
本文為Kubernetes監控系列的第二篇文章,系列目錄如下:
本文將介紹關於如何在Kubernetes叢集中配置基礎設施層的警報。本文是關於在生產中使用Kubernetes系列的一部分。第一部分介紹了Kubernetes和監控工具的基礎知識;這部分涵蓋了Kubernetes報警的最佳實踐,第三部分將介紹Kubernetes服務發現與故障排除,最後一部分是監控Kubernetes的實際使用案例。
監控是每個優質基礎設施的基礎,是達到可靠性層次的基礎。監控有助於減少對突發事件的響應時間,實現對系統問題的檢測、故障排除和除錯。在基礎設施高度動態的雲時代,監控也是容量規劃的基礎。
有效的警報是監控策略的基石。當你轉向容器和Kubernetes編排環境,你的警報策略也需要演進。正是因為以下幾個核心原因,其中許多我們在”如何監視Kubernetes“中進行了講述:
-
可見性:容器是一個黑盒。傳統工具只能針對公共監控端點進行檢查。如果想深入監控相關服務,則需要採取不一樣的方法。
-
新的基礎架構層:現在服務和主機之間有一個新的層:容器和容器編排服務。這些是你需要監控的新內部服務,你的監控系統需要瞭解這些服務。
-
動態重排程:容器沒有像之前那樣的服務節點,所以傳統的監控不能有效地工作。沒有獲取服務度量標準的靜態端點,沒有執行服務實體的靜態數量(設想一個金絲雀釋出或自動伸縮設定)。在某節點中一個行程被kill是正常的,因為它有很大的機會被重新排程到基礎設施的其他節點。
-
元資料和標簽:隨著服務跨多個容器,為所有這些服務新增系統級別的監控以及服務特定的度量標準,再加上Kubernetes帶來的所有新服務,如何讓所有這些資訊對我們有所幫助?有時你希望看到分佈在不同節點容器中的服務的網路請求度量,有時你希望看到特定節點中所有容器的相同度量,而不關心它們屬於哪個服務。這就需要一個多維度量系統,需要從不同的角度來看待這些指標。如果透過Kubernetes中存在的不同標簽自動標記度量標準,並且監控系統能夠瞭解Kubernetes元資料,那麼只需要在每種情況下按照需要聚合和分割度量標準就可以實現多維度度量。
考慮到這些問題,讓我們建立一組對Kubernetes環境至關重要的報警策略。我們的Kubernetes報警策略教程將涵蓋:
-
應用程式層度量標準的報警
-
Kubernetes上執行的服務的報警
-
Kubernetes基礎設施的報警
-
在主機/節點層上的報警
最後我們還將透過檢測系統呼叫問題來瞭解如何透過報警加速故障排除。

工作指標(working metrics)可以確認應用程式是否按預期執行,這些度量標準通常來自使用者或消費者對服務的期望操作,或者是由應用程式透過statsd或JMX在內部生成。如果監控系統本身提供網路資料,就可以使用它來建立基於響應時間的報警策略。
以下示例是一個公共REST API端點監控警報,監控prod命令空間中的名為javaapp的deployment,在10分鐘內如果延遲超過1秒則報警。
所有這些報警高度依賴於應用程式、工作負載樣式等等,但真正的問題是如何在所有服務中一致性地獲取資料。在理想環境中,除了核心監控工具之外,無需再購買綜合監控服務即可獲得這一套關鍵指標。
-
服務相應時間
-
服務可用性
-
SLA合規性
-
每秒請求的成功/失敗數
對於服務級別,和使用Kubernetes之前對於服務叢集需要做的事情應該沒什麼不同。試想下,當在MySQL/MariaDB或者MongoDB等資料庫服務中檢視副本狀態與延遲時,需要考慮些什麼?
沒錯,如果想知道服務的全域性執行和執行情況,就需要利用監視工具功能根據容器元資料將度量標準進行聚合和分段。
如第一篇文章所述,Kubernetes將容器標記為一個deployment或者透過一個service進行暴露,在定義報警時就需要考慮這些因素,例如針對生產環境的報警(可能透過名稱空間進行定義)。
如果我們在Kubernetes、AWS EC2或OpenStack中執行Cassandra,則衡量指標cassandra.compactions.pending存在每個實體上,但是現在我們要檢視在prod名稱空間內的cassandra複製控制器中聚合的指標。這兩個標簽都來自Kubernetes,但我們也可以更改範圍,包括來自AWS或其他雲提供商的標簽,例如可用區域。
另外,如果正在使用外部託管服務,則很可能需要從這些提供程式匯入度量標準,因為它們可能還有需要做出反應的事件。
在容器編排層面的監控和報警有兩個層面。一方面,我們需要監控Kubernetes所處理的服務是否符合所定義的要求。另一方面,我們需要確保Kubernetes的所有元件都正常執行。
1.1 是否有足夠的Pod/Container給每個應用程式執行?
Kubernetes可以透過Deployments、Replica Sets和Replication Controllers來處理具有多個Pod的應用程式。它們之間區別比較小,可以使用它們來維護執行相同應用程式的多個實體。執行實體的數量可以動態地進行伸縮,甚至可以透過自動縮放來實現自動化。
執行容器數量可能發生變化的原因有多種:因為節點失敗或資源不足將容器重新排程到不同主機或者進行新版本的滾動部署等。如果在延長的時間段內執行的副本數或實體的數量低於我們所需的副本數,則表示某些元件工作不正常(缺少足夠的節點或資源、Kubernetes或Docker Engine故障、Docker映象損壞等等)。
在Kubernetes部署服務中,跨多個服務進行如下報警策略對比是非常有必要的:
timeAvg(kubernetes.replicaSet.replicas.running) < timeAvg(kubernetes.replicaSet.replicas.desired)
正如之前所說,在重新排程與遷移過程執行中的實體副本數少於預期是可接受的,所以對每個容器需要關註配置項 .spec.minReadySeconds (表示容器從啟動到可用狀態的時間)。你可能也需要檢查 .spec.strategy.rollingUpdate.maxUnavailable 配置項,它定義了在滾動部署期間有多少容器可以處於不可用狀態。
下麵是上述報警策略的一個示例,在 wordpress 名稱空間中叢集 kubernetes-dev 的一個deployment wordpress-wordpress。
1.2 是否有給定應用程式的任何Pod/Container?
與之前的警報類似,但具有更高的優先順序(例如,這個應用程式是半夜獲取頁面的備選物件),將提醒是否沒有為給定應用程式執行容器。
以下示例,在相同的deployment中增加警報,但不同的是1分鐘內執行Pod <1時觸發:
1.3 重啟迴圈中是否有任何Pod/Container?
在部署新版本時,如果沒有足夠的可用資源,或者只是某些需求或依賴關係不存在,容器或Pod最終可能會在迴圈中持續重新啟動。這種情況稱為“CrashLoopBackOff”。發生這種情況時,Pod永遠不會進入就緒狀態,從而被視為不可用,並且不會處於執行狀態,因此,這種場景已被報警改寫。儘管如此,筆者仍希望設定一個警報,以便在整個基礎架構中捕捉到這種行為,立即瞭解具體問題。這不是那種中斷睡眠的報警,但會有不少有用的資訊。
這是在整個基礎架構中應用的一個示例,在過去的2分鐘內檢測到4次以上的重新啟動:
除了確保Kubernetes能正常完成其工作之外,我們還希望監測Kubernetes的內部健康狀況。這將取決於Kubernetes叢集安裝的不同元件,因為這些可能會根據不同部署選擇而改變,但有一些基本元件是相同的。
etcd是Kubernetes的分散式服務發現、通訊、命令通道。監控etcd可以像監控任何分散式鍵值資料庫一樣深入,但會使事情變得簡單。
我們可以進一步去監控設定命令失敗或者節點數,但是我們將會把它留給未來的etcd監控文章來描述。
節點故障在Kubernetes中不是問題,排程程式將在其他可用節點中生成容器。但是,如果我們耗盡節點呢?或者已部署的應用程式的資源需求超過了現有節點?或者我們達到配額限制?
在這種情況下發出警報並不容易,因為這取決於你想要在待機狀態下有多少個節點,或者你想要在現有節點上推送多少超額配置。可以使用監控度量值kube_node_status_ready和kube_node_spec_unschedulable進行節點狀態警報。
如果要進行容量級別報警,則必須將每個已排程Pod請求的CPU和memory進行累加,然後檢查是否會改寫每個節點,使用監控度量值kube_node_status_capacity_cpu_cores和kube_node_status_capacity_memory_bytes。
主機層的警報與監視虛擬機器或物理機區別不大,主要是關於主機是啟動還是關閉或不可訪問狀態,以及資源可用性(CPU、記憶體、磁碟等)。
主要區別是現在警報的嚴重程度。在此之前,系統服務宕機可能意味著你的應用程式停止執行並且要緊急處理事故(禁止有效的高可用性)。而對於Kubernetes來說當服務發生異常,服務可以在主機之間移動,主機警報不應該不受重視。
如果主機停機或無法訪問,我們希望收到通知。我們將在整個基礎架構中應用此單一警報。我們打算給它一個5分鐘的等待時間,因為我們不想看到網路連線問題上的嘈雜警報。你可能希望將其降低到1或2分鐘,具體取決於你希望接收通知的速度。

這是稍微複雜一些的警報。我們在整個基礎架構的所有檔案系統中應用此警報。我們將範圍設定為 everywhere,並針對每個 fs.mountDir 設定單獨的評估/警報。
以下是超過80%使用率的通用警報,但你可能需要不同的策略,如具有更高閾值(95%)或不同閾值的更高優先順序警報(具體取決於檔案系統)。

如果要為不同的服務或主機建立不同的閾值,只需更改要應用特定閾值的範圍。
此類別中的常見資源是有關負載、CPU使用率、記憶體和交換空間使用情況的警報。如果在一定的時間內這些資料中的任何一個顯著提升,可能就需要警報提醒您。我們需要在閾值、等待時間以及如何判定噪聲警報之間進行折中。
-
負載:load.average.1m, load.average.5m 和 load.average.15m
-
CPU:cpu.used.percent
-
memory:memory.used.percent 或 memory.bytes.used
-
swap:memory.swap.used.percent 或 memory.swap.bytes.used
一些人同樣使用這個類別監控他們部分基礎架構所在雲服務提供商的資源。
從警報觸發並收到通知的那一刻起,真正的工作就開始為DevOps值班成員開展工作。有時執行手冊就像檢查工作負載中的輕微異常一樣簡單。這可能是雲提供商的一個事件,但希望Kubernetes正在處理這個問題,並且只需要花費一些時間來應對負載。
但是如果一些更棘手的問題出現在我們面前,我們可以看到我們擁有的所有武器:提供者狀態頁面、日誌(希望來自中心位置)、任何形式的APM或分散式追蹤(如果開發人員安裝了程式碼或者外部綜合監測)。然後,我們祈禱這一事件在這些地方留下了一些線索,以便我們可以追溯到問題出現的多種來源原因。
我們怎麼能夠在警報被解除時自動dump所有系統呼叫?系統呼叫是所發生事情的真實來源,並將包含我們可以獲得的所有資訊。透過系統呼叫有可能發現觸發警報的根本問題所在。Sysdig Monitor允許在警報觸發時自動開始捕獲所有系統呼叫。
例如,可以配置CrashLoopBackOff場景:

只有當你安裝程式碼後,Sysdig Monitor代理才能從系統呼叫攔截中計算出來相應的指標。考慮HTTP響應時間或SQL響應時間。Sysdig Monitor代理程式在套接字上捕獲read()和write()系統呼叫,解碼應用程式協議並計算轉發到我們時間序列資料庫中的指標。這樣做的好處是可以在不觸及開發人員程式碼的情況下獲得儀錶盤資料和警報:
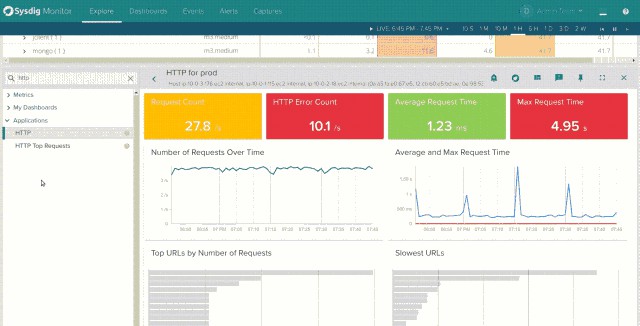
我們已經看到如何使用容器編排平臺來增加系統中移動部分的數量。擁有容器本地監控是建立可靠基礎架構的關鍵要素。監控不能僅僅關註基礎架構,而是需要從底層的主機到應用程式指標所在的頂端來瞭解整個技術棧。
能夠利用Kubernetes和雲服務提供商的元資料資訊來彙總和細分監控指標和警報將成為多層次有效監控的必要條件。我們已經看到如何使用標簽來更新我們已有的警報或建立Kubernetes上所需的新警報。
接下來,讓我們看看在Kubernetes編排環境中的典型服務發現故障排除的挑戰。
原文連結:https://sysdig.com/blog/alerting-kubernetes/
深入淺出Kubernetes及企業AI平臺落地實踐培訓

本次培訓內容包括:容器原理、Docker架構、工作原理、網路方案、儲存方案、Harbor、Kubernetes架構、元件、核心機制、外掛、核心模組、監控、日誌、二次開發、TensorFlow架構、工作原理、註意事項以及實踐經驗等,點選識別下方二維碼加微信好友瞭解具體培訓內容。
長按二維碼向我轉賬
![]()
受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。






