Infiniband開放標準技術簡化並加速了伺服器之間的連線,同時支援伺服器與遠端儲存和網路裝置的連線。OpenFabrics Enterprise Distribution (OFED)是一組開源軟體驅動、核心核心程式碼、中介軟體和支援InfiniBand Fabric的使用者級介面程式。
2005年由OpenFabrics Alliance (OFA)釋出第一個版本。Mellanox OFED用於Linux,Windows (WinOF),包括各種診斷和效能工具,用於監視InfiniBand網路的執行情況,包括監視傳輸頻寬和監視Fabric內部的擁塞情況。
OpenFabrics Alliance (OFA)是一個基於開源的組織,它開發、測試、支援OpenFabrics企業發行版。該聯盟的任務是開發並推廣軟體,透過將高效訊息、低延遲和最大頻寬技術架構直接應用到最小CPU開銷的應用程式中,從而實現最大應用效率。
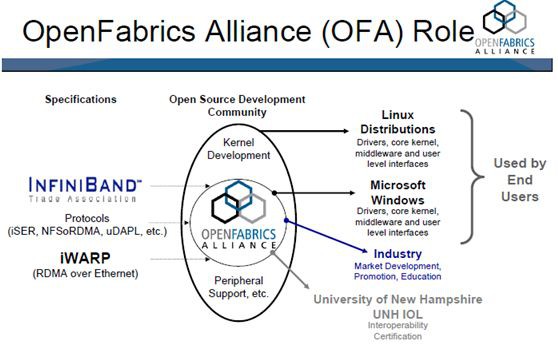
該聯盟成立於2004年6月,最初是OpenIB聯盟,致力於開發獨立於供應商、基於Linux的InfiniBand軟體棧。2005,聯盟致力於支援Windows,此舉將使軟體棧真正跨平臺。
2006年,該組織再次擴充套件其章程,包括對iWARP的支援,在2010年增加了對RoCE (RDMA over Converged)支援透過乙太網交付高效能RDMA和核心旁路解決方案。2014年,隨著OpenFabrics Interfaces工作組的建立,聯盟再次擴大,實現對其他高效能網路的支援
IB技術的發展
1999年開始起草規格及標準規範,2000年正式發表,但發展速度不及Rapid I/O、PCI-X、PCI-E和FC,加上Ethernet從1Gbps進展至10Gbps。所以直到2005年之後,InfiniBand Architecture(IBA)才在叢集式超級計算機上廣泛應用。全球HPC高算系統TOP500大效能的超級計算機中有相當多套系統都使用上IBA。
除了InfiniBand Trade Association (IBTA)9個主要董事成員CRAY、Emulex、HP、IBM、intel、Mellanox、Microsoft、Oracle、Qlogic專門在應用和推廣InfiniBand外,其他廠商正在加入或者重返到它的陣營中來,包括Cisco、Sun、NEC、LSI等。InfiniBand已經成為目前主流的高效能運算機互連技術之一。為了滿足HPC、企業資料中心和雲端計算環境中的高I/O吞吐需求,新一代高速率56Gbps的FDR (Fourteen Data Rate) 和100Gpb EDR InfiniBand技術已經廣泛應用。
IB技術的優勢
Infiniband大量用於FC/IP SAN、NAS和伺服器之間的連線,作為iSCSI RDMA的儲存協議iSER已被IETF標準化。目前EMC全系產品已經切換到Infiniband組網,IBM/TMS的FlashSystem系列,IBM的儲存系統XIV Gen3,DDN的SFA系列都採用Infiniband網路。
相比FC的優勢主要體現在效能是FC的3.5倍,Infiniband交換機的延遲是FC交換機的1/10,支援SAN和NAS。
儲存系統已不能滿足於傳統的FC SAN所提供的伺服器與裸儲存的網路連線架構。HP SFS和IBM GPFS 是在Infiniband fabric連線起來的伺服器和iSER Infiniband儲存構建的並行檔案系統,完全突破系統的效能瓶頸。
Infiniband採用PCI序列高速頻寬連結,從SDR、DDR、QDR、FDR到EDR HCA連線,可以做到1微妙、甚至奈米級別極低的時延,基於鏈路層的流控機制實現先進的擁塞控制。
InfiniBand採用虛通道(VL即Virtual Lanes)方式來實現QoS,虛通道是一些共享一條物理連結的相互分立的邏輯通訊鏈路,每條物理連結可支援多達15條的標準虛通道和一條管理通道(VL15)。
RDMA技術實現核心旁路,可以提供遠端節點間RDMA讀寫訪問,完全解除安裝CPU工作負載,基於硬體傳出協議實現可靠傳輸和更高效能。
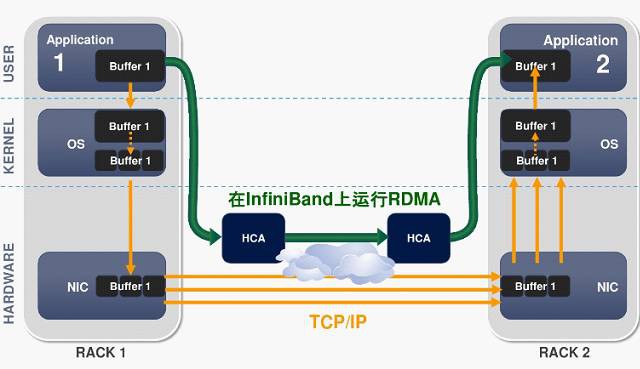
相比TCP/IP網路協議,IB使用基於信任的、流控制的機制來確保連線的完整性,資料包極少丟失,接受方在資料傳輸完畢之後,傳回信號來標示快取空間的可用性,所以IB協議消除了由於原資料包丟失而帶來的重發延遲,從而提升了效率和整體效能。
TCP/IP具有轉發損失的資料包的能力,但是由於要不斷地確認與重發,基於這些協議的通訊也會因此變慢,極大地影響了效能。
IB基本概念
IB是以通道為基礎的雙向、序列式傳輸,在連線拓樸中是採用交換、切換式結構(Switched Fabric),線上路不夠長時可用IBA中繼器(Repeater)進行延伸。每一個IBA網路稱為子網(Subnet),每個子網內最高可有65,536個節點(Node),IBA Switch、IBARepeater僅適用於Subnet範疇,若要通跨多個IBASubnet就需要用到IBA路由器(Router)或IBA閘道器器(Gateway)。
每個節點(Node) 必須透過配接器(Adapter)與IBA Subnet連線,節點CPU、記憶體要透過HCA(Host Channel Adapter)連線到子網;節點硬碟、I/O則要透過TCA(TargetChannel Adapter)連線到子網,這樣的一個拓撲結構就構成了一個完整的IBA。
IB的傳輸方式和介質相當靈活,在裝置機內可用印刷電路板的銅質線箔傳遞(Backplane背板),在機外可用銅質纜線或支援更遠光纖介質。若用銅箔、銅纜最遠可至17m,而光纖則可至10km,同時IBA也支援熱插拔,及具有自動偵測、自我調適的Active Cable活化智慧性連線機制。
IB協議簡介
InfiniBand也是一種分層協議(類似TCP/IP協議),每層負責不同的功能,下層為上層服務,不同層次相互獨立。 IB採用IPv6的報頭格式。其資料包報頭包括本地路由識別符號LRH,全域性路由標示符GRH,基本傳輸識別符號BTH等。
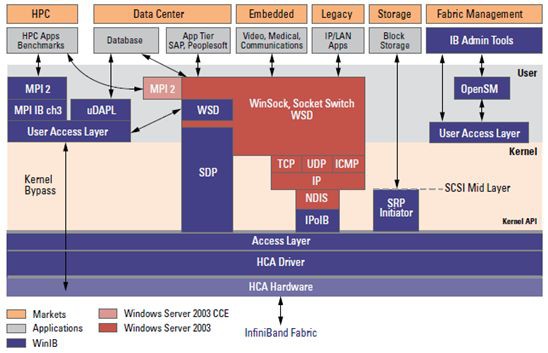
Mellanox OFED是一個單一的軟體堆疊,包括驅動、中介軟體、使用者介面,以及一系列的標準協議IPoIB、SDP、SRP、iSER、RDS、DAPL(Direct Access Programming Library),支援MPI、Lustre/NFS over RDMA等協議,並提供Verbs程式設計介面;Mellanox OFED由開源OpenFabrics組織維護。
當然,Mellanox OFED軟體堆疊是承載在InfiniBand硬體和協議之上的,軟體通協議和硬體進行有效的資料傳輸。
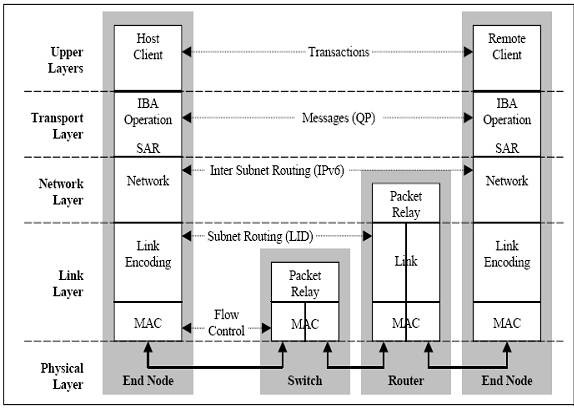
1、物理層
物理層定義了電氣特性和機械特性,包括光纖和銅媒介的電纜和插座、底板聯結器、熱交換特性等。定義了背板、電纜、光纜三種物理埠。
並定義了用於形成幀的符號(包的開始和結束)、資料符號(DataSymbols)、和資料包直接的填充(Idles)。詳細說明瞭構建有效包的信令協議,如碼元編碼、成幀標誌排列、開始和結束定界符間的無效或非資料符號、非奇偶性錯誤、同步方法等。
2、 鏈路層
鏈路層描述了資料包的格式和資料包操作的協議,如流量控制和子網內資料包的路由。鏈路層有鏈路管理資料包和資料包兩種型別的資料包。
3、 網路層
網路層是子網間轉發資料包的協議,類似於IP網路中的網路層。實現子網間的資料路由,資料在子網內傳輸時不需網路層的參與。
資料包中包含全域性路由頭GRH,用於子網間資料包路由轉發。全域性路由頭部指明瞭使用IPv6地址格式的全域性識別符號(GID)的源埠和目的埠,路由器基於GRH進行資料包轉發。GRH採用IPv6報頭格式。GID由每個子網唯一的子網 標示符和埠GUID捆綁而成。
4、 傳輸層
傳輸層負責報文的分發、通道多路復用、基本傳輸服務和處理報文分段的傳送、接收和重組。傳輸層的功能是將資料包傳送到各個指定的佇列(QP)中,並指示佇列如何處理該資料包。當訊息的資料路徑負載大於路徑的最大傳輸單元(MTU)時,傳輸層負責將訊息分割成多個資料包。
接收端的佇列負責將資料重組到指定的資料緩衝區中。除了原始資料報外,所有的資料包都包含BTH,BTH指定目的佇列並指明操作型別、資料包序列號和分割槽資訊。
5、上層協議
InfiniBand為不同型別的使用者提供了不同的上層協議,併為某些管理功能定義了訊息和協議。InfiniBand主要支援SDP、SRP、iSER、RDS、IPoIB和uDAPL等上層協議。
-
SDP(SocketsDirect Protocol)是InfiniBand Trade Association (IBTA)制定的基於infiniband的一種協議,它允許使用者已有的使用TCP/IP協議的程式執行在高速的infiniband之上。
-
SRP(SCSIRDMA Protocol)是InfiniBand中的一種通訊協議,在InfiniBand中將SCSI命令進行打包,允許SCSI命令透過RDMA(遠端直接記憶體訪問)在不同的系統之間進行通訊,實現儲存裝置共享和RDMA通訊服務。
-
iSER(iSCSIRDMA Protocol)類似於SRP(SCSI RDMA protocol)協議,是IB SAN的一種協議 ,其主要作用是把iSCSI協議的命令和資料透過RDMA的方式跑到例如Infiniband這種網路上,作為iSCSI RDMA的儲存協議iSER已被IETF所標準化。
-
RDS(Reliable Datagram Sockets)協議與UDP 類似,設計用於在Infiniband 上使用套接字來傳送和接收資料。實際是由Oracle公司研發的執行在infiniband之上,直接基於IPC的協議。
-
IPoIB(IP-over-IB)是為了實現INFINIBAND網路與TCP/IP網路相容而制定的協議,基於TCP/IP協議,對於使用者應用程式是透明的,並且可以提供更大的頻寬,也就是原先使用TCP/IP協議棧的應用不需要任何修改就能使用IPoIB。
-
uDAPL(UserDirect Access Programming Library)使用者直接訪問程式設計庫是標準的API,透過遠端直接記憶體訪問 RDMA功能的互連(如InfiniBand)來提高資料中心應用程式資料訊息傳送效能、伸縮性和可靠性。
IB基本應用場景
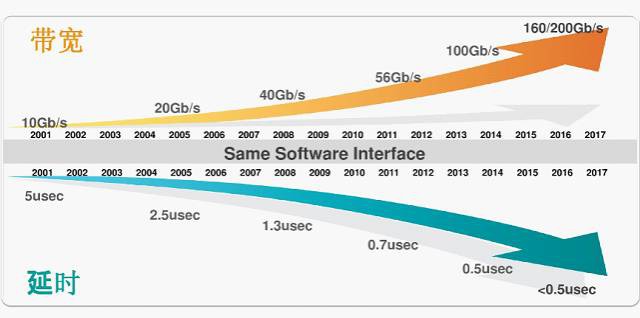
Infiniband靈活支援直連及交換機多種組網方式,主要用於HPC高效能運算場景,大型資料中心高效能儲存等場景,HPC應用的共同訴求是低時延(<10微秒)、低CPU佔有率(<10%)和高頻寬(主流56或100Gbps)
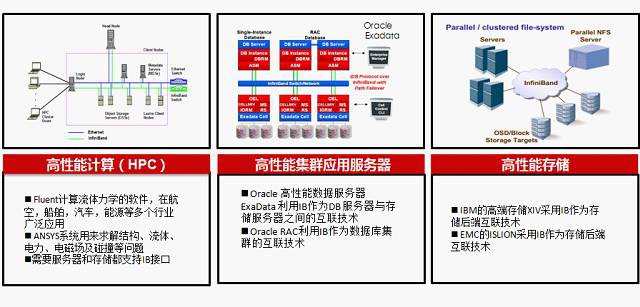
內容小結:一方面Infiniband在主機側採用RDMA技術釋放CPU負載,可以把主機內資料處理的時延從幾十微秒降低到1微秒;另一方面InfiniBand網路的高頻寬(40G、56G和100G)、低時延(幾百納秒)和無丟包特性吸取了FC網路的可靠性和乙太網的靈活擴充套件能力。
