來自:51CTO技術棧(微訊號:blog51cto)
作者:甘兵,編輯:陶家龍、孫淑娟
連結:http://blog.51cto.com/ganbing/2105842
IT 運維工程師一直是個“苦逼”的職業,“鋤禾日當午,不如運維苦,對著破電腦,一調一下午”是對運維工作的一個形象的描述。下麵看看本文作者一次驚心肉跳的資料庫遷移經歷。

事件起源
整個事件的起源還要從我最近入職了一家區塊鏈金融公司說起,公司業務發展比較迅猛,突破百萬使用者也是近在眼前。
整個系統都在阿裡雲上執行,每天都能看到使用者的不斷增長,即興奮又擔憂,為什麼這麼說呢?
由於我過來的時候,公司業務就已經上線了,系統接過來之後,快速瞭解了所有的應用服務都是在 Docker Swarm 跑起來的,也包括 MySQL 資料庫。
按照這種使用者量發展下去,MySQL 在容器中執行用不了多久肯定會撐不住,以至於我就有了遷庫的想法。
我開始隱隱的擔憂起來,畢竟不想每天提心吊膽的做運維。所以立即重新規劃了新的方案和大家一起探討。
最終總監和相關技術負責人都敲定用 RDS 做為資料庫新的方案,周星馳的功夫中也說到:“天下武功,唯快不破”,於是就開始幹起來。
遷移計劃
原架構圖
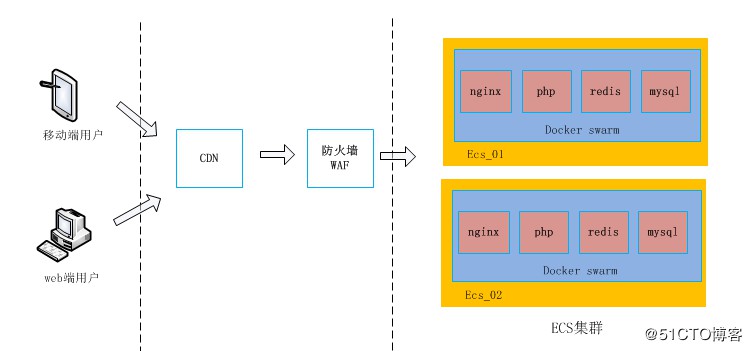
如上圖所示,分析一下原來的架構圖:
-
從入口層(CDN)→到安全層(WAF)→最後到達應用層 (ECS叢集)。
-
Docker Swarm 打通了 ECS 叢集中的每臺伺服器,在每臺 ECS 宿主機安裝 Docker engine 並部署了公司需要的應用服務和資料庫(Nginx、PHP、Redis、MySQL等)。
-
MySQL 容器透過本檔案掛載到容器中實現資料持久化。
-
業務專案以 PHP 為主,PHP 也是執行在容器中,透過 PHP 指定的配置檔案連線到 MySQL 容器中。
隨便展示一下其中一個庫的 docker-compose yaml 檔案:
version: "3"
services:
ussbao:
# replace username/repo:tag with your name and image details
image: 隱藏此映象資訊
deploy:
replicas: 1
restart_policy:
condition: on-failure
environment:
MYSQL_ROOT_PASSWORD: 隱藏此資訊
volumes:
- "/data//mysql/db1/:/var/lib/mysql/"
- "/etc/localtime:/etc/localtime"
- "/etc/timezone:/etc/timezone"
networks:
default:
external:
name: 隱藏此資訊
從上面的資訊可以看出來,每個庫只運行了一個 MySQL 容器,並沒有主從或讀寫分離的方案。
而且也沒有對資料庫做任何最佳化,資料庫這樣跑下去讓筆者很擔憂,正常來說,都會把資料庫獨立部署執行。
調整後架構圖
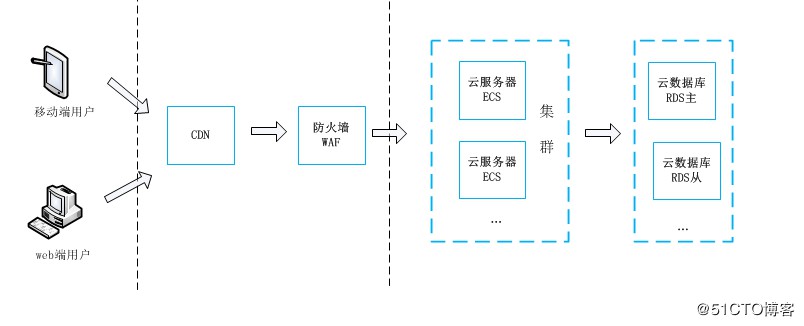
從上圖可以看出來,筆者只是把 MySQL 獨立出來了,開通 RDS 實體來跑資料庫,當然還開通了其他的一些服務(比如 OSS、雲 Redis 等),這些不是本文的重點,就沒有畫出來。
Nginx 和 PHP 服務還是在 Docker Swarm 中執行。本文只是對遷移後出了問題的庫進行分享,下麵來看看遷移的方案吧。
遷移流程方案
遷移流程的方案:開通 RDS 實體→備份 SQL→匯入到 RDS→修改資料庫配置檔案→測試驗證。
遷移步驟如下:
-
根據業務量規劃開通 RDS 實體,建立資料庫和使用者
-
提前做好 RDS 白名單,新增允許訪問 RDS 的 IP 地址
-
mysqldump 備份 Docker 中的 MySQL
-
把備份好的 .sql 檔案匯入到 RDS 中
-
修改 PHP 專案的資料庫配置檔案
-
清空 PHP 專案的快取檔案或目錄
-
測試驗證
-
RDS 定時備份
具體遷移細節就不展示了,我是在夜深人靜的時候進行遷移操作的,確定大半夜沒人訪問我們的 App 和網站了才開乾的。
我們的業務情況有點像股市,我們是晚上 12 點不許操作和交易,第 2 天早上 9 點開盤,9 點鐘是併發的高峰期,就像朝陽大悅城上午開門一樣,大批的顧客同時併發過來了。
所以那天晚上在 12 點 15 分準時開乾,按計劃和提前準備的配置、命令、指令碼進行操作的。
把 Docker 中執行的 MySQL 遷移到 RDS 上非常順利,好幾個庫的遷移不到半個小時就結束了,並且把網站和 App 的流程都跑了一遍,也都是妥妥的。
最終把提前準備好的備份指令碼放在 crontab 中定時執行,可以看下指令碼內容:
#!/bin/bash
#資料庫IP
dbserver='*******'
#資料庫使用者名稱
dbuser='ganbing'
#資料庫密碼
dbpasswd='************'
#備份資料庫,多個庫用空格隔開
dbname='db1 db2 db3'
#備份時間
backtime=`date +%Y%m%d%H%M`
out_time=`date +%Y%m%d%H%M%S`
#備份輸出路徑
backpath='/data/backup/mysql/'
logpath=''/data/backup/logs/'
echo "################## ${backtime} #############################"
echo "開始備份"
#日誌記錄頭部
echo "" >> ${logpath}/${dbname}_back.log
echo "-------------------------------------------------" >> ${logpath}/${dbname}_back.log
echo "備份時間為${backtime},備份資料庫 ${dbname} 開始" >> ${logpath}/${dbname}_back.log
#正式備份資料庫
for DB in $dbname; do
source=`/usr/bin/mysqldump -h ${dbserver} -u ${dbuser} -p${dbpasswd} ${DB} > ${backpath}/${DB}-${out_time}.sql` 2>> ${backpath}/mysqlback.log;
#備份成功以下操作
if [ "$?" == 0 ];then
cd $backpath
#為節約硬碟空間,將資料庫壓縮
tar zcf ${DB}-${backtime}.tar.gz ${DB}-${backtime}.sql > /dev/null
#刪除原始檔案,只留壓縮後檔案
rm -f ${DB}-${backtime}.sql
#刪除15天前備份,也就是隻儲存15天內的備份
find $backpath -name "*.tar.gz" -type f -mtime +15 -exec rm -rf {} ; > /dev/null 2>&1
echo "資料庫 ${dbname} 備份成功!!" >> ${logpath}/${dbname}_back.log
else
#備份失敗則進行以下操作
echo "資料庫 ${dbname} 備份失敗!!" >> ${logpath}/${dbname}_back.log
fi
done
echo "完成備份"
echo "################## ${backtime} #############################"
到了 1 點鐘,確定沒問題後發通知到群裡,發微信給領導表示已遷移完成,進行很順利,然後筆者打車回家,睡覺。
雪崩來臨
其實這一晚筆者睡得也不踏實,到了 8 點半就醒了,因為我們 9 點鐘開盤,會有大量的客戶湧進,每天開始產生新的交易(買入和賣出),給大家看下截圖:

果不其然,9 點過後,我開啟 App,一切正常,點選切換幾個介面後,發現其中一個功能的請求超時了,一直在轉,然後緊接著其他功能也超時了。
完了,出問題了。趕緊開電腦查問題,過了一會兒群裡就開始沸騰了(反映好多客戶開啟 App 都顯示請求超時了),我的電話也第一時間響了,技術總監打來的,問我怎麼回事,我說正在開電腦排查。
緊急處理
排查問題
電腦開啟後,首先想到的就是 RDS 資料庫出了問題,登入阿裡雲,進入 RDS 中的 DMS 資料管理控制檯,一進去就傻眼了 “CPU 爆了”,這麼多連線數,如下圖:
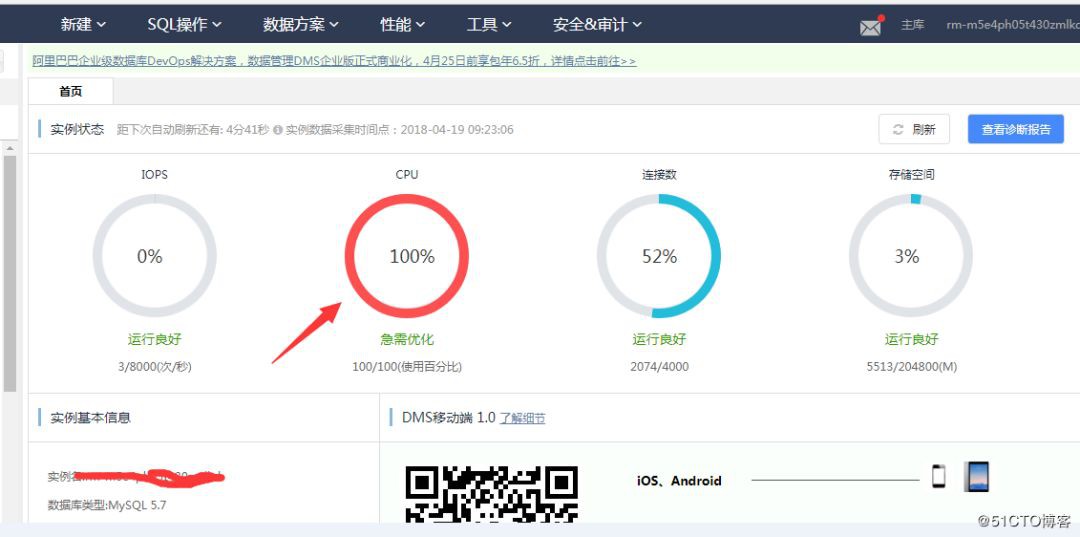
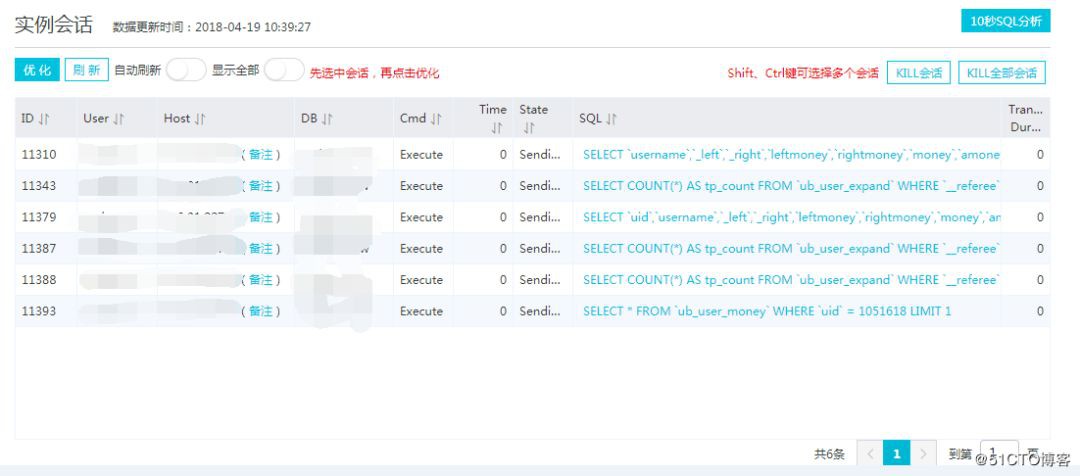
進入會話去看看,發現會話“炸鍋了”,發現幾百頁的 select 都擠在 ub_user_calculate 這個表中,這個表資料量相對大一些,目前有 200 多萬條資料,如下圖:

我的自然反應就是去檢視此表的結構,但發現此表沒有索引,我被驚訝到了,竟然沒有索引,這……
然後筆者傳回源資料庫檢視這張表,也發現沒有索引,由此可以確定我導過來的這張表就是沒有建立索引,如下圖:

當資料庫中出現訪問表的 SQL 沒建立索引,會導致全表掃描,如果表的資料量很大,掃描大量的資料,執行效率過慢,佔用資料庫連線,連線數堆積很快達到資料庫的最大連線數設定,新的應用請求將會被拒絕導致故障發生。
解決問題
我趕緊把此事反映給開發負責人,表明問題根源找到了,會話鎖死了,是由其中的一張表沒有索引而導致的,問詢需要給哪幾個欄位加索引。
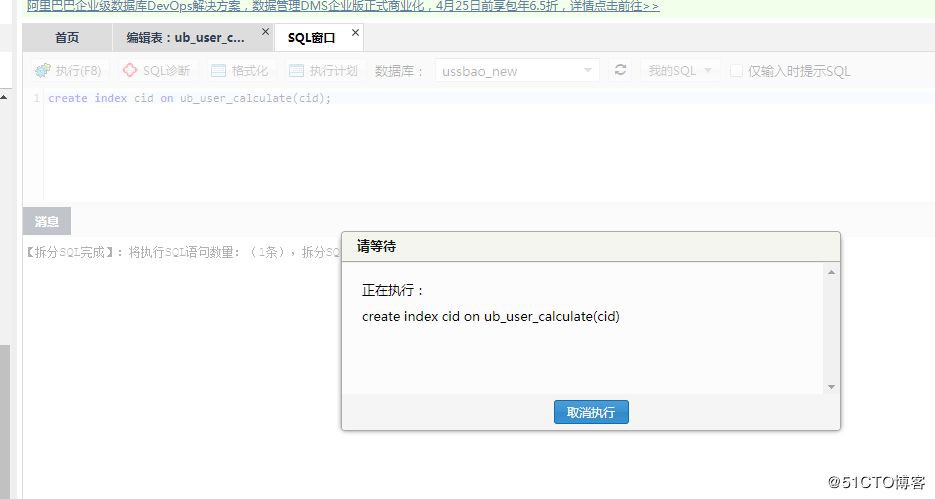
然後接著操作增加索引:

點選儲存後,發現建立索引的 SQL 一直卡死著,如下圖所示:

突然想起來還有一堆會話在那裡,先 Kill 掉所有會話吧,不然索引肯定建立不了,然後又發現會話根本殺不完,如下圖:
怎麼辦呢?會話殺不完…沒辦法,先把訪問入口切斷吧,反正現在使用者訪問也超時,就毅然決定先把域名停了,訪問入口給切斷了,然後在增加索引。索引加上了,發現 CPU 還下不去,如下圖:

為了快速讓 CPU 降下去,重啟這個實體吧:

實體重啟完後,CPU 下去了,會話也下去了:

開啟入口層的域名訪問吧,再次觀察現在的會話和 CPU 等況,如下圖:

這就對了,會話也正常了,通知領導業務恢復。
再來看一下伺服器 CPU 的情況(遷移 MySQL 後的情況),明顯逐漸好轉。

索引使用策略及最佳化
建立索引註意事項:
-
在經常查詢而不經常增刪改操作的欄位加索引。
-
order by 與 group by 後應直接使用欄位,而且欄位應該是索引欄位。
-
一個表上的索引不應該超過 6 個。
-
索引欄位的長度固定,且長度較短。
-
索引欄位重覆不能過多,如果某個欄位為主鍵,那麼這個欄位不用設為索引。
-
在過濾性高的欄位上加索引。
使用索引註意事項:
-
使用 like 關鍵字時,前置 % 會導致索引失效。
-
使用 null 值會被自動從索引中排除,索引一般不會建立在有空值的列上。
-
使用 or 關鍵字時,or 左右欄位如果存在一個沒有索引,有索引欄位也會失效。
-
使用 != 運運算元時,將放棄使用索引。因為範圍不確定,使用索引效率不高,會被引擎自動改為全表掃描。
-
不要在索引欄位進行運算。
-
在使用複合索引時,最左字首原則,查詢時必須使用索引的第一個欄位,否則索引失效;並且應儘量讓欄位順序與索引順序一致。
-
避免隱式轉換,定義的資料型別與傳入的資料型別保持一致。
參考連結:https://help.aliyun.com/document_detail/52274.html?spm=a2c4g.11174283.6.812.ZGPyBQ
總結
此次故障雖然是表沒有索引造成的,但是我是有責任的,沒有挨個表檢查一下表的結構。
透過此次故障也可以看出來開發在設計表的時候真的要非常的重視,註意細節。
還有就是之前在容器中執行的 MySQL 也時不時的出現 CPU 瓶頸(比如 CPU 使用率偶爾會達到 80% 以上),我應該提前發現這些問題,徹底排查找出問題所在原因再進行遷庫的操作。

甘兵,高階運維工程師,6 年運維工作經驗。曾就職於國家網際網路應急中心、天音控股等企業。擁有豐富系統運維經驗,大型網路架構設計經驗。熱衷於開源技術的研究,關註的技術方向 Docker、DevOps 等。
●編號166,輸入編號直達本文
●輸入m獲取文章目錄

Python程式設計
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
