點選藍字

關註我們
這篇文章適合於python純小白,裡面可能很多陳述句是冗長的,甚至可能有一些尚未發現的BUG,這個伴隨著我們繼續學習來慢慢消解吧。接下來 我把裡面會用到的東西在這裡做一個總結吧:
用到的模組requests,re,os,jieba,glob,json,lxml,pyecharts,heapq,collection
找到需要爬取的內容,分析網頁,抓包檢視互動內容
首先我們先進入到我們需要抓取的內容的地址。http://music.163.com/# 這是網易雲音樂的首頁,我們的目的是抓取周傑倫的所有歌曲,歌詞,已經評論,那我們在搜尋處輸入周傑倫
我們第一步抓取所有專輯 進入http://music.163.com/#/artist/album?id=6452如下圖所示!

在谷歌的抓包工具(F12)裡面檢視互動資訊發現如下:
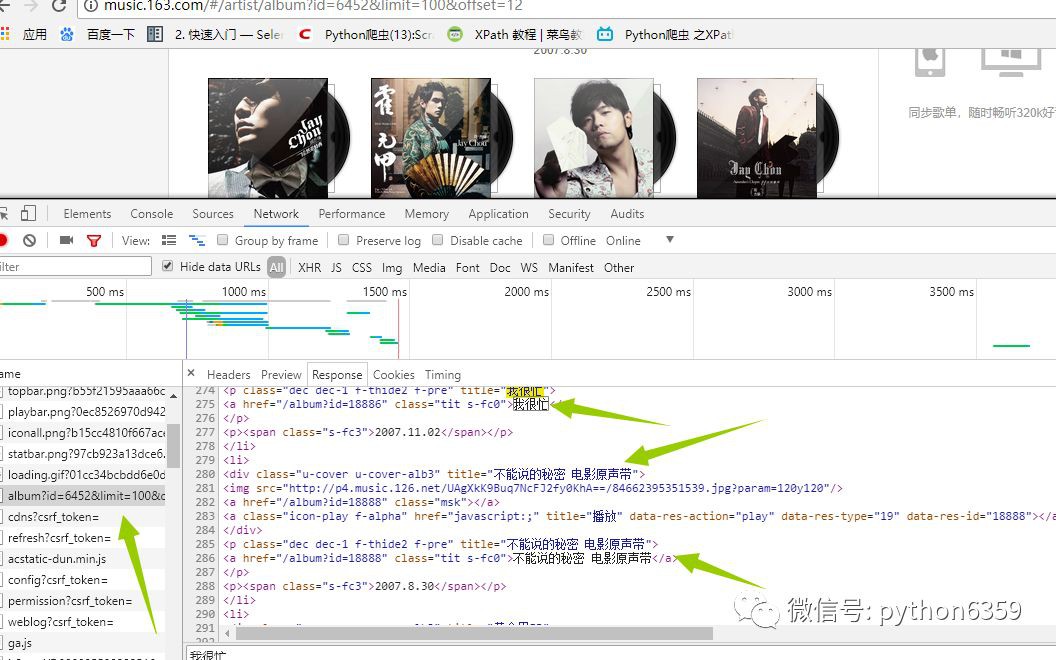
這就是我們想要的資訊,那事情就變得簡單的,我們沒必要用複雜的工具比如(selenium)去載入整個頁面,(事實上,如果還沒想到抓取歌曲的方法,我估計就得用它了),我們再看essay-header裡面有什麼

這裡面的string我們不用管了,因為它已經在我們的url裡面了,我們只需要看request essay-headers 這個就是我們給伺服器傳送的東西,傳送之後,伺服器傳回給我們的就是network裡面的資訊。好,接下來我們偽造瀏覽器傳送請求。具體程式碼如下:

這裡面用到了xpath來找到對應標簽裡面資料,程式碼不重要,思想懂了就行(程式碼單獨執行可行)
執行結果如下

抓取歌曲資訊

同樣的道理我們透過偽造方式傳送資訊,獲取歌曲資訊!!直接上程式碼

上面需要註意:xpath來獲取需要的資訊,利用正則來獲取ID(其實有很多方法)


一樣的道理,我們分析network來獲取我們需要的資訊歌詞,評論!!直接上程式碼

上面需要註意的是:利用json獲取需要的資料(至少比正則快點)

資料分析,視覺化

上面需要註意的是:我們合併資料的時候,可以選擇性的刪除一些無用資料

下麵我們對周傑倫歌曲進行情緒化分析

下麵完成資料詞頻各種分析

我們來看下結果






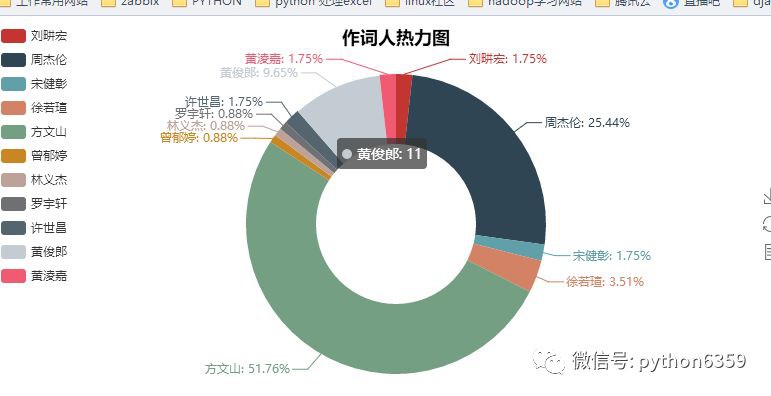
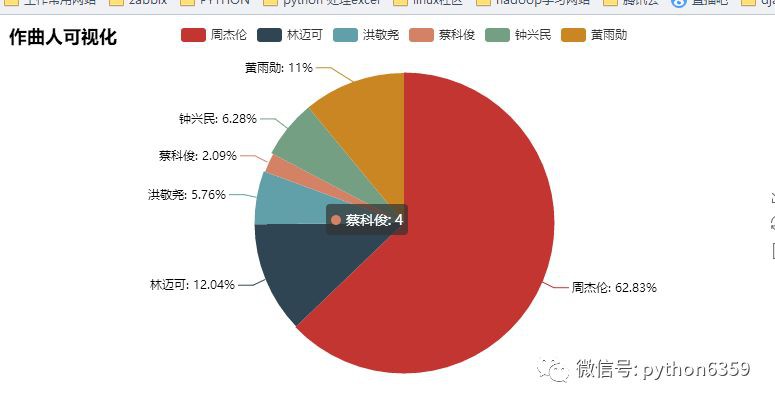



作者:zfno11
源自:www.cnblogs.com/ZFBG/p/8947541.html
