作者丨薛潔婷
學校丨北京交通大學碩士生
研究方向丨影象翻譯


研究動機
近年來關於影象翻譯的研究越來越多,其中比較經典的有監督模型包括 Pix2Pix, BicycleGAN 等,無監督模型包括 CycleGAN, MUNIT, StarGAN, DRIT 等。
由於這些模型無論是針對多領域翻譯還是單領域翻譯都是將標的域影象的風格/屬性整個遷移到源域影象上,因此雖然這些方法可以很好的解決風格統一或者內容相關的影象翻譯問題,但對於有大量實體物體並且物體與背景之間的風格差異非常巨大的複雜結構影象翻譯來說是很困難的。
為瞭解決該問題,作者基於 MUNIT 模型提出了基於端到端的訓練模型 INIT,其採用不同的風格編碼來獨立的翻譯影象中的物體、背景以及全域性區域。
▲ 圖1. 現有影象翻譯模型的侷限
模型架構
INIT 的網路架構非常類似於 MUNIT 模型,但不同於 MUNIT 模型,作者提出的模型不僅對全域性影象進行內容和屬性編碼,而且還對實體物體以及背景也進行內容-屬性編碼。即首先給定一對未對齊的影象和實體物體的坐標位置,應用全域性編碼器 Eg 以及區域性編碼器 Eo 分別獲取全域性影象和實體物體影象內容 c 和屬性向量 s,然後透過交換屬性向量來獲取跨域的標的實體物件影象,整個模型的架構如下圖所示。
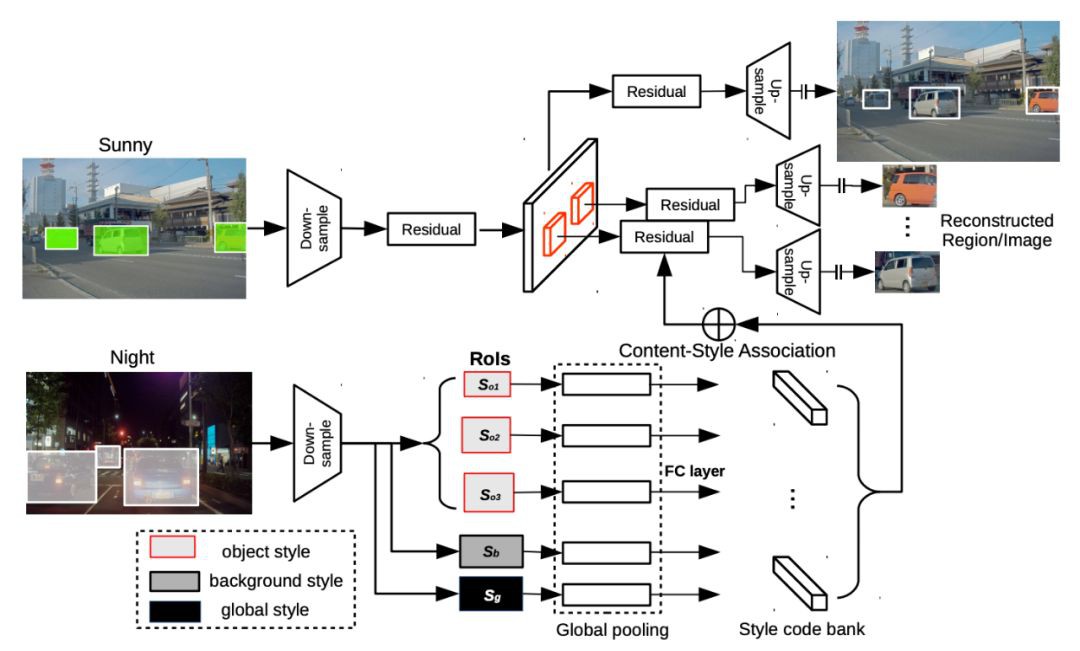
▲ 圖2. INIT模型網路結構
另外作者修改了原始的迴圈重建過程使其不僅包括跨域(X 域->Y 域)樣式重建還包括了跨粒度級(實體物體->全域性影象)樣式重建。對於跨域來說是完全基於 MUNIT 模型所提出的迴圈重建,針對跨粒度級的重建過程如圖 3 所示,作者透過交換影象和實體物體的編碼-解碼對後生成影象,再對生成影象繼續重覆上一操作使得再次生成出的影象和實體物體應和原始影象以及實體物體一致。

▲ 圖3. 迴圈一致性損失(僅針對跨粒度級)
對於交換粒度級內容-屬性編碼對需要註意的是,作者採用了從粗略(全域性)屬性向量去結合細粒度級內容向量的交換方式,而如果逆轉這一過程即利用細粒度的屬性向量去結合粗粒度級的內容向量則無法實現(如圖 4 所示)。

▲ 圖4. 內容-屬性對交換策略
綜上所述,模型採用的損失包括重構損失以及對抗損失,重構損失包括了全域性影象重構以及區域性實體物體重構,這兩類的重構中又包括了影象重建損失、內容重建損失以風格重建損失。對抗損失也包括了全域性對抗損失以及區域性實體對抗損失,整個模型的損失函式如下。

實驗結果
作者的實驗主要採用了自己設計的 INIT 資料集以及 COCO 資料集,INIT 資料集是由作者設計並首次應用於影象翻譯問題,其中包含 155529 張高畫質街景影象並且不僅設計了 sunny, night, cloud, rain 四種域標簽而且還對詳細實體物件邊界框註釋(車,人以及交通標誌)。
作者使用 LPIPS 矩陣、Inception-Score 以及 Conditional Inception-Score 對 INIT 模型進行評估,並和 CycleGAN, UNIT, MUNIT, DRIT 進行比對,其中 INIT w/Ds 表示全域性影象和區域性實體物件共享一個鑒別器,INIT w/o Ds 則表示兩個鑒別器獨立,以下是實驗結果。


總結
作者基於 MUNIT 的架構提出了針對實體級影象翻譯技術,透過對提取實體物件的風格/屬性來直接影響和指導標的域該物體的生成,這使得在進行複雜結構圖象翻譯時能產生更細緻的結果。
從實驗的效果圖來看也能發現翻譯後的影象在具體實體物件上也能更符合現實場景。另外作者還設計了 INIT 街景資料集,該資料集包括了對具體實體物件的註釋框,有助於今後的影象翻譯問題研究。
朋友會在“發現-看一看”看到你“在看”的內容