裡,我可以告訴大家,不!用!這!麼!麻!煩!
因為在X2Paddle裡有一份常用的Tensorflow對應Fluid的API表:
https://github.com/PaddlePaddle/X2Paddle/tree/master/tensorflow2fluid/doc
對於常用的TensorFlow的API,都有相應的飛槳介面,如果兩者的功能沒有差異,則會標註功能一致,如果實現方式或者支援的功能、引數等有差異,即會標註“差異對比”,並詳細註明。
譬如,在上文這份非常簡單的程式碼裡,出現了這些TensorFlow的API:
在出現的這些api裡,大部分的功能都是一致的,只有兩個功能不同,分別是tf.placeholder和tf.nn.softmax_cross_entropy_with_logits ,分別對應 fluid.layers.data 和 fluid.layers.softmax_with_cross_entropy . 我們來看看具體差異:
tf.placeholder V.S fluid.layers.data
常用TensorFlow的同學對placeholder應該不陌生,中文翻譯為佔位符,什麼意思呢?在TensorFlow 2.0以前,還是靜態圖的設計思想,整個設計理念是計算流圖,在編寫程式時,首先構築整個系統的graph,程式碼並不會直接生效,這一點和python的其他數值計算庫(如Numpy等)不同,graph為靜態的,在實際的執行時,啟動一個session,程式才會真正的執行。這樣做的好處就是:避免反覆地切換底層程式實際執行的背景關係,tensorflow幫你最佳化整個系統的程式碼。我們知道,很多python程式的底層為C語言或者其他語言,執行一行指令碼,就要切換一次,是有成本的,tensorflow透過計算流圖的方式,可以幫你最佳化整個session需要執行的程式碼。
在程式碼層面,每一個tensor值在graph上都是一個op,當我們將train資料分成一個個minibatch然後傳入網路進行訓練時,每一個minibatch都將是一個op,這樣的話,一副graph上的op未免太多,也會產生巨大的開銷;於是就有了tf.placeholder,我們每次可以將 一個minibatch傳入到x = tf.placeholder(tf.float32,[None,32])上,下一次傳入的x都替換掉上一次傳入的x,這樣就對於所有傳入的minibatch x就只會產生一個op,不會產生其他多餘的op,進而減少了graph的開銷。
引數對比
tf.placeholder
tf.placeholder(
dtype,
shape=None,
name=None
)
paddle.fluid.layers.data
paddle.fluid.layers.data(
name,
shape,
append_batch_size=True,
dtype='float32',
lod_level=0,
type=VarType.LOD_TENSOR,
stop_gradient=True)從圖中可以看到,飛槳的api引數更多,具體差異如下:
Batch維度處理
TensorFlow: 對於shape中的batch維度,需要使用者使用None指定;
飛槳: 將第1維設定為-1表示batch維度;如若第1維為正數,則會預設在最前面插入batch維度,如若要避免batch維,可將引數append_batch_size設為False。
梯度是否回傳
tensorflow和pytorch都支援對輸入求梯度,在飛槳中直接設定stop_gradient = False即可。如果在某一層使用stop_gradient=True,那麼這一層之前的層都會自動的stop_gradient=True,梯度不會參與回傳,可以對某些不需要參與loss計算的資訊設定為stop_gradient=True。對於含有BatchNormalization層的CNN網路,也可以對輸入求梯度,如:
layers.data(
name="data",
shape=[32, 3, 224, 224],
dtype="int64",
append_batch_size=False,
stop_gradient=False)tf.nn.softmax_cross_entropy_with_logits V.S fluid.layers.softmax_with_cross_entropy
引數對比
tf.nn.softmax_cross_entropy_with_logits(
_sentinel=None,
labels=None,
logits=None,
dim=-1,
name=None
)
paddle.fluid.layers.softmax_with_cross_entropy
paddle.fluid.layers.softmax_with_cross_entropy(
logits,
label,
soft_label=False,
ignore_index=-100,
numeric_stable_mode=False,
return_softmax=False
)
功能差異
標簽型別
TensorFlow:labels只能使用軟標簽,其shape為[batch, num_classes],表示樣本在各個類別上的機率分佈;
飛槳:透過設定soft_label,可以選擇軟標簽或者硬標簽。當使用硬標簽時,label的shape為[batch, 1],dtype為int64;當使用軟標簽時,其shape為[batch, num_classes],dtype為int64。
傳回值
TensorFlow:傳回batch中各個樣本的log loss;
飛槳:當return_softmax為False時,傳回batch中各個樣本的log loss;當return_softmax為True時,再額外傳回logtis的歸一化值。
疑問點?
硬標簽,即 one-hot label, 每個樣本僅可分到一個類別
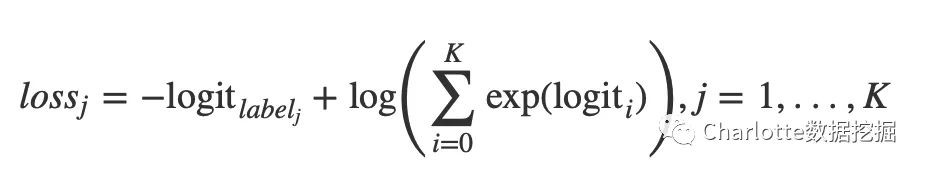
軟標簽,每個樣本可能被分配至多個類別中
numeric_stable_mode:這個引數是什麼呢?標誌位,指明是否使用一個具有更佳數學穩定性的演演算法。僅在 soft_label 為 False的GPU樣式下生效. 若 soft_label 為 True 或者執行場所為CPU, 演演算法一直具有數學穩定性。註意使用穩定演演算法時速度可能會變慢。預設為 True。
return_softmax: 指明是否額外傳回一個softmax值, 同時傳回交叉熵計算結果。預設為False。
如果 return_softmax 為 False, 則傳回交叉熵損失
如果 return_softmax 為 True,則傳回元組 (loss, softmax) ,其中交叉熵損失為形為[N x 1]的二維張量,softmax為[N x K]的二維張量
程式碼示例
data = fluid.layers.data(name='data', shape=[128], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
fc = fluid.layers.fc(input=data, size=100)
out = fluid.layers.softmax_with_cross_entropy(
logits=fc, label=label)
所以透過API對應表,我們可以直接轉換把TensorFlow程式碼轉換成Paddle Fluid程式碼。但是如果現在專案已經上線了,程式碼幾千行甚至上萬行,或者已經訓練出可預測的模型了,如果想要直接轉換API是一件非常耗時耗精力的事情,有沒有一種方法可以直接把訓練好的可預測模型直接轉換成另一種框架寫的,只要轉換後的損失精度在可接受的範圍內,就可以直接替換。下麵就講講訓練好的模型如何遷移。
模型遷移
VGG_16是CV領域的一個經典模型,我以tensorflow/models下的VGG_16為例,給大家展示如何將TensorFlow訓練好的模型轉換為飛槳模型。
下載預訓練模型
import urllib
import sys
def schedule(a, b, c):
per = 100.0 * a * b / c
per = int(per)
sys.stderr.write("\rDownload percentage %.2f%%" % per)
sys.stderr.flush()
url = "http://download.tensorflow.org/models/vgg_16_2016_08_28.tar.gz"
fetch = urllib.urlretrieve(url, "./vgg_16.tar.gz", schedule)
解壓下載的壓縮檔案
import tarfile
with tarfile.open("./vgg_16.tar.gz", "r:gz") as f:
file_names = f.getnames()
for file_name in file_names:
f.extract(file_name, "./")
儲存模型為checkpoint格式
import tensorflow.contrib.slim as slim
from tensorflow.contrib.slim.nets import vgg
import tensorflow as tf
import numpy
with tf.Session() as sess:
inputs = tf.placeholder(dtype=tf.float32, shape=[None, 224, 224, 3], name="inputs")
logits, endpoint = vgg.vgg_16(inputs, num_classes=1000, is_training=False)
load_model = slim.assign_from_checkpoint_fn("vgg_16.ckpt", slim.get_model_variables("vgg_16"))
load_model(sess)
numpy.random.seed(13)
data = numpy.random.rand(5, 224, 224, 3)
input_tensor = sess.graph.get_tensor_by_name("inputs:0")
output_tensor = sess.graph.get_tensor_by_name("vgg_16/fc8/squeezed:0")
result = sess.run([output_tensor], {input_tensor:data})
numpy.save("tensorflow.npy", numpy.array(result))
saver = tf.train.Saver()
saver.save(sess, "./checkpoint/model")TensorFlow2fluid目前支援checkpoint格式的模型或者是將網路結構和引數序列化的pb格式模型,上面下載的vgg_16.ckpt僅僅儲存了模型引數,因此我們需要重新載入引數,並將網路結構和引數一起儲存為checkpoint模型
將模型轉換為飛槳模型
import tf2fluid.convert as convert
import argparse
parser = convert._get_parser()
parser.meta_file = "checkpoint/model.meta"
parser.ckpt_dir = "checkpoint"
parser.in_nodes = ["inputs"]
parser.input_shape = ["None,224,224,3"]
parser.output_nodes = ["vgg_16/fc8/squeezed"]
parser.use_cuda = "True"
parser.input_format = "NHWC"
parser.save_dir = "paddle_model"
convert.run(parser)
註意:部分OP在轉換時,需要將引數寫入檔案;或者是執行tensorflow模型進行infer,獲取tensor值。兩種情況下均會消耗一定的時間用於IO或計算,對於後一種情況,
列印輸出log資訊(擷取部分)
INFO:root:Loading tensorflow model...
INFO:tensorflow:Restoring parameters from checkpoint/model
INFO:tensorflow:Restoring parameters from checkpoint/model
INFO:root:Tensorflow model loaded!
INFO:root:TotalNum:86,TraslatedNum:1,CurrentNode:inputs
INFO:root:TotalNum:86,TraslatedNum:2,CurrentNode:vgg_16/conv1/conv1_1/weights
INFO:root:TotalNum:86,TraslatedNum:3,CurrentNode:vgg_16/conv1/conv1_1/biases
INFO:root:TotalNum:86,TraslatedNum:4,CurrentNode:vgg_16/conv1/conv1_2/weights
INFO:root:TotalNum:86,TraslatedNum:5,CurrentNode:vgg_16/conv1/conv1_2/biases
...
INFO:root:TotalNum:86,TraslatedNum:10,CurrentNode:vgg_16/conv3/conv3_1/weights
INFO:root:TotalNum:86,TraslatedNum:11,CurrentNode:vgg_16/conv3/conv3_1/biases
INFO:root:TotalNum:86,TraslatedNum:12,CurrentNode:vgg_16/conv3/conv3_2/weights
INFO:root:TotalNum:86,TraslatedNum:13,CurrentNode:vgg_16/conv3/conv3_2/biases
INFO:root:TotalNum:86,TraslatedNum:85,CurrentNode:vgg_16/fc8/BiasAdd
INFO:root:TotalNum:86,TraslatedNum:86,CurrentNode:vgg_16/fc8/squeezed
INFO:root:Model translated!
到這一步,我們已經把tensorflow/models下的vgg16模型轉換成了Paddle Fluid 模型,轉換後的模型與原模型的精度有損失嗎?如何預測呢?來看下麵。
預測結果差異
載入轉換後的飛槳模型,併進行預測
上一步轉換後的模型目錄命名為“paddle_model”,在這裡我們透過ml.ModelLoader把模型載入進來,註意轉換後的飛槳模型的輸出格式由NHWC轉換為NCHW,所以我們需要對輸入資料做一個轉置。處理好資料後,即可透過model.inference來進行預測了。具體程式碼如下:
import numpy
import tf2fluid.model_loader as ml
model = ml.ModelLoader("paddle_model", use_cuda=False)
numpy.random.seed(13)
data = numpy.random.rand(5, 224, 224, 3).astype("float32")
# NHWC -> NCHW
data = numpy.transpose(data, (0, 3, 1, 2))
results = model.inference(feed_dict={model.inputs[0]:data})
numpy.save("paddle.npy", numpy.array(results))
對比模型損失
轉換模型有一個問題始終避免不了,就是損失,從Tesorflow的模型轉換為Paddle Fluid模型,如果模型的精度損失過大,那麼轉換模型實際上是沒有意義的,只有損失的精度在我們可接受的範圍內,模型轉換才能被實際應用。在這裡可以透過把兩個模型檔案載入進來後,透過numpy.fabs來求兩個模型結果的差異。
import numpy
paddle_result = numpy.load("paddle.npy")
tensorflow_result = numpy.load("tensorflow.npy")
diff = numpy.fabs(paddle_result - tensorflow_result)
print(numpy.max(diff))
列印輸出
6.67572e-06
從結果中可以看到,兩個模型檔案的差異很小,為6.67572e-06 ,幾乎可以忽略不計,所以這次轉換的模型是可以直接應用的。
需要註意的點
1. 轉換後的模型需要註意輸入格式,飛槳中輸入格式需為NCHW格式。此例中不涉及到輸入中間層,如摺積層的輸出,需要瞭解的是飛槳中的摺積層輸出,摺積核的shape與TensorFlow有差異。
2. 模型轉換完後,檢查轉換前後模型的diff,需要測試得到的最大diff是否滿足轉換需求。
總結
X2Paddle提供了一個非常方便的轉換方式,讓大家可以直接將訓練好的模型轉換成Paddle Fluid版本。
轉換模型原先需要直接透過API對照表來重新實現程式碼。但是在實際生產過程中這麼操作是很麻煩的,甚至還要進行二次開發。
如果有新的框架能輕鬆轉換模型,迅速執行除錯,迭代出結果,何樂而不為呢?
雖然飛槳相比其他AI平臺上線較晚,但是憑藉X2Paddle小工具,能快速將AI開發者吸引到自己的平臺上來,後續的優勢將愈加明顯。
除了本文提到的tensoflow2fluid,Paddle Fluid還支援caffe2fluid、onnx2fluid,大家可以根據自身的需求體驗一下,有問題可以留言交流~
參考資料
X2Paddle Github: https://github.com/PaddlePaddle/X2Paddle
tensorflow2fluid: https://github.com/PaddlePaddle/X2Paddle/tree/master/tensorflow2fluid
朋友會在“發現-看一看”看到你“在看”的內容