小編邀請您,先思考:
1 如何讓資料驅動決策?
“資料驅動決策”,為了不讓這句話成為空話,請先裝備以下13種思想武器,相信將來你一定能用上!
1. 信度與效度思維

這部分也許是全文最難理解的部分,但我覺得也最為重要。沒有這個思維,決策者很有可能在資料中迷失。
信度與效度的概念最早來源於調查分析,但現在我覺得可以引申到資料分析工作的各方面。
所謂信度,是指一個資料或指標自身的可靠程度,包括準確性和穩定性。
取數邏輯是否正確?有沒有計算錯誤?這屬於準確性;每次計算的演演算法是否穩定?口徑是否一致?以相同的方法計算不同的物件時,準確性是否有波動?這是穩定性。做到了以上兩個方面,就是一個好的資料或指標了?其實還不夠,還有一個更重要的因素,就是效度!
所謂效度,是指一個資料或指標的生成,需貼合它所要衡量的事物,即指標的變化能夠代表該事物的變化。
只有在信度和效度上都達標,才是一個有價值的資料指標。舉個例子:要衡量我身體的肥胖情況,我選擇了穿衣的號碼作為指標,一方面,相同的衣服尺碼對應的實際衣服大小是不同的,會有美版韓版等因素,使得準確性很差;同時,一會兒穿這個牌子的衣服,一會兒穿那個牌子的衣服,使得該衡量方式形成的結果很不穩定;所以,衣服尺碼這個指標的信度不夠。另一方面,衡量身體肥胖情況用衣服的尺碼大小?你一定覺得荒唐,尺碼大小並不能反映肥胖情況,是吧?因此效度也不足。體脂率,才是信度和效度都比較達標的肥胖衡量指標。
在我們的現實工作中,許多人會想當然地拿了指標就用,這是非常值得警惕的。你要切骨頭卻拿了把手術刀,是不是很可悲?信度和效度的本質,其實就是**資料質量**的問題,這是一切分析的基石,再怎麼重視都不過分!
2. 平衡思維

說到天平大家都不陌生,平衡的思維相信各位也都能很快理解。簡單來說,在資料分析的過程中,我們需要經常去尋找事情間的平衡關係,且平衡關係往往是關乎企業運轉的大問題,如市場的供需關係,薪資與效率關係,工作時長與錯誤率的關係等等。
平衡思維的關鍵點,在於尋找能展示出平衡狀態的指標!
也就是如圖中紅圈,我們要去尋找這個準確的量化指標,來觀察天平的傾斜程度。怎麼找這個指標呢?以我的經驗,一般先找雙向型的問題,即高也不是低也不是的問題,然後量化為指標,最後計算成某個比率,長期跟蹤後,觀察它的信度和效度。
3. 分類思維

客戶分群、產品歸類、市場分級、績效評價…許多事情都需要有分類的思維。主觀拍腦袋可以分類,透過機器學習演演算法也可以分類,那麼許多人就模糊了,到底分類思維怎麼應用呢?
關鍵點在於,分類後的事物,需要在核心指標上能拉開距離!
也就是說分類後的結果,必須是顯著的。如圖,橫軸和縱軸往往是你運營當中關註的核心指標(當然不限於二維),而分類後的物件,你能看到他們的分佈不是隨機的,而是有顯著的叢集的傾向。
舉個例子:假設該圖反映了某個消費者分群的結果,橫軸代表購買頻率,縱軸代表客單價,那麼綠色的這群人,就是明顯的“人傻錢多”的“剁手金牌客戶”。
4. 矩陣化思維
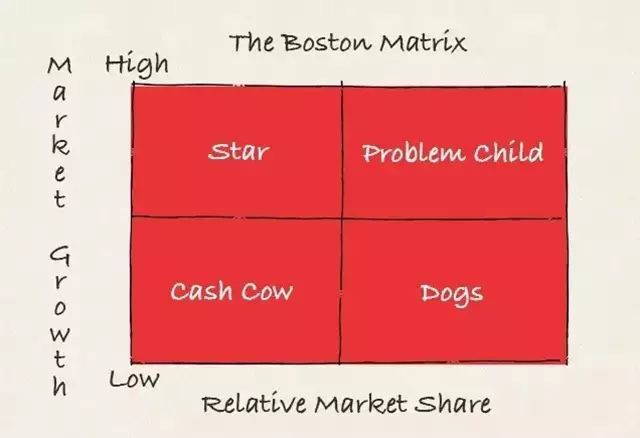
矩陣思維是分類思維的發展,它不再侷限於用量化指標來進行分類。許多時候,我們沒有資料做為支援,只能透過經驗做主觀的推斷時,是可以把某些重要因素組合成矩陣,大致定義出好壞的方向,然後進行分析。大家可以百度經典的管理分析方法“波士頓矩陣”模型(如圖所示)。
5. 管道 / 漏斗思維

這種思維方式已經普及:註冊轉化、購買流程、銷售管道、瀏覽路徑等,太多的分析場景中,能找到這種思維的影子。
但我要說,看上去越是普世越是容易理解的模型,它的應用越得謹慎和小心。在漏斗思維當中,我們尤其要註意漏斗的長度。
漏斗從哪裡開始到哪裡結束?以我的經驗,漏斗的環節不該超過5個,且漏斗中各環節的百分比數值,量級不要超過100倍(漏斗第一環節100%開始,到最後一個環節的轉化率數值不要低於1%)。若超過了我說的這兩個數值標準,建議分為多個漏斗進行觀察。當然,這兩個是經驗數值,僅僅給各位做個參考。
理由是什麼呢?超過5個環節,往往會出現多個重點環節,那麼在一個漏斗模型中分析多個重要問題容易產生混亂。數值量級差距過大,數值間波動相互關係很難被察覺,容易遺漏資訊。比如,漏斗前面環節從60%變到50%,讓你感覺是天大的事情,而漏斗最後環節0.1%的變動不能引起你的註意,可往往是漏斗最後這0.1%的變動非常致命。
6. 相關思維

我們觀察指標,不僅要看單個指標的變化,還需要觀察指標間的相互關係!有正相關關係(圖中紅色實線)和負相關關係(藍色虛線)。最好能時常計算指標間的相關係數,定期觀察變化。
相關思維的應用太廣了,我提的往往是被大家忽略的一點。現在的很多企業管理層,面對的問題並不是沒有資料,而是資料太多,卻不知道怎麼用。相關思維的其中一個應用,就是能夠幫助我們找到最重要的資料,排除掉過多雜亂資料的幹擾!
如何執行呢?你可以計算能收集到的多個指標間的相互關係,挑出與其他指標相關係數都相對較高的資料指標,分析它的產生邏輯,對應的問題,並評估信度和效度,若都滿足標準,這個指標就能定位為核心指標!
建議大家養成一個習慣,經常計算指標間的相關係數,仔細思考相關係數背後的邏輯,有的是顯而易見的常識,比如訂單數和購買人數,有的或許就能給你帶來驚喜!另外,“沒有相關關係”,這往往也會成為驚喜的來源哦。
7. 遠近度思維

現在與許多處在管理層的朋友交流後,發現他們往往手握眾多資料和報表,註意力卻是非常的跳躍和分散。如何避免呢?一是上文說的透過相關思維,找到最核心的問題和指標;二就是這部分要說的,建立遠進度的思維方式。
確定好核心問題後,分析其他業務問題與核心問題的遠近程度,由近及遠,把自己的精力有計劃地分配上去。比如:近期你的核心任務就是提高客服人員的服務質量,那麼客服人員的話術、客戶評價通道、客服系統的相應速度等就是靠的最近的子問題,需要重點關註。而客戶的問詢習慣、客戶的購買週期等就是相對遠的問題,暫時先放一放。當然,本人經歷有限,例子舉得不恰當的地方還望讀者們海涵。
8. 邏輯樹思維
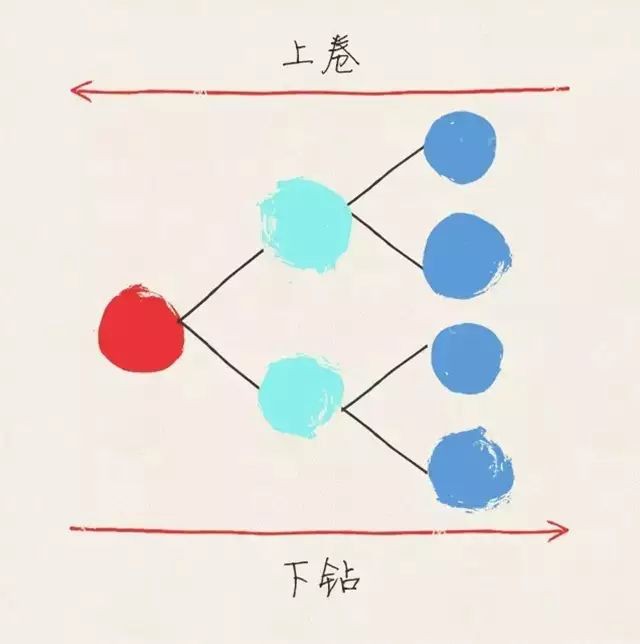
如圖的樹狀邏輯相信大家已經見過許多回了。一般說明邏輯樹的分叉時,都會提到“分解”和“彙總”的概念。我這裡把它變一變,使其更貼近資料分析,稱為“下鑽”和“上捲”。當然,這兩個詞不是我發明的,早已有之。
所謂下鑽,就是在分析指標的變化時,按一定的維度不斷的分解。比如,按地區維度,從大區到省份,從省份到城市,從省市到區。所謂上捲就是反過來。隨著維度的下鑽和上捲,資料會不斷細分和彙總,在這個過程中,我們往往能找到問題的根源。
下鑽和上捲並不是侷限於一個維度的,往往是多維組合的節點,進行分叉。邏輯樹引申到演演算法領域就是決策樹。有個關鍵便是何時做出決策(判斷)。當進行分叉時,我們往往會選擇差別最大的一個維度進行拆分,若差別不夠大,則這個枝椏就不在細分。能夠產生顯著差別的節點會被保留,並繼續細分,直到分不出差別為止。經過這個過程,我們就能找出影響指標變化的因素。
舉個簡單的例子:我們發現全國客戶數量下降了,我們從地區和客戶年齡層級兩個維度先進行觀察,發現各個年齡段的客戶都下降,而地區間有的下降有的升高,那我們就按地區來拆分第一個邏輯樹節點,拆分到大區後,發現各省間的差別是顯著的,那就繼續拆分到城市,最終發現是浙江省杭州市大量客戶且涵蓋各個年齡段,被競爭對手的一波推廣活動轉化走了。就此透過三個層級的邏輯樹找到了原因。
9. 時間序列思維
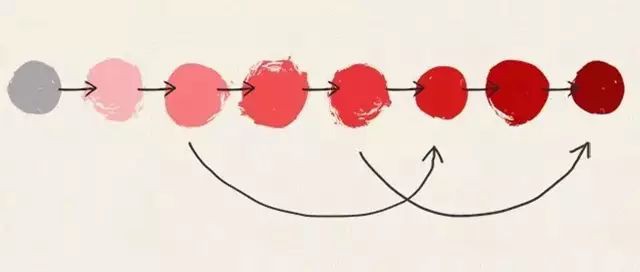
很多問題,我們找不到橫向對比的方法和物件,那麼,和歷史上的狀況比,就將變得非常重要。其實很多時候,我更願意用時間維度的對比來分析問題,畢竟發展地看問題,也是“紅色方法論”中的重要一環。這種方式容易排除掉一些外在的幹擾,尤其適合創新型的分析物件,比如一個新行業的公司,或者一款全新的產品。
時間序列的思維有三個關鍵點:一是距今越近的時間點,越要重視(圖中的深淺度,越近期發生的事,越有可能再次發生);二是要做同比(圖中的尖頭指示,指標往往存在某些週期性,需要在週期中的同一階段進行對比,才有意義);三是異常值出現時,需要重視(比如出現了歷史最低值或歷史最高值,建議在時間序列作圖時,新增平均值線和平均值加減一倍或兩倍標準差線,便於觀察異常值)。
時間序列思維有一個子概念不得不提一下,就是“生命週期”的概念。使用者、產品、人事等無不有生命週期存在。本人最近也正在將關註的重心移向這塊,直覺上,生命週期衡量清楚,就能很方便地確定一些“閥值”問題,使產品和運營的節奏更明確。
10. 佇列分析思維
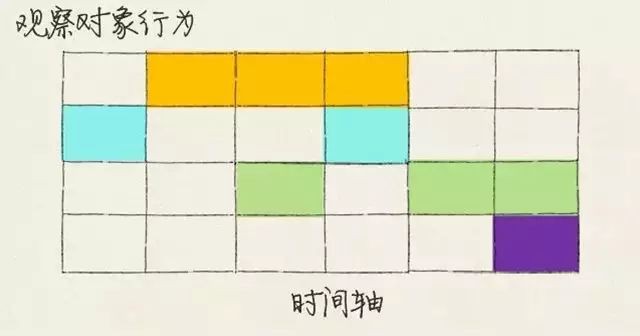
隨著資料運算能力的提高,佇列分析的方式逐漸展露頭腳。英文名稱為cohort analysis,說實話我不知道怎麼表述這個概念,我的理解就是按一定的規則,在時間顆粒度上將觀察物件切片,組成一個觀察樣本,然後觀察這個樣本的某些指標隨著時間的演進而產生的變化。目前使用得最多的場景就是留存分析。
舉個經常用的例子:假設5.17我們舉辦了一次促銷活動,那麼將這一天來的新使用者作為一個觀察樣本,觀察他們在5.18、5.19…之後每天的活躍情況。
佇列分析中,指標其實就是時間序列,不同的是衡量樣本。佇列分析中的衡量樣本是在時間顆粒上變化的,而時間序列的樣本則相對固定。
11. 迴圈 / 閉環思維

迴圈/閉環的概念可以引申到很多場景中,比如業務流程的閉環、使用者生命週期閉環、產品功能使用閉環、市場推廣策略閉環等等。許多時候你會覺得這是一個不落地的概念,因為提的人很多,乾出事情來的例子很少。
但我覺得這種思考方式是非常必要的。業務流程的閉環是管理者比較容易定義出來的,列出公司所有業務環節,梳理出業務流程,然後定義各個環節之間相互影響的指標,跟蹤這些指標的變化,能從全域性上把握公司的執行狀況。
比如,一家軟體公司的典型業務流:推廣行為(市場部)➡ 流量進入主站(市場+產研)➡ 註冊流程(產研)➡ 試用體驗(產研+銷售)➡ 進入採購流程(銷售部)➡ 交易並部署(售後+產研)➡ 使用、續約、推薦(售後+市場)➡ 推廣行為,一個閉環下來,各個銜接環節的指標,就值得關註了:廣告點選率 ➡ 註冊流程進入率 ➡ 註冊轉化率 ➡ 試用率 ➡ 銷售管道各環節轉化率 ➡ 付款率 ➡ 推薦率/續約率…這裡會涉及漏斗思維,如前文所述,千萬不要用一個漏斗來衡量一個迴圈。
有了迴圈思維,你能比較快的建立有邏輯關係的指標體系。
12. 測試 / 對比思維

AB Test,大家肯定不陌生了。那麼怎麼細化一下這個概念?一是在條件允許的情況下,決策前儘量做對比測試;二是測試時,一定要註意參照組的選擇,建議任何實驗中,都要留有不進行任何變化的一組樣本,作為最基本的參照。
現在資料獲取越來越方便,在保證資料質量的前提下,希望大家多做實驗,多去發現規律。
13. 指數化思維

指數化思維,是指將衡量一個問題的多個因素分別量化後,組合成一個綜合指數(降維),來持續追蹤的方式。把這個放在最後討論,目的就是強調它的重要性。前文已經說過,許多管理者面臨的問題是“資料太多,可用的太少”,這就需要“降維”了,即要把多個指標壓縮為單個指標。
指數化的好處非常明顯,一是減少了指標,使得管理者精力更為集中;二是指數化的指標往往都提高了資料的信度和效度;三是指數能長期使用且便於理解。
指數的設計是門大學問,這裡簡單提三個關鍵點:一是要遵循**獨立和窮盡**的原則;二是要註意各指標的單位,儘量做**標準化**來消除單位的影響;三是權重和需要等於1。
獨立窮盡原則,即你所定位的問題,在蒐集衡量該問題的多個指標時,各個指標間儘量相互獨立,同時能衡量該問題的指標儘量窮盡(收集全)。舉個例子:當初設計某公司銷售部門的指標體系時,目的是衡量銷售部的績效,確定了核心指標是銷售額後,我們將績效拆分為訂單數、客單價、線索轉化率、成單週期、續約率5個相互獨立的指標,且這5個指標涵蓋了銷售績效的各個方面(窮盡)。我們設計的銷售績效綜合指數=0.4*訂單數+0.2*客單價+0.2*線索轉化率+0.1*成單週期+0.1*續約率,各指標都採用max-min方法進行標準化。
透過這個例子,相信各位就能理解指數化思維了
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

好又樂書屋,專註分享有思想的人物,身心健康,自我教育,閱讀寫作和有趣味的生活等內容,傳播正能量。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
