
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
關於作者:陳泰紅,小米高階演演算法工程師,研究方向為人臉檢測識別,手勢識別與跟蹤。
■ 論文 | mixup: Beyond Empirical Risk Minimization
■ 連結 | https://www.paperweekly.site/papers/1605
論文動機
神經網路訓練需要海量的人工標註資料集,一般的資料增廣方式是裁剪、翻轉以及旋轉、尺度變化。之前在 arXiv 上看到過 IBM的一篇文章 SamplePairing:針對影象處理領域的高效資料增強方式,該論文主要是關於資料增強方式,沒有公式沒有網路架構,只通過簡單的相加求平均值方式。
而在最近公佈的 ICLR 2018 入圍名單中,另一篇資料增廣相關論文脫穎而出,而 SamplePairing 出局。仔細閱讀 Mixup 的論文,發現它其實是對 SamplePairing 的更進一步延伸。
名詞解釋
Empirical Risk Minimization (ERM):機器學習的經驗風險最小化,ERM 策略認為,經驗風險最小化的模型是最最佳化的模型。可參照李航的《統計學習方法》[1] 進行理解。
Βeta分佈:既然機率論中的貝塔分佈,是指一組定義在是指一組定義在(0,1)區間的連續機率分佈,有兩個引數 α 和 β。論文中 α 和 β 相等。Βeta 分佈的定義、機率密度函式和性質可參考 PRML [2]。
為了理解 Beta 分佈,使用 Python 視覺化 Beta 的模型。論文選擇的超引數是 α=0.2 和 0.4,此處主要觀察 α 變化對應的機率分佈變化。
from scipy.stats import beta
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 1, 100)
a_array = [1,0.5 ,0.1 ,0.2, 0.01,0.001]
for a in a_array:
plt.plot(x, beta.pdf(x, a, a), lw=1, alpha=0.6, label='a=' + str(a) + ',b=' + str(a))
plt.legend(frameon=False)
plt.show()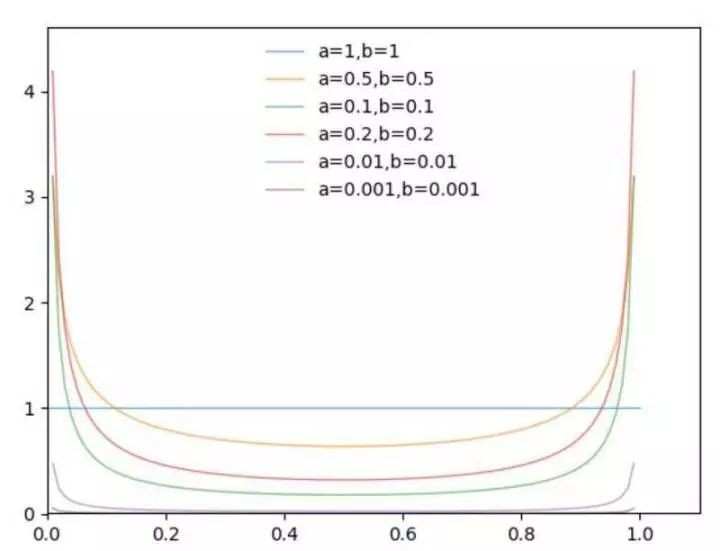
從上圖可以看出,α 趨近於 0 時,機率分佈趨近於 x-0 和 x=1 兩種情況,在論文中代表 ERM。
模型細節
SamplePairing
SamplePairing 的實現很簡單,兩幅圖片直接畫素相加求平均,監督的 label 不變。但是在訓練過程中,先用 ILSVRC 資料集普通資料增廣方式,完成多個 epoch 後間歇性禁止 SamplePairing,在訓練損失函式和精度穩定後,禁止 SamplePairing 進行微調。
個人認為相當於隨機引入噪聲,在訓練樣本中人為引入誤導性的訓練樣本。
mixup

△ mixup實現公式、Python原始碼和視覺化實現
其中 (xi, yi) 和 (xj, yj) 是訓練集隨機選取的兩個資料,λ ∈ [0,1],λ ∼ Beta(α,α)。
mixup 擴充套件訓練集分佈基於這樣的先驗知識:線性特徵向量的混合導致相關標的線性混合。混合超引數 α 控制特徵標的之間的插值強度,α→0 時表示 ERM。
mixup 模型實現方式簡單,PyTorch 7 行程式碼即可實現。上圖中的視覺化表明,mixup 導致決策邊界模糊化,提供更平滑的預測。
實驗
論文的實驗過程很豐富,包括 CIFAR-10,CIFAR-100,和 ImageNet-2012,隨機噪音測試,語音資料,facing adversarial examples 黑盒攻擊和白盒攻擊,UCI 資料集,以及穩定訓練 GAN 網路。
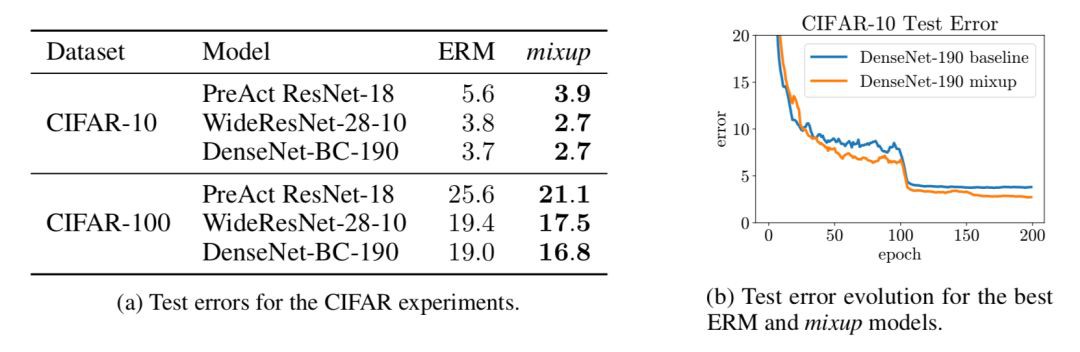





對於具有代表性的 ImageNet-2012,Top-1 的精度至少提高 1.2%。

討論
論文提出,在訓練過程中,隨著 α 增加,訓練誤差越來越大,而在驗證驗證集測試中泛化誤差反而減少。這與論文提出的假設相同:mixup 隱含控制模型的複雜度。但是論文沒有提出 bias-variance trade-off 的理論解釋。
論文提出一些進一步探索的可行性:
-
mixup 是否可以應用在其他監督學習問題,比如回歸和結構化預測。mixup 可能在回歸問題容易實現,結構化預測如影象分割等問題,實驗效果不明顯。
-
mixup 是否可以用於半監督學習、無監督學習或強化學習。當然作者是假設,希望有後來者證明 mixup 是理論可行的。
mixup 來自 MIT 和 Facebook AI Research。ICLR 是雙盲評審,官網上的匿名評審意見普遍認為 mixup 缺乏理論基礎,但是實驗效果具有明顯優勢。筆者個人認為在 mixup 基礎上,還有很多坑可以填。
參考文獻
[1] 《統計學習方法》,李航
[2] Pattern Recognition and Machine Learning, Bishop
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選以下標題檢視相關內容:

 #榜 單 公 布 #
#榜 單 公 布 #
2017年度最值得讀的AI論文 | NLP篇 · 評選結果公佈
2017年度最值得讀的AI論文 | CV篇 · 評選結果公佈
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot01)進行諮詢
長按識別二維碼,使用小程式
*點選閱讀原文即可註冊

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文