寫在正文之前
最近在做推薦系統,在專案組內做了一個分享。今天有些時間,就將邏輯梳理一遍,將ppt內容用文字沉澱下來,便於接下來對推薦系統的進一步研究。推薦系統確實是極度複雜,要走的路還很長。
A First Glance

為什麼需要推薦系統——資訊過載
隨著網際網路行業的井噴式發展,獲取資訊的方式越來越多,人們從主動獲取資訊逐漸變成了被動接受資訊,資訊量也在以幾何倍數式爆發增長。舉一個例子,PC時代用google reader,常常有上千條未讀部落格更新;如今的微信公眾號,也有大量的紅點未閱讀。垃圾資訊越來越多,導致用戶獲取有價值資訊的成本大大增加。為瞭解決這個問題,我個人就採取了比較極端的做法:直接忽略所有推送訊息的入口。但在很多時候,有效資訊的獲取速度極其重要。


由於資訊的爆炸式增長,對資訊獲取的有效性,針對性的需求也就自然出現了。推薦系統應運而生。
亞馬遜的推薦系統
最早的推薦系統應該是亞馬遜為了提升長尾貨物的使用者抵達率而發明的。已經有資料證明,長尾商品的銷售額以及利潤總和與熱門商品是基本持平的。亞馬遜網站上線上銷售的商品何止百萬,但首頁能夠展示的商品數量又極其有限,給使用者推薦他們可能喜歡的商品就成了一件非常重要的事情。當然,商品搜尋也是一塊大蛋糕,亞馬遜的商品搜尋早已經開始侵蝕谷歌的核心業務了。
在亞馬遜的商品展示頁面,經常能夠看見:瀏覽此商品的顧客也同時瀏覽。

這就是非常典型的推薦系統。八卦一下:”剁手族”的興起,與推薦系統應該有一定關係吧,哈哈。
推薦系統與大資料
大資料與雲端計算,在當下非常熱門。不管是業內同事還是其他行業的朋友,大資料都是一個常談的話題。就像青少年時期熱門的話題:“性”。大家都不太懂,但大家都想說上幾句。業內對於大資料的使用其實還處於一個比較原始的探索階段,前段時間聽一家基因公司的CEO說,現在可以將人類的基因完全匯出為資料,但這些資料毫無規律,能拿到這些資料,但根本不知道可以乾什麼。推薦系統也是利用使用者資料來發現規律,相對來說開始得更早,運用上也比較成熟。
冷啟動問題
推薦系統需要資料作為支撐。但亞馬遜在剛剛開始做推薦的時候,是沒有大量且有效的使用者行為資料的。這時候就會面臨著“冷啟動”的問題。沒有使用者行為資料,就利用商品本身的內容資料。這就是推薦系統早期的做法。
基於內容的推薦:
-
tag 給商品打上各種tag:運動商品類,快速消費品類,等等。粒度劃分越細,推薦結果就越精確
-
商品名稱,描述的關鍵字 透過從商品的文字描述資訊中提取關鍵字,從而利用關鍵字的相似來作推薦
-
同商家的不同商品 使用者購買了商店的一件商品,就推薦這個商店的其他熱銷商品
-
利用經驗,人為地做一些關聯 一個經典的例子就是商店在啤酒架旁邊擺上紙尿布。那麼,在網上購買啤酒的人,也可以推薦紙尿布?
由於內容的極度複雜性,這一塊兒的規則可以無限拓展。基於內容的推薦與使用者行為資料沒有關係,在亞馬遜早期是比較靠譜的策略。但正是由於內容的複雜性,也會出現很多錯誤的推薦。比如:小明在網上搜索過保時捷汽車模型。然後推薦系統根據關鍵字,給小明推薦了價值200萬的保時捷911……
使用者行為資料—到底在記錄什麼
在遊戲裡面,我們的人物角色是一堆複雜的資料,這叫做資料儲存;這些資料以一定的結構組合起來,這叫做資料結構。同樣地,在亞馬遜眼裡,我們就是一張張表格中一大堆紛繁複雜的數字。舉一個慄子:
小明早上9點開啟了亞馬遜,先是瀏覽了首頁,點選了幾個熱銷的西裝連結,然後在搜尋欄輸入了nike籃球鞋,在瀏覽了8雙球鞋後,看了一些購買者的評價,最終選定了air jordan的最新款。
這就是一條典型的使用者行為資料。亞馬遜會將這條行為拆分成設定好的資料塊,再以一定的資料結構,儲存到亞馬遜的使用者行為資料倉庫中。每天都有大量的使用者在產生這樣的行為資料,資料量越多,可以做的事情也就越強大。
user-item 使用者偏好矩陣
收集資料是為了分析使用者的偏好,形成使用者偏好矩陣。比如在網購過程中,使用者發生了檢視,購買,分享商品的行為。這些行為是多樣的,所以需要一定的加權演演算法來計算出使用者對某一商品的偏好程度,形成user-item使用者偏好矩陣。
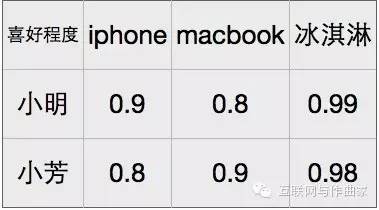
資料清理
當我們開始有意識地記錄使用者行為資料後,得到的使用者資料會逐漸地爆髮式增長。就像錄音時存在的噪音一樣,獲取的使用者資料同樣存在著大量的垃圾資訊。因此,拿到資料的第一步,就是對資料做清理。其中最核心的工作,就是減噪和歸一化:
減噪:使用者行為資料是在使用者的使用過程中產生的,其中包含了大量的噪音和使用者誤操作。比如因為網路中斷,使用者在短時間內產生了大量點選的操作。透過一些策略以及資料挖掘演演算法,來去除資料中的噪音。
歸一化:清理資料的目的是為了透過對不同行為進行加權,形成合理的使用者偏好矩陣。使用者會產生多種行為,不同行為的取值範圍差距可能會非常大。比如:點選次數可能遠遠大於購買次數,直接套用加權演演算法,可能會使得點選次數對結果的影響程度過大。於是就需要歸一演演算法來保證不同行為的取值範圍大概一致。最簡單的歸一演演算法就是將各類資料來除以此類資料中的最大值,以此來保證所有資料的取值範圍都在[0,1]區間內。
降維演演算法——SVD奇異值分解
透過記錄使用者行為資料,我們得到了一個巨大的使用者偏好矩陣。隨著物品數量的增多,這個矩陣的列數在不斷增長,但對單個使用者來說,有過行為資料的物品數量是相當有限的,這就造成了這個巨大的使用者偏好矩陣實際上相當稀疏,有效的資料其實很少。SVD演演算法就是為瞭解決這個問題發明的。
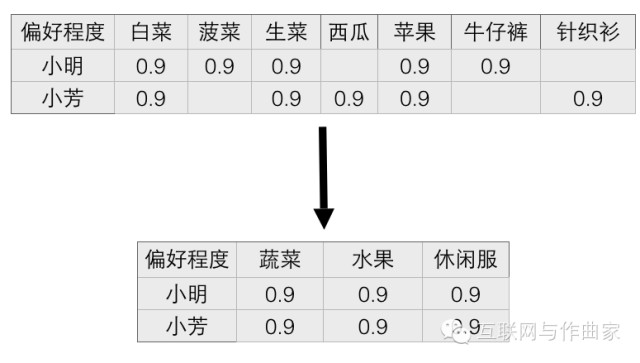
將大量的物品提取特徵,抽象成了3大類:蔬菜,水果,休閑服。這樣就將稀疏的矩陣縮小,極大的減少了計算量。但這個例子僅僅是為了說明SVD奇異值分解的原理。真正的計算實施中,不會有人為的提取特徵的過程,而是完全透過數學方法進行抽象降維的。透過對矩陣相乘不斷的擬合,引數調整,將原來巨大的稀疏的矩陣,分解為不同的矩陣,使其相乘可以得到原來的矩陣。這樣既可以減少計算量,又可以填充上述矩陣中空值的部分。
協同過濾演演算法
我一直在強呼叫戶行為資料,目的就是為介紹協同過濾演演算法做鋪墊。協同過濾,Collaborative Filtering,簡稱CF,廣泛應用於如今的推薦系統中。透過協同過濾演演算法,可以算出兩個相似度:user-user相似度矩陣; item-item相似度矩陣。

為什麼叫做協同過濾?是因為這兩個相似度矩陣是透過對方來計算出來的。舉個慄子:100個使用者同時購買了兩種物品A和B,得出在item-item相似度矩陣中A和B的相似度為0.8; 1000個物品同時被使用者C和使用者D購買,得出在user-user相似度矩陣中C和D的相似度是0.9. user-user, item-item的相似度都是透過使用者行為資料來計算出來的。
計算相似度的具體演演算法,大概有幾種:歐幾裡得距離,皮爾遜相關係數,Cosine相似度,Tanimoto繫數。具體的演演算法,有興趣的同學可以google.
使用者畫像
使用者畫像關聯閱讀:經典 : 系統性闡述使用者畫像資料建模方法。
提到大資料,不能不說使用者畫像。經常看到有公司這樣宣傳:“掌握了千萬使用者的行為資料,描繪出了極其有價值的使用者畫像,可以為每個app提供精準的使用者資料,助力app推廣。” 這樣的營銷廣告經不起半點推敲。使用者對每個種類的app的行為都不同,得到的行為資料彼此之間差別很大,比如使用者在電商網站上的行為資料,對音樂類app基本沒有什麼價值。推薦系統的難點,其中很大一部分就在於使用者畫像的積累過程極其艱難。簡言之,就是使用者畫像與業務本身密切相關。
LR邏輯回歸
基於使用者偏好矩陣,發展出了很多機器學習演演算法,在這裡再介紹一下LR的思想。具體的邏輯回歸,又分為線性和非線性的。其他的機器學習演演算法還有:K均值聚類演演算法,Canopy聚類演演算法,等等。有興趣的同學可以看看July的文章。連結在最後的閱讀原文。
LR邏輯回歸分為三個步驟:
-
提取特徵值
-
透過使用者偏好矩陣,不斷擬合計算,得到每個特徵值的權重
-
預測新使用者對物品的喜好程度
舉個慄子:
小明相親了上千次,我們收集了大量的行為資料,以下資料僅僅是冰山一角。

透過大量的擬合計算得出,特徵值“個性開朗程度”的權重為30%,“顏值”的權重為70%。哎,對這個看臉的世界已經絕望了,寫完這篇文章,就去訂前往韓國的機票吧。
然後,透過擬合出的權重,來預測小明對第一千零一次相親物件的喜愛程度。

這就是LR邏輯回歸的原理。具體的數學演演算法,有興趣的同學可以google之。
如何利用推薦系統賺錢
還是以亞馬遜為例。小明是個籃球迷,每個月都會買好幾雙籃球鞋。透過幾個月的購買記錄,亞馬遜已經知道小明的偏好,準備給小明推薦籃球鞋。但籃球鞋品牌這麼多,推薦哪一個呢?笑著說:哪個品牌給我錢多,就推薦哪個品牌。這就是最簡單的流量生意了。這些都叫做:商業規則。
但在加入商業規則之前,需要讓使用者感知到推薦的準確率。如果一開始就強推某些置頂的VIP資源,會極大地損害使用者體驗,讓使用者覺得推薦完全沒有準確性。這樣的後果對於推薦系統的持續性發展是毀滅性的。
過濾規則
協同過濾只是單純地依賴使用者行為資料,在真正的推薦系統中,還需要考慮到很多業務方面的因素。以音樂類app為例。周傑倫出了一張新專輯A,大部分年輕人都會去點選收聽,這樣會導致其他每一張專輯相似專輯中都會出現專輯A。這個時候,再給使用者推薦這樣的熱門專輯就沒有意義了。所以,過濾掉熱門的物品,是推薦系統的常見做法之一。這樣的規則還有很多,視不同的業務場景而定。
推薦的多樣性
與推薦的準確性有些相悖的,是推薦的多樣性。比如說推薦音樂,如果完全按照使用者行為資料進行推薦,就會使得推薦結果的候選集永遠只在一個比較小的範圍內:聽小清新音樂的人,永遠也不會被推薦搖滾樂。這是一個很複雜的問題。在保證推薦結果準確的前提下,按照一定的策略,去逐漸拓寬推薦結果的範圍,給予推薦結果一定的多樣性,這樣才不會膩嘛。
持續改進
推薦系統具有高度複雜性,需要持續地進行改進。可能在同一時間內,需要上線不同的推薦演演算法,做A/B test。根據使用者對推薦結果的行為資料,不斷對演演算法進行最佳化,改進。要走的路還很長:路漫漫其修遠兮,吾將上下而求索。
(END)
轉自微信公眾號:網際網路與作曲家;作者:neil;
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
80%的運營註定了打雜?因為你沒有搭建出一套有效的使用者運營體系
商務合作|約稿 請加qq:365242293
更多相關知識請回覆:“ 月光寶盒 ”;
資料分析(ID : ecshujufenxi )網際網路科技與資料圈自己的微信,也是WeMedia自媒體聯盟成員之一,WeMedia聯盟改寫5000萬人群。

