小編邀請您,先思考:
1 RNN和LSTM有什麼異同?
2 RNN的輸入和輸出分別是什麼?
3 如何用Python實現RNN?
傳統的機器學習方法,如SVM、logistics回歸和前饋神經網路都沒有將時間進行顯式模型化,用這些方法來建模都是基於輸入資料獨立性假設的前提。但是,對於很多工而言,這非常侷限。舉個例子,假如你想根據一句沒說完的話,預測下一個單詞,最好的辦法就是聯絡背景關係的資訊。下麵有兩種解決方案
1.一種思路是記憶之前的分類器的狀態,在這個基礎上訓練新的分類器,從而結合歷史影響,但是這樣需要大量歷史分類器
2.重用分類器,只用一個分類器總結狀態,其他分類器接受對應時間的訓練,然後傳遞狀態,這樣就避免了需要大量歷史分類器,而且還比較有效的解決了這個問題。而這樣一種東西是什麼呢?沒錯,就是 RNN(迴圈神經網路)
RNN 之所以稱為迴圈神經網路,是因為一個序列當前的輸出與前面的輸出有關。具體的表現形式為網路會對前面的資訊進行記憶並應用於當前輸出的計算中,即隱藏層之間的節點不再無連線而是有連線的,也就是說隱藏層的輸入不僅包括輸入層的輸出還包括上一時刻隱藏層的輸出。
下麵是一個典型的RNN模型:

研究一下模型的輸入和輸出。以輸入句子為例,輸入的句子中第t個單詞進行Embedding之後的向量表達作為網路t時刻的輸入,而輸入層神經元個數和Embedding的向量長度相符。每個時刻的輸出是一個機率分佈向量,其中最大值的下標決定了輸出哪個詞。如果輸入的序列中有4個單詞,那麼,橫向展開網路後將有四個神經網路,一個網路對應一個單詞,即RNN是在time_step上進行拓展。
下麵解釋一下圖中的計算公式:
· Xt是在時刻t時的輸入。例如,X2對應於一個句子的第二個詞的實數向量。
· St是在時刻t時的隱藏狀態,類似於網路的“大腦”,也就是“記憶模組”的值。St的運算是基於以前隱藏狀態St-1和當前的輸入Xt決定,其中,f通常是非線性的,例如,tanh、ReLU函式。在計算第一個隱藏狀態時,初始值通常設為0。

· Ot是時刻t時的輸出結果。如推測句子中的下一個詞時,這裡的輸出就可以表示為一個詞典序列,值為每一個詞的機率。

需要註意的是:
1. RNN是在時間上共享引數。這意味著這個模型在每個時間步上對輸入的處理是一樣的,只是輸入不同。這樣的方式大幅降低了需要學習的引數總數,減少了很多計算量。深度學習是怎麼減少引數的,很大原因就是引數共享,其中像CNN 是在空間上共享引數,RNN 是在時間上(順序上)共享引數。
2. 在上面的圖片中顯示,不同的時間節點會產生不同的結構輸出。但是,不同任務中,有一些輸出則是多餘的。例如,在情感分析裡,我們只關心這個句子最終表達的情緒,而不是每一個單詞表達的情緒。同樣的,也不是必須得在每一個時間點都有輸入。
這就產生了RNN的不同架構,下麵是幾種RNN 組成的常用架構。

1是普通的單個神經網路,2是把單一輸入轉化為序列輸出,3是把序列輸入轉化為單個輸出,4是把序列轉化為序列,也就是 seq2seq的做法,5是無時差的序列到序列轉化,可以作為普通的語言模型。
下麵再說說幾個比較重要的架構:
One to many:
這種情況有兩種方式,一種是隻在序列開始進行輸入計算。
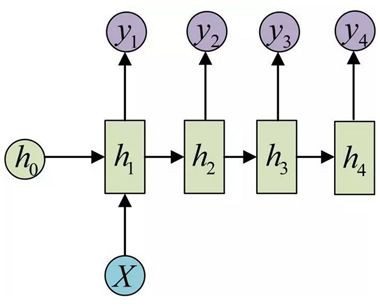
還有一種結構是把輸入資訊 x 作為每個階段的輸入:
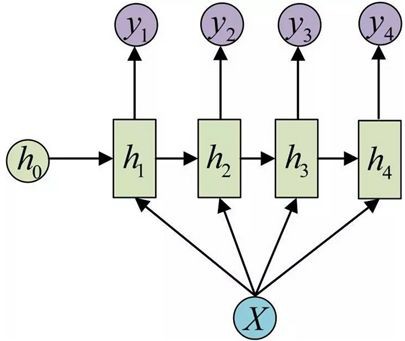
這種one to many的結構可以處理的問題有挺多的,比如圖片標註,輸入的 x 是影象的特徵,而輸出的y序列是一段句子或者從類別生成語音或音樂。
may to one
輸入是一個序列,輸出是一個單獨的值而不是序列。這種結構通常用來處理序列分類問題。如輸入一段文字判別它所屬的類別,輸入一個句子判斷其情感傾向,輸入一段檔案並判斷它的類別等等。具體如下圖:
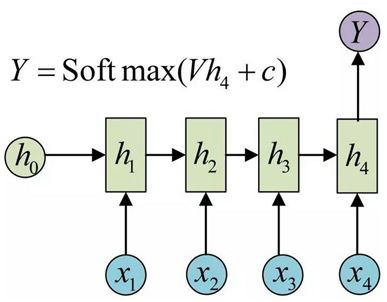
N to N

輸入和輸出序列是等長的。這種可以作為簡單的Char RNN 可以用來生成文章,詩歌,甚至是程式碼,非常有意思)。
N to M
這種結構又叫 Encoder-Decoder 模型,也可以稱之為 Seq2Seq 模型。在實現問題中,我們遇到的大部分序列都是不等長的,如機器翻譯中,源語言和標的語言的句子往往並沒有相同的長度。而 Encoder-Decoder 結構先將輸入資料編碼成一個背景關係向量c,之後在透過這個背景關係向量輸出預測序列。


註意,很多時候只用背景關係向量 C 效果並不是很好,而 attention 技術很大程度彌補了這點。seq2seq的應用的範圍非常廣泛,機器翻譯,文字摘要,閱讀理解,對話生成….。
再來看看訓練演演算法BPTT
如果將 RNN 進行網路展開,那麼引數 W,U,V 是共享的,且在使用梯度下降演演算法中,每一步的輸出不僅依賴當前步的網路,並且還用前面若干步網路的狀態。比如,在t=4時,我們還需要向後傳遞三步,以及後面的三步都需要加上各種的梯度。該學習演演算法稱為Backpropagation Through Time (BPTT)。需要註意的是,在普通 RNN 訓練中,BPTT 無法解決長時依賴問題(即當前的輸出與前面很長的一段序列有關,一般超過十步就無能為力了),因為 BPTT會帶來所謂的梯度消失或梯度爆炸問題(the vanishing/exploding gradient problem)。當然,有很多方法去解決這個問題,如 LSTM、GRU便是專門應對這種問題的。下麵詳細介紹一下BPTT。
考慮最前面介紹的RNN網路結構。
將損失函式定義為交叉熵損失函式:

這裡,我們將一個完整的句子序列視作一個訓練樣本,因此總誤差即為各時間步(單詞)的誤差之和。
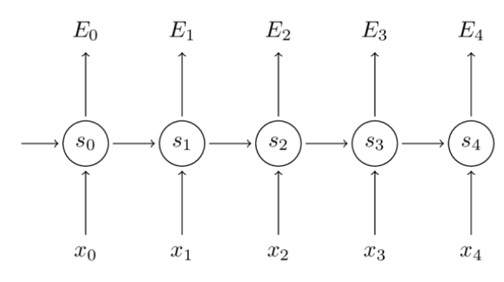
我們的目的是要計算誤差對應的引數U、V和W的梯度,然後藉助SGD演演算法來更新引數。藉助導數的鏈式法則來計算梯度,從最後一層將誤差向前傳播的思想。

誤差函式E對引數V的求導與輸入的序列特性沒有關係。但是,對引數W的求導則不同。最後可以化成:

可以從這張圖直觀瞭解BPTT。

前面就提到BPTT容易帶來梯度消失或梯度爆炸的問題,可以從下圖直觀看出。

我們看看梯度消失的情況,梯度值迅速以指數形式收縮,最終在幾個時間步長後完全消失。“較遠”的時間步長貢獻的梯度變為0,這些時間段的狀態不會對你的學習有所貢獻:你最終還是無法學習長期依賴。梯度消失不僅存在於迴圈神經網路,也出現在深度前饋神經網路中。區別在於,迴圈神經網路非常深(本例中,深度與句長相同),因此梯度消失問題更為常見。RNN的梯度是非常不穩定的,所以梯度在損失錶面的跳躍度是非常大的,也就是說最佳化程式可能將最優值帶到離真實最優值很遠的地方。
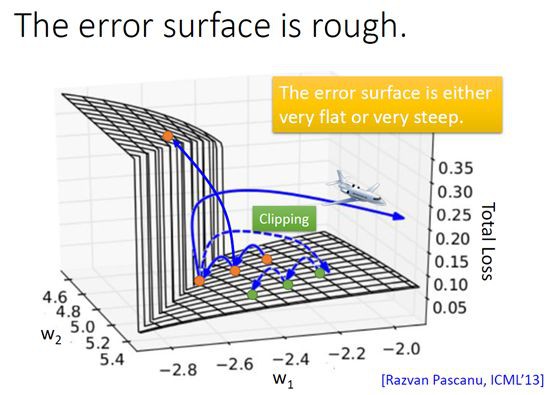
幸運的是,目前有一些方法可解決梯度消失問題。合理初始化矩陣W可緩解梯度消失現象,還可採用正則化方法。此外,更好的方法是使用 ReLU,而非tanh或sigmoid啟用函式(梯度消失有一部分原因是因為啟用函式一些性質造成的)。ReLU函式的導數是個常量,0或1,因此不太可能出現梯度消失現象。
更常用的方法是藉助LSTM或GRU架構。1997年,首次提出LSTM,目前該模型在NLP領域的應用極其廣泛。GRU則於2014年問世,是LSTM的簡化版。這些迴圈神經網路旨在解決梯度消失和有效學習長期依賴問題。
先來看看LSTM。
LSTM透過引入一個叫做“門”(gating)的機制來緩解梯度消失問題。首先,我們要註意LSTM層僅僅是計算隱藏層的另一種方式。
在傳統的RNN中,我們用S_t = tanh(Ux_t + Ws_)這個式子來計算隱藏層。其中,隱藏層的輸入單元有兩個,一個是當前時刻t的輸入x_t以及前一時刻的隱藏狀態s_。LSTM單元的功能與之相同,只是方式不同而已。這是理解LSTM的關鍵。你基本上可將LSTB(和GRU)單元視為黑匣子,只要你給定當前輸入和前一時刻的隱藏狀態,便可計算出下一隱藏狀態。如下圖:

LSTM的內部結構:
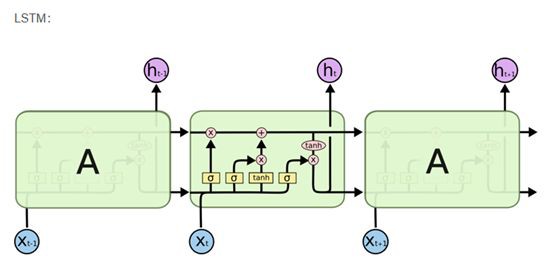
LSTM比RNN多了一個細胞狀態,就是最上面一條線,像一個傳送帶,它讓資訊在這條線上傳播而不改變資訊。
LSTM可以自己增加或移除資訊,透過“門”的結構控制。
“門”選擇性地讓資訊是否透過,“門”包括一個sigmoid層和按元素乘。如下圖:

sigmoid層輸出0-1的值,表示讓多少資訊透過,1表示讓所有的資訊都透過。
一個LSTM單元有3個門。三個sigmoid層是三個門:忘記門、輸入門、輸出門。

忘記門:扔掉資訊(細胞狀態)
第一步是決定從細胞狀態裡扔掉什麼資訊(也就是保留多少資訊)。將上一步細胞狀態中的資訊選擇性的遺忘 。
實現方式:透過sigmoid層實現的“忘記門”。以上一步的ht−1和這一步的xt
作為輸入,然後為Ct−1裡的每個數字輸出一個0-1間的值,表示保留多少資訊(1代表完全保留,0表示完全捨棄),然後與Ct−1乘。
例子:讓我們回到語言模型的例子中來基於已經看到的預測下一個詞。在這個問題中,細胞狀態可能包含當前主語的類別,因此正確的代詞可以被選擇出來。當我們看到新的主語,我們希望忘記舊的主語。
例如,他今天有事,所以我…… 當處理到“我”的時候選擇性的忘記前面的“他”,或者說減小這個詞對後面詞的作用。

輸入層門:儲存資訊(細胞狀態)
第二步是決定在細胞狀態裡存什麼。將新的資訊選擇性的記錄到細胞狀態中。
實現方式:包含兩部分,1. sigmoid層(輸入門層)決定我們要更新什麼值;2. tanh層建立一個候選值向量Ct~,將會被增加到細胞狀態中。 我們將會在下一步把這兩個結合起來更新細胞狀態。
例子:在我們語言模型的例子中,我們希望增加新的主語的類別到細胞狀態中,來替代舊的需要忘記的主語。 例如:他今天有事,所以我…… 當處理到“我”這個詞的時候,就會把主語我更新到細胞中去。

更新細胞狀態(細胞狀態)
更新舊的細胞狀態
實現方式:Ct=ft∗Ct−1+it∗Ct~,ft表示保留上一次的多少資訊,it表示更新哪些值,Ct~表示新的候選值。候選值被要更新多少(即it)放縮。
這一步我們真正實現了移除哪些舊的資訊(比如一句話中上一句的主語),增加哪些新資訊。

輸出層門:輸出(隱藏狀態)
最後,我們要決定作出什麼樣的預測。
實現方式:1. 我們透過sigmoid層(輸出層門)來決定輸出新的細胞狀態的哪些部分;2. 然後我們將細胞狀態透過tanh層(使值在-1~1之間),然後與sigmoid層的輸出相乘。
所以我們只輸出我們想輸出的部分。
例子:在語言模型的例子中,因為它就看到了一個代詞,可能需要輸出與一個 動詞相關的資訊。例如,可能輸出是否代詞是單數還是複數,這樣如果是動詞的話,我們也知道動詞需要進行的詞形變化。
例如:上面的例子,當處理到“我”這個詞的時候,可以預測下一個詞,是動詞的可能性較大,而且是第一人稱。 會把前面的資訊儲存到隱層中去。

LSTM反向傳播比較麻煩。



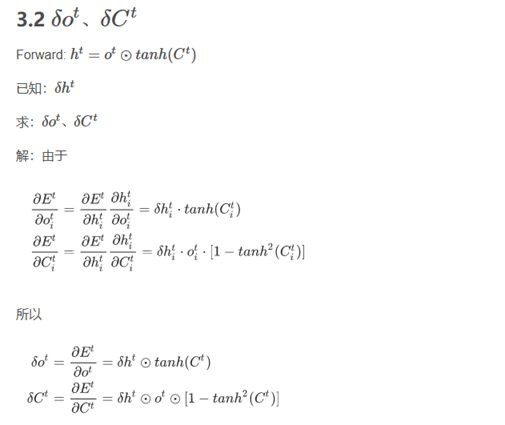

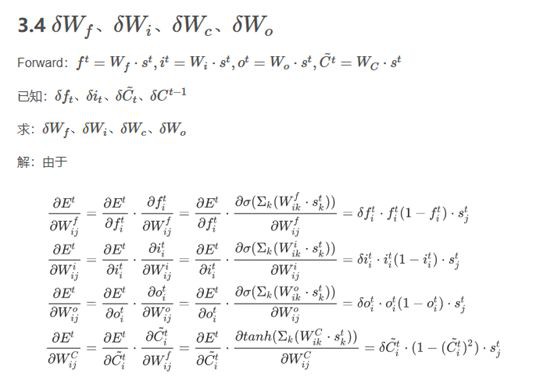





接下來是GRU模型。理解了LSTM的話,GRU就簡單了,GRU可以說是LSTM的簡化版。其原理與LSTM非常相似,方程式也幾乎相同,如下:

GRU有兩個門:重置(reset)門r和更新(update)門z。直觀來講,重置門決定了新的輸入與前一時刻記憶的組合方式,更新門則決定了先前記憶資訊的保留程度。如果將所有重置門設為1,所有更新門設為0,即可再次得到傳統的RNN模型。
我們發現,GRU中用門機制來實現學習長期記憶的基本原理與LSTM相同,但也有一些區別:
· GRU有兩個門,而LSTM有三個門。
· GRU中不存在區別於內部記憶單元(c_t),也沒有LSTM中的輸出門。
· LSTM的輸入門和遺忘門,在GRU中被整合成一個更新門z;而重置門r被直接用到前一個隱藏狀態上面了。
經過實驗,一般認為,LSTM和GRU之間並沒有明顯的優勝者。因為GRU具有較少的引數,所以訓練速度快,而且所需要的樣本也比較少。而LSTM具有較多的引數,比較適合具有大量樣本的情況,可能會獲得較優的模型。
對於我們,其實瞭解一下模型的輸入輸出也就差不多了,哈哈!
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
