小編邀請您,先思考:
1 XGBoost和GDBT演演算法有什麼差異?
XGBoost的全稱是 eXtremeGradient Boosting,2014年2月誕生的專註於梯度提升演演算法的機器學習函式庫,作者為華盛頓大學研究機器學習的大牛——陳天奇。他在研究中深深的體會到現有庫的計算速度和精度問題,為此而著手搭建完成 xgboost 專案。xgboost問世後,因其優良的學習效果以及高效的訓練速度而獲得廣泛的關註,併在各種演演算法大賽上大放光彩。

1.CART
CART(回歸樹, regressiontree)是xgboost最基本的組成部分。其根據訓練特徵及訓練資料構建分類樹,判定每條資料的預測結果。其中構建樹使用gini指數計算增益,即進行構建樹的特徵選取,gini指數公式如式(1), gini指數計算增益公式如式(2):
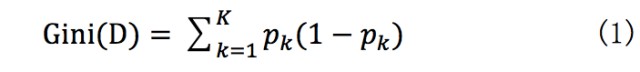
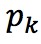 表示資料集中類別的機率,表示類別個數。
表示資料集中類別的機率,表示類別個數。
註:此處圖的表示分類類別。

D表示整個資料集,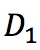 和
和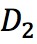 分別表示資料集中特徵為的資料集和特徵非的資料集,
分別表示資料集中特徵為的資料集和特徵非的資料集, 表示特徵為的資料集的gini指數。
表示特徵為的資料集的gini指數。
以是否打網球為例(只是舉個慄子):
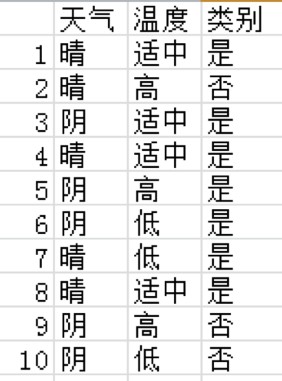
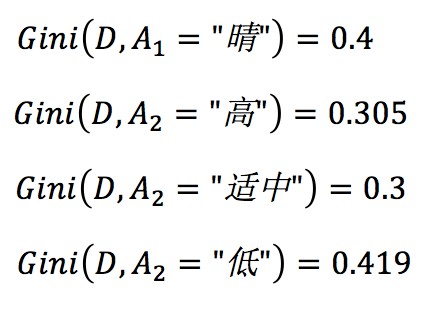

其中,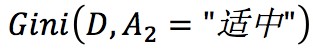 最小,所以構造樹首先使用溫度適中。然後分別在左右子樹中查詢構造樹的下一個條件。
最小,所以構造樹首先使用溫度適中。然後分別在左右子樹中查詢構造樹的下一個條件。
本例中,使用溫度適中拆分後,是子樹剛好類別全為是,即溫度適中時去打網球的機率為1。
2.Boostingtree
一個CART往往過於簡單,並不能有效地做出預測,為此,採用更進一步的模型boosting tree,利用多棵樹來進行組合預測。具體演演算法如下:
輸入:訓練集
輸出:提升樹
步驟:
(1)初始化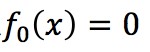
(2) 對m=1,2,3……M
a)計算殘差
b)擬合殘差 學習一個回歸樹,得到
學習一個回歸樹,得到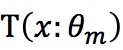
c)更新 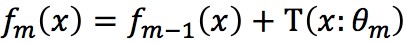
(3)得到回歸提升樹:
例子詳見後面程式碼部分。
3.xgboost
首先,定義一個標的函式:

constant為一個常數,正則項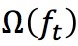 如下,
如下,
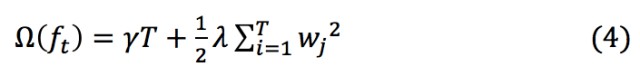
其中,T表示葉子節點數,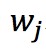 表示第j個葉子節點的權重。
表示第j個葉子節點的權重。
例如下圖,葉子節點數為3,每個葉子節點的權重分別為2,0.1,-1,正則項計算見圖:

利用泰勒展開式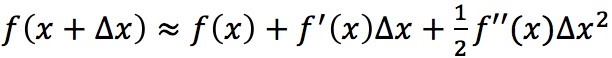 ,對式(3)進行展開:
,對式(3)進行展開:

其中, 表示
表示 對
對 的一階導數,
的一階導數, 表示對的二階導數。
表示對的二階導數。
為真實值與前一個函式計算所得殘差是已知的(我們都是在已知前一個樹的情況下計算下一顆樹的),同時,在同一個葉子節點上的數的函式值是相同的,可以做合併,於是:
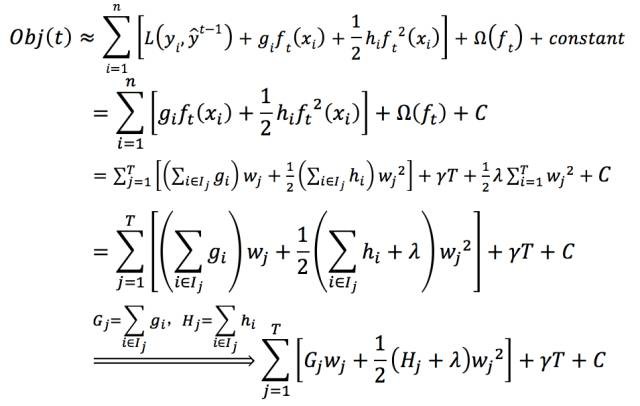
透過對求導等於0,可以得到

將帶入得標的函式的簡化公式如下:

標的函式簡化後,可以看到xgboost的標的函式是可以自定義的,計算時只是用到了它的一階導和二階導。得到簡化公式後,下一步針對選擇的特徵計算其所帶來的增益,從而選取合適的分裂特徵。

提升樹例子程式碼:
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# 標的函式為真實值與預測值的差的平方和
import math
# 資料集,只包含兩列
test_list = [[1,5.56], [2,5.7], [3,5.81], [4,6.4], [5,6.8],\
[6,7.05], [7,7.9], [8,8.7], [9,9],[10,9.05]]
step = 1 #eta
# 起始拆分點
init = 1.5
# 最大拆分次數
max_times = 10
# 允許的最大誤差
threshold = 1.0e-3
def train_loss(t_list):
sum = 0
for fea in t_list:
sum += fea[1]
avg = sum * 1.0 /len(t_list)
sum_pow = 0
for fea in t_list:
sum_pow =math.pow((fea[1]-avg), 2)
return sum_pow, avg
def boosting(data_list):
ret_dict = {}
split_num = init
while split_num
pos = 0
for idx, data inenumerate(data_list):
if data[0]> split_num:
pos = idx
break
if pos > 0:
l_train_loss,l_avg = train_loss(data_list[:pos])
r_train_loss,r_avg = train_loss(data_list[pos:])
ret_dict[split_num] = [pos,l_train_loss+r_train_loss, l_avg, r_avg]
split_num += step
return ret_dict
def main():
ret_list = []
data_list =sorted(test_list, key=lambda x:x[0])
time_num = 0
while True:
time_num += 1
print ‘beforesplit:’,data_list
ret_dict =boosting(data_list)
t_list =sorted(ret_dict.items(), key=lambda x:x[1][1])
print ‘splitnode:’,t_list[0]
ret_list.append([t_list[0][0], t_list[0][1][1]])
if ret_list[-1][1]< threshold or time_num > max_times:
break
for idx, data inenumerate(data_list):
if idx
data[1] -=t_list[0][1][2]
else:
data[1] -=t_list[0][1][3]
print ‘after split:’,data_list
print ‘split node andloss:’
print’\n’.join([“%s\t%s” %(str(data[0]), str(data[1])) for data inret_list])
if __name__ == ‘__main__’:
main()

推薦閱讀
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

好又樂書屋,專註分享有思想的人物,身心健康,自我教育,閱讀寫作和有趣味的生活等內容,傳播正能量。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
