自從看了師傅爬了頂點全站之後,我也手癢癢的,也想爬一個比較牛逼的小說網看看,於是選了宜搜這個網站,好了,馬上開乾,這次用的是mogodb資料庫,感覺mysql太麻煩了下圖是我選擇宜搜裡面遍歷的網站
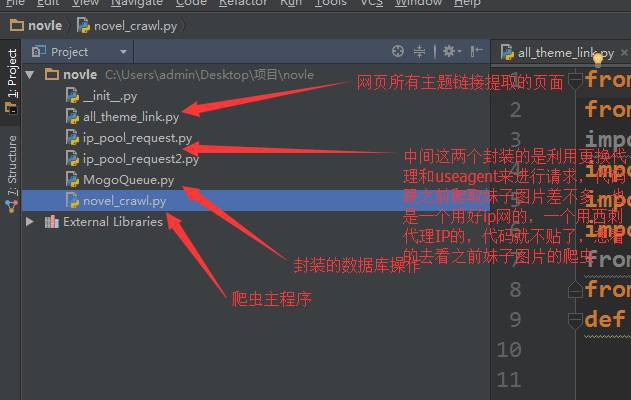
先看程式碼框架圖
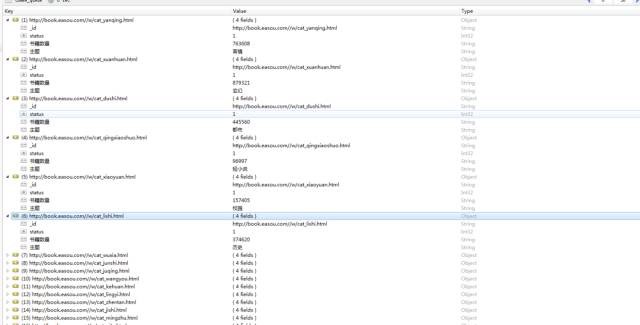
第一個,肯定先提取排行榜裡面每個類別的連結啊,然後進入連結進行爬取,先看all_theme檔案

看看執行結果,這是書籍類目的
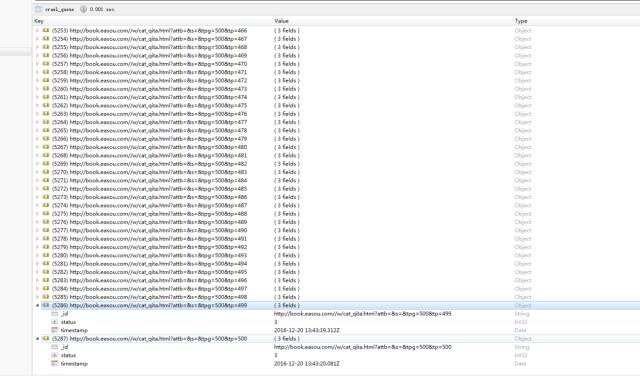
這是構造出的每一個類目裡面所有的頁數連結,也是我們爬蟲的入口,一共5000多頁
接下來是封裝的資料庫操作,因為用到了多行程以及多執行緒每個行程,他們需要知道那些URL爬取過了、哪些URL需要爬取!我們來給每個URL設定兩種狀態:
-
outstanding:等待爬取的URL
-
complete:爬取完成的URL
-
processing:正在進行的URL。
嗯!當一個所有初始的URL狀態都為outstanding;當開始爬取的時候狀態改為:processing;爬取完成狀態改為:complete;失敗的URL重置狀態為:outstanding。
為了能夠處理URL行程被終止的情況、我們設定一個計時引數,當超過這個值時;我們則將狀態重置為outstanding。

接下來是爬蟲主程式

讓我們來看看結果吧
裡面因為很多都是重覆的,所有去重之後只有十幾萬本,好失望……

