(點選上方公眾號,可快速關註)
編譯: oschina 英文:towardsdatascience
www.oschina.net/translate/5-quick-and-easy-data-visualizations-in-python?print
資料視覺化是資料科學家工作中的重要組成部分。在專案的早期階段,你通常會進行探索性資料分析(Exploratory Data Analysis,EDA)以獲取對資料的一些理解。建立視覺化方法確實有助於使事情變得更加清晰易懂,特別是對於大型、高維資料集。在專案結束時,以清晰、簡潔和引人註目的方式展現最終結果是非常重要的,因為你的受眾往往是非技術型客戶,只有這樣他們才可以理解。
Matplotlib 是一個流行的 Python 庫,可以用來很簡單地建立資料視覺化方案。但每次建立新專案時,設定資料、引數、圖形和排版都會變得非常繁瑣和麻煩。在這篇博文中,我們將著眼於 5 個資料視覺化方法,並使用 Python Matplotlib 為他們編寫一些快速簡單的函式。與此同時,這裡有一個很棒的圖表,可用於在工作中選擇正確的視覺化方法!

散點圖非常適合展示兩個變數之間的關係,因為你可以直接看到資料的原始分佈。 如下麵第一張圖所示的,你還可以透過對組進行簡單地顏色編碼來檢視不同組資料的關係。想要視覺化三個變數之間的關係? 沒問題! 僅需使用另一個引數(如點大小)就可以對第三個變數進行編碼,如下麵的第二張圖所示。


現在開始討論程式碼。我們首先用別名 “plt” 匯入 Matplotlib 的 pyplot 。要建立一個新的點陣圖,我們可呼叫 plt.subplots() 。我們將 x 軸和 y 軸資料傳遞給該函式,然後將這些資料傳遞給 ax.scatter() 以繪製散點圖。我們還可以設定點的大小、點顏色和 alpha 透明度。你甚至可以設定 Y 軸為對數刻度。標題和坐標軸上的標簽可以專門為該圖設定。這是一個易於使用的函式,可用於從頭到尾建立散點圖!
import matplotlib.pyplot as pltimport numpy as npdef scatterplot(x_data, y_data, x_label=“”, y_label=“”, title=“”, color = “r”,yscale_log=False):
# Create the plot object
_, ax = plt.subplots() # Plot the data, set the size (s), color and transparency (alpha)
# of the points
ax.scatter(x_data, y_data, s = 10, color = color, alpha = 0.75) if yscale_log == True:
ax.set_yscale(‘log’) # Label the axes and provide a title
ax.set_title(title)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
折線圖
當你可以看到一個變數隨著另一個變數明顯變化的時候,比如說它們有一個大的協方差,那最好使用折線圖。讓我們看一下下麵這張圖。我們可以清晰地看到對於所有的主線隨著時間都有大量的變化。使用散點繪製這些將會極其混亂,難以真正明白和看到發生了什麼。折線圖對於這種情況則非常好,因為它們基本上提供給我們兩個變數(百分比和時間)的協方差的快速總結。另外,我們也可以透過彩色編碼進行分組。
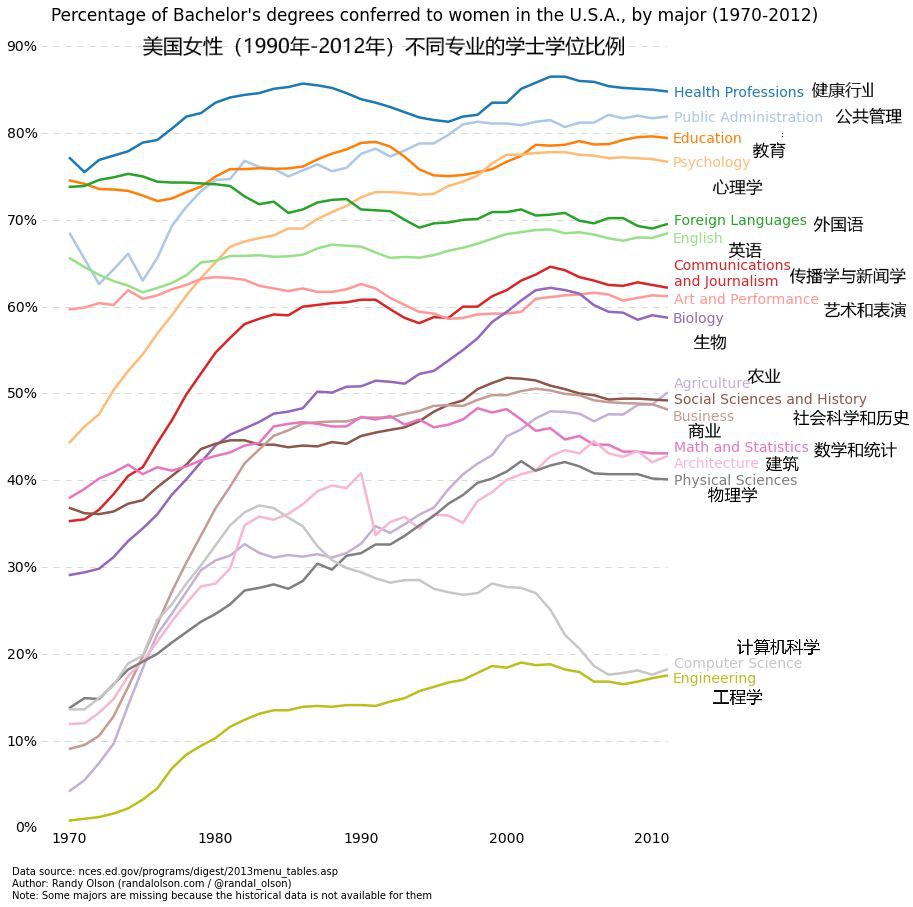
這裡是折線圖的程式碼。它和上面的散點圖很相似,只是在一些變數上有小的變化。
def lineplot(x_data, y_data, x_label=“”, y_label=“”, title=“”):
# Create the plot object
_, ax = plt.subplots() # Plot the best fit line, set the linewidth (lw), color and
# transparency (alpha) of the line
ax.plot(x_data, y_data, lw = 2, color = ‘#539caf’, alpha = 1) # Label the axes and provide a title
ax.set_title(title)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
直方圖
直方圖對於檢視(或真正地探索)資料點的分佈是很有用的。檢視下麵我們以頻率和 IQ 做的直方圖。我們可以清楚地看到朝中間聚集,並且能看到中位數是多少。我們也可以看到它呈正態分佈。使用直方圖真得能清晰地呈現出各個組的頻率之間的相對差別。組的使用(離散化)真正地幫助我們看到了“更加宏觀的圖形”,然而當我們使用所有沒有離散組的資料點時,將對視覺化可能造成許多幹擾,使得看清真正發生了什麼變得困難。
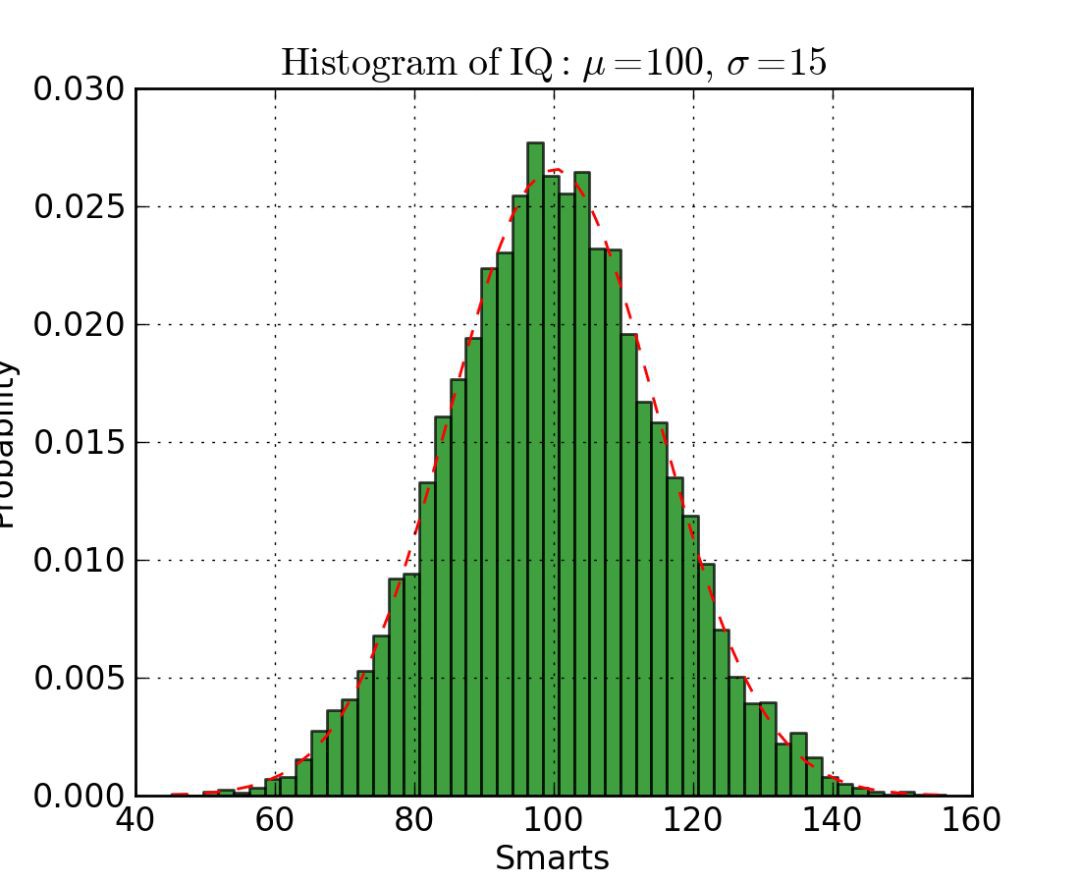
下麵是在 Matplotlib 中的直方圖程式碼。有兩個引數需要註意一下:首先,引數 n_bins 控制我們想要在直方圖中有多少個離散的組。更多的組將給我們提供更加完善的資訊,但是也許也會引進幹擾,使得我們遠離全域性;另一方面,較少的組給我們一種更多的是“鳥瞰圖”和沒有更多細節的全域性圖。其次,引數 cumulative 是一個布林值,允許我們選擇直方圖是否為累加的,基本上就是選擇是 PDF(Probability Density Function,機率密度函式)還是 CDF(Cumulative Density Function,累積密度函式)。
def histogram(data, n_bins, cumulative=False, x_label = “”, y_label = “”, title = “”):
_, ax = plt.subplots()
ax.hist(data, n_bins = n_bins, cumulative = cumulative, color = ‘#539caf’)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
想象一下我們想要比較資料中兩個變數的分佈。有人可能會想你必須製作兩張直方圖,並且把它們併排放在一起進行比較。然而,實際上有一種更好的辦法:我們可以使用不同的透明度對直方圖進行疊加改寫。看下圖,均勻分佈的透明度設定為 0.5 ,使得我們可以看到他背後的圖形。這樣我們就可以直接在同一張圖表裡看到兩個分佈。
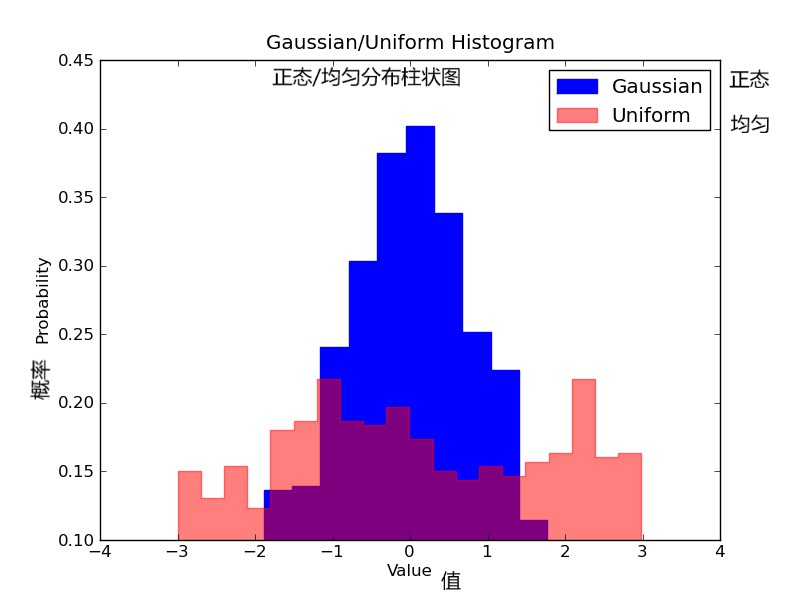
對於重疊的直方圖,需要設定一些東西。首先,我們設定可同時容納不同分佈的橫軸範圍。根據這個範圍和期望的組數,我們可以真正地計算出每個組的寬度。最後,我們在同一張圖上繪製兩個直方圖,其中有一個稍微更透明一些。
# Overlay 2 histograms to compare themdef overlaid_histogram(data1, data2, n_bins = 0, data1_name=””, data1_color=”#539caf”, data2_name=””, data2_color=”#7663b0″, x_label=””, y_label=””, title=””):
# Set the bounds for the bins so that the two distributions are fairly compared
max_nbins = 10
data_range = [min(min(data1), min(data2)), max(max(data1), max(data2))]
binwidth = (data_range[1] – data_range[0]) / max_nbins if n_bins == 0
bins = np.arange(data_range[0], data_range[1] + binwidth, binwidth) else:
bins = n_bins # Create the plot
_, ax = plt.subplots()
ax.hist(data1, bins = bins, color = data1_color, alpha = 1, label = data1_name)
ax.hist(data2, bins = bins, color = data2_color, alpha = 0.75, label = data2_name)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = ‘best’)
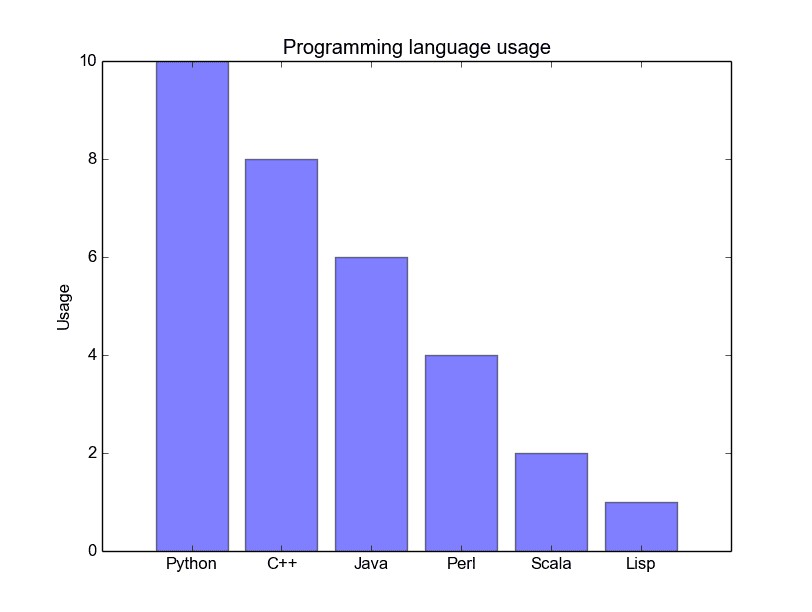
柱狀圖
當你試圖將類別很少(可能小於10)的分類資料視覺化的時候,柱狀圖是最有效的。如果我們有太多的分類,那麼這些柱狀圖就會非常雜亂,很難理解。柱狀圖對分類資料很好,因為你可以很容易地看到基於柱的類別之間的區別(比如大小);分類也很容易劃分和用顏色進行編碼。我們將會看到三種不同型別的柱狀圖:常規的,分組的,堆疊的。在我們進行的過程中,請檢視圖形下麵的程式碼。
常規的柱狀圖如下麵的圖1。在 barplot() 函式中,xdata 表示 x 軸上的標記,ydata 表示 y 軸上的桿高度。誤差條是一條以每條柱為中心的額外的線,可以畫出標準偏差。
分組的柱狀圖讓我們可以比較多個分類變數。看看下麵的圖2。我們比較的第一個變數是不同組的分數是如何變化的(組是G1,G2,……等等)。我們也在比較性別本身和顏色程式碼。看一下程式碼,y_data_list 變數實際上是一個 y 元素為串列的串列,其中每個子串列代表一個不同的組。然後我們對每個組進行迴圈,對於每一個組,我們在 x 軸上畫出每一個標記;每個組都用彩色進行編碼。
堆疊柱狀圖可以很好地觀察不同變數的分類。在圖3的堆疊柱狀圖中,我們比較了每天的伺服器負載。透過顏色編碼後的堆疊圖,我們可以很容易地看到和理解哪些伺服器每天工作最多,以及與其他伺服器進行比較負載情況如何。此程式碼的程式碼與分組的條形圖相同。我們迴圈遍歷每一組,但這次我們把新柱放在舊柱上,而不是放在它們的旁邊。


def barplot(x_data, y_data, error_data, x_label=“”, y_label=“”, title=“”):
_, ax = plt.subplots()
# Draw bars, position them in the center of the tick mark on the x-axis
ax.bar(x_data, y_data, color = ‘#539caf’, align = ‘center’)
# Draw error bars to show standard deviation, set ls to ‘none’
# to remove line between points
ax.errorbar(x_data, y_data, yerr = error_data, color = ‘#297083’, ls = ‘none’, lw = 2, capthick = 2)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
def stackedbarplot(x_data, y_data_list, colors, y_data_names=“”, x_label=“”, y_label=“”, title=“”):
_, ax = plt.subplots()
# Draw bars, one category at a time
for i in range(0, len(y_data_list)):
if i == 0:
ax.bar(x_data, y_data_list[i], color = colors[i], align = ‘center’, label = y_data_names[i])
else:
# For each category after the first, the bottom of the
# bar will be the top of the last category
ax.bar(x_data, y_data_list[i], color = colors[i], bottom = y_data_list[i – 1], align = ‘center’, label = y_data_names[i])
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = ‘upper right’)
def groupedbarplot(x_data, y_data_list, colors, y_data_names=“”, x_label=“”, y_label=“”, title=“”):
_, ax = plt.subplots()
# Total width for all bars at one x location
total_width = 0.8
# Width of each individual bar
ind_width = total_width / len(y_data_list)
# This centers each cluster of bars about the x tick mark
alteration = np.arange(–(total_width/2), total_width/2, ind_width)
# Draw bars, one category at a time
for i in range(0, len(y_data_list)):
# Move the bar to the right on the x-axis so it doesn’t
# overlap with previously drawn ones
ax.bar(x_data + alteration[i], y_data_list[i], color = colors[i], label = y_data_names[i], width = ind_width)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = ‘upper right’)
箱形圖
我們之前看了直方圖,它很好地可視化了變數的分佈。但是如果我們需要更多的資訊呢?也許我們想要更清晰的看到標準偏差?也許中值與均值有很大不同,我們有很多離群值?如果有這樣的偏移和許多值都集中在一邊呢?
這就是箱形圖所適合乾的事情了。箱形圖給我們提供了上面所有的資訊。實線框的底部和頂部總是第一個和第三個四分位(比如 25% 和 75% 的資料),箱體中的橫線總是第二個四分位(中位數)。像鬍鬚一樣的線(虛線和結尾的條線)從這個箱體伸出,顯示資料的範圍。
由於每個組/變數的框圖都是分別繪製的,所以很容易設定。xdata 是一個組/變數的串列。Matplotlib 庫的 boxplot() 函式為 ydata 中的每一列或每一個向量繪製一個箱體。因此,xdata 中的每個值對應於 ydata 中的一個列/向量。我們所要設定的就是箱體的美觀。
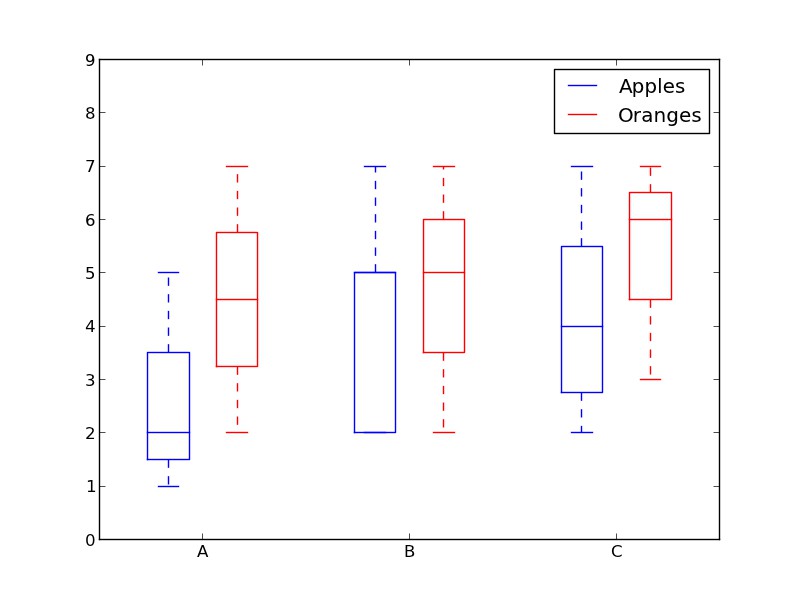
def boxplot(x_data, y_data, base_color=“#539caf”, median_color=“#297083”, x_label=“”, y_label=“”, title=“”):
_, ax = plt.subplots()
# Draw boxplots, specifying desired style
ax.boxplot(y_data
# patch_artist must be True to control box fill
, patch_artist = True
# Properties of median line
, medianprops = {‘color’: median_color}
# Properties of box
, boxprops = {‘color’: base_color, ‘facecolor’: base_color}
# Properties of whiskers
, whiskerprops = {‘color’: base_color}
# Properties of whisker caps
, capprops = {‘color’: base_color})
# By default, the tick label starts at 1 and increments by 1 for
# each box drawn. This sets the labels to the ones we want
ax.set_xticklabels(x_data)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
結語
使用 Matplotlib 有 5 個快速簡單的資料視覺化方法。將相關事務抽象成函式總是會使你的程式碼更易於閱讀和使用!我希望你喜歡這篇文章,並且學到了一些新的有用的技巧。如果你確實如此,請隨時給它點贊。
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能

