TextRank演演算法基於PageRank,用於為文字生成關鍵字和摘要。
目錄[-]
-
PageRank
-
使用TextRank提取關鍵字
-
使用TextRank提取關鍵短語
-
使用TextRank提取摘要
-
實現TextRank
TextRank演演算法基於PageRank,用於為文字生成關鍵字和摘要。其論文是:
Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]. Association for Computational Linguistics, 2004.
先從PageRank講起。
PageRank
PageRank最開始用來計算網頁的重要性。整個www可以看作一張有向圖圖,節點是網頁。如果網頁A存在到網頁B的連結,那麼有一條從網頁A指向網頁B的有向邊。
構造完圖後,使用下麵的公式: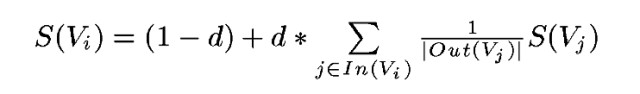
S(Vi)是網頁i的中重要性(PR值)。d是阻尼繫數,一般設定為0.85。In(Vi)是存在指向網頁i的連結的網頁集合。Out(Vj)是網頁j中的連結存在的連結指向的網頁的集合。|Out(Vj)|是集合中元素的個數。
PageRank需要使用上面的公式多次迭代才能得到結果。初始時,可以設定每個網頁的重要性為1。上面公式等號左邊計算的結果是迭代後網頁i的PR值,等號右邊用到的PR值全是迭代前的。
舉個例子:
上圖表示了三張網頁之間的連結關係,直覺上網頁A最重要。可以得到下麵的表:
| 結束\起始 |
A |
B |
C |
| A |
0 |
1 |
1 |
| B |
0 |
0 |
0 |
| C |
0 |
0 |
0 |
橫欄代表其實的節點,縱欄代表結束的節點。若兩個節點間有連結關係,對應的值為1。
根據公式,需要將每一豎欄歸一化(每個元素/元素之和),歸一化的結果是:
| 結束\起始 |
A |
B |
C |
| A |
0 |
1 |
1 |
| B |
0 |
0 |
0 |
| C |
0 |
0 |
0 |
上面的結果構成矩陣M。我們用matlab迭代100次看看最後每個網頁的重要性:
?
|
1 2 3 4 5 6 7 8 9 10 11 |
|
執行結果(省略部分):
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
|
最終A的PR值為0.4050,B和C的PR值為0.1500。
如果把上面的有向邊看作無向的(其實就是雙向的),那麼:
?
|
1 2 3 4 5 6 7 8 9 10 11 |
|
執行結果(省略部分):
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
依然能判斷出A、B、C的重要性。
使用TextRank提取關鍵字
將原文字拆分為句子,在每個句子中過濾掉停用詞(可選),並只保留指定詞性的單詞(可選)。由此可以得到句子的集合和單詞的集合。
每個單詞作為pagerank中的一個節點。設定視窗大小為k,假設一個句子依次由下麵的單片語成:
w1, w2, w3, w4, w5, ..., wn
w1, w2, …, wk、w2, w3, …,wk+1、w3, w4, …,wk+2等都是一個視窗。在一個視窗中的任兩個單詞對應的節點之間存在一個無向無權的邊。
基於上面構成圖,可以計算出每個單詞節點的重要性。最重要的若干單詞可以作為關鍵詞。
使用TextRank提取關鍵短語
參照“使用TextRank提取關鍵詞”提取出若干關鍵詞。若原文字中存在若干個關鍵詞相鄰的情況,那麼這些關鍵詞可以構成一個關鍵短語。
例如,在一篇介紹“支援向量機”的文章中,可以找到三個關鍵詞支援、向量、機,透過關鍵短語提取,可以得到支援向量機。
使用TextRank提取摘要
將每個句子看成圖中的一個節點,若兩個句子之間有相似性,認為對應的兩個節點之間有一個無向有權邊,權值是相似度。
透過pagerank演演算法計算得到的重要性最高的若干句子可以當作摘要。
論文中使用下麵的公式計算兩個句子Si和Sj的相似度: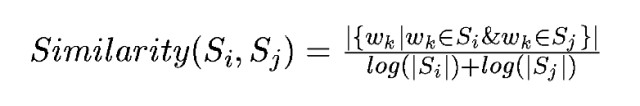
分子是在兩個句子中都出現的單詞的數量。|Si|是句子i的單詞數。
由於是有權圖,PageRank公式略做修改:
實現TextRank
因為要用測試多種情況,所以自己實現了一個基於Python 2.7的TextRank針對中文文字的庫TextRank4ZH。位於:
https://github.com/someus/TextRank4ZH
下麵是一個例子:

執行結果如下:
?
|
1 2 3 4 5 6 7 8 |
|
另外, jieba分詞提供的基於TextRank的關鍵詞提取工具。 snownlp也實現了關鍵詞提取和摘要生成。
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

腳印英語,專註於分享實用口語內容。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
