最開始公司運維同學反饋,個別宿主機上存在行程CPU峰值使用率異常的現象。而數萬臺機器中只出現了幾例,也就是說萬分之幾的機率。監控產生的些小誤差,不會造成宕機等嚴重後果,很容易就此被忽略了。
但我們考慮到這個異常轉瞬即逝、並不易被察覺,可能還存在更多這樣的機器,又或者現在正常將來又不正常,核心研發本能的好奇心讓我們感到:此事必有蹊蹺!於是追查下去。
現象一:CPU監控非0即100%
該問題現象表現在Redis行程CPU監控的峰值時而100% 時而為0,有的甚至是幾十分鐘都為0,突發1秒100%後又變為0,如下圖。
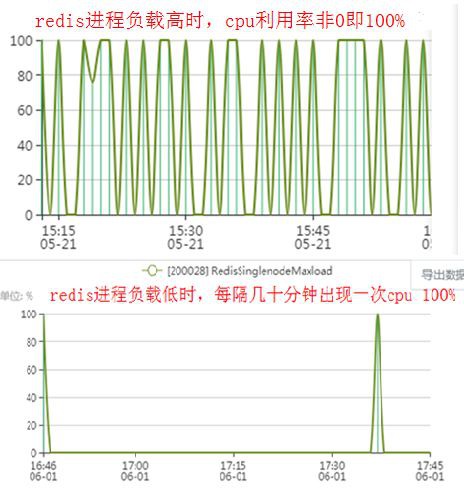
而從大量機器的統計規律看,這個現象在2.6.32 核心不存在,在4.1核心存在幾例。2.6.32是我們較早期採用的版本,為平臺的穩定發展做了有力支撐,4.1 可以滿足很多新技術需求,如新款CPU、新板卡、RDMA、NVMe和binlog2.0等。後臺無縫維護著兩個版本,併為了能力提升和最佳化而逐步向4.1及更高版本過渡。
現象二:top顯示非0即300%
登入到機器上執行top -b -d 1 –p | grep , 可以看到行程的CPU利用率每隔幾分鐘到幾十分鐘出現一次300%,這意味著該行程3個執行緒佔用的3個CPU都跑滿了,跟監控程式呈現同樣的異常。

上述異常程式使用的是同樣的資料源:/proc/pid/stat中行程執行佔用的使用者態時間utime和核心態時間stime。我們抓取utime和stime更新情況後,發現utime或者stime每隔幾分鐘或者幾十分鐘才更新,更新的步進值達到幾百到1000+,而正常行程看到的是每幾秒更新,步進值是幾十。
定位到異常點後,還要找出原因。排除了監控邏輯、IO負載、呼叫瓶頸等可能後,確認是4.1內核的CPU時間統計有 bug。
cputime統計邏輯
檢查/proc/pid/stat中utime和stime被更新的程式碼執行路徑,在cputime_adjust()發現了一處可疑的地方:

當utime+stime>=rtime的時候就直接跳出了,也就是不更新utime和stime了!這裡的rtime是runtime,代表行程執行佔用的所有CPU時長,正常應該等於或近似行程使用者態時間+核心態時間。 但內核配置了CONFIG_VIRT_CPU_ACCOUNTING_GEN選項,這會讓utime和stime分別單調增長。而runtime是排程器裡統計到的行程真正執行總時長。
核心每次更新/proc/pid/stat的utime和stime的時候,都會跟rtime對比。如果utime+stime很長一段時間都大於rtime,那程式碼直接goto out了, /proc/pid/stat就不更新了。只有當rtime持續更新追上utime+stime後,才更新utime和stime。

第一回合:冷補丁
出現問題的程式碼位置已經找到,那就先去核心社群看看有沒有成熟補丁可用,看一下kernel/sched/cputime.c的 changelog,看到一個patch:確保stime+utime=rtime。再看描述:像top這樣的工具,會出現超過100%的利用率,之後又一段時間為0,這不就是我們遇到的問題嗎?真是踏破鐵鞋無覓處,得來全不費工夫!(patch連結:https://lore.kernel.org/patchwork/patch/609410/)

該補丁在4.3核心及以後版本才提交, 卻並未提交到4.1穩定版分支,於是移植到4.1核心。打上該補丁後進行壓測,再沒出現cputime時而100%時而0%的現象,而是0-100%之間平滑波動的值。
至此,你可能覺得問題已經解決了。但是,問題才解決了一半。而往往“但是”後邊才是重點。
第二回合:熱補丁
給核心程式碼打上該冷補丁只能解決新增伺服器的問題,但公司還有數萬存量伺服器是無法升級核心後重啟的。
如果沒有其它好選擇,那存量更新將被迫採用如下的妥協方案:監控程式修改統計方式進行規避,不再使用utime和stime,而是透過runtime來統計行程的執行時間。
雖然該方案快速可行,但也有很大的缺點:
1. 很多業務部門都要修改統計程式,研發成本較高;
2. /proc/pid/stat的utime和stime是標準統計方式,一些第三方元件並不容易修改;
3. 並沒有根本解決utime和stime不準的問題,使用者、研發、運維使用ps、top命令時還會產生困惑,產生額外的溝通協調成本。
幸好,我們還可以依靠UCloud已多次成功應用的技術:熱補丁技術。
所謂熱補丁技術,是指在有缺陷的伺服器核心或行程正在執行時,對已經載入到記憶體的程式二進位制打上補丁,使得程式實時線上狀態下執行新的正確邏輯。可以簡單理解為像關二爺那樣不打麻藥在清醒狀態下刮骨療傷。當然,對核心刮骨療傷內核是不會痛的,但刮不好核心就會直接死給你看,沒有絲毫猶豫,非常乾脆利索又耿直。
而本次熱補丁修複存在兩個難點:
難點一: 熱補丁製作
這次熱補丁在結構體新增了spinlock成員變數,那就涉及新成員的記憶體分配和釋放,在結構體實體被覆制和釋放時,都要額外的對新成員做處理,稍有遺漏可能會造成記憶體洩漏進而導致宕機,這就加大了風險。
再一個就是,結構體實體是在行程啟動時初始化的,對於已經存在的實體如何塞進新的spinlock成員?所謂兵來將擋水來土掩,我們想到可以在原生補丁使用spinlock成員的程式碼路徑上攔截,如果發現實體不含該成員,則進行分配、初始化、加鎖、釋放鎖。
要解決問題,既要攀登困難的山峰,又得控制潛在的風險。團隊編寫了指令碼進行幾百萬次的載入、解除安裝熱補丁測試,並無記憶體洩漏,單機穩定執行,再下一城。

難點二:難以復現
另一個難題是該問題難以復現,只有在現網生產環境才有幾個case可驗證熱補丁,而又不可以拿使用者的環境去冒險。針對這種情況我們已經有標準化處理流程去應對,那就是設計完善的灰度策略,這也是UCloud內部一直在強調的核心理念和能力。經過分析,這個問題可以拆解為驗證熱補丁穩定性和驗證熱補丁正確性。於是我們採取瞭如下灰度策略:
1. 穩定性驗證:先拿幾臺機器測試正常,再拿公司內部500臺次級重要的機器打熱補丁,灰度執行幾天正常,從而驗證了穩定性,風險盡在掌控之中。
2. 正確性驗證:找到一臺出現問題的機器,同時列印utime+stime以及rtime,根據程式碼的邏輯,當rtime小於utime+stime時會執行老邏輯,當rtime大於utime+stime時會執行新的熱補丁邏輯。如下圖所示,進入熱補丁的新邏輯後,utime+stime列印正常且與rtime保持了同步更新,從而驗證了熱補丁的正確性。
3. 全網變更:最後再分批在現網環境機器上打熱補丁,執行全網變更,問題得到根本解決,此處要感謝運維同學的全力協助。
綜上,我們詳細介紹了行程cputime統計異常問題的完整分析和解決思路。該問題並非嚴重的宕機問題,但卻可能會讓使用者對監控資料產生困惑,誤認為可能機器負載太高需要加資源,問題的解決會避免產生不必要的開支。此外,該問題也會讓研發、運維和技術支援的同學們使用top和ps命令時產生困惑。最終我們對問題的本質仔細分析並求證,用熱補丁的方式妥善的解決了問題。
— END —
本文來自:UCloud技術

