來自:戀習Python(ID:sldata2017)
萬眾期待的《邪不壓正》已上映有一週時間。
但上映當日早上開畫8.2,上映不到一天閃崩到7.1的評分好像已經給這部片子本該大展拳腳的片子,戴上了一個結結實實的囚具。

首日票房雖然過億,卻依舊不敵多日日票房冠軍《我不是藥神》;難道薑文又搞砸了?不管如何,薑文的電影總能掀起影評人高漲的評論熱情;
今天就跟著戀習Python看看網友對這部薑文電影的感受到底怎麼樣。
接下來,戀習Python將會跟你一起用貓眼上萬條評論資料來分析,網友對這部電影的反響究竟如何?整體思路,將會從資料獲取、資料處理、資料視覺化三部曲來進行:
一、資料獲取
關於如何獲取網頁的資料,戀習Python一直也是推薦三步走:下載資料、解析資料、儲存資料。在下載資料之前,我們看看貓眼官網的網頁結構,看看網友的評論資料介面究竟在哪?
然而,開啟貓眼網頁(http://maoyan.com/films/248566)只有寥寥幾個評論,那它的資料會不會是透過json格式儲存到伺服器中呢?無奈只能透過抓包貓眼APP來找其資料介面

最後,發現其資料介面為:http://m.maoyan.com/mmdb/comments/movie/248566.json?_v_=yes&offset;=1,其中258566屬於電影的專屬id,offset代表頁數

最後檢驗,這個介面只給展示1000頁資料,如下:


介面找到後,開始寫爬取資料程式碼,詳情程式碼如下:
import requests
import json
import time
import random
#下載第一頁資料
def get_one_page(url):
essay-headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
response = requests.get(url,essay-headers=essay-headers)
if response.status_code == 200:
return response.text
return None
#解析第一頁資料
def parse_one_page(html):
data = json.loads(html)['cmts']
for item in data:
yield{
'comment':item['content'],
'date':item['time'].split(' ')[0],
'rate':item['score'],
'city':item['cityName'],
'nickname':item['nickName']
}
#儲存資料到文字檔案
def save_to_txt():
for i in range(1,1001):
url = 'http://m.maoyan.com/mmdb/comments/movie/248566.json?_v_=yes&offset;=' + str(i)
html = get_one_page(url)
print('正在儲存第%d頁。'% i)
for item in parse_one_page(html):
with open('xie_zheng.txt','a',encoding='utf-8') as f:
f.write(item['date'] + ',' + item['nickname'] + ',' + item['city'] + ',' +str(item['rate'])+','+item['comment']+'\n')
time.sleep(5 + float(random.randint(1, 100)) / 20)
if __name__ == '__main__':
save_to_txt()
二、資料處理
獲取資料後發現,會有一些資料重覆,如下圖:

因此需要指令碼批次對資料進行去重處理,詳情程式碼如下:
def xie_zheng(infile,outfile):
infopen = open(infile,'r',encoding='utf-8')
outopen = open(outfile,'w',encoding='utf-8')
lines = infopen.readlines()
list_l = []
for line in lines:
if line not in list_l:
list_l.append(line)
outopen.write(line)
infopen.close()
outopen.close()
if __name__ == '__main__':
xie_zheng('文字原路徑','標的路徑')
每天可以不定時(每隔四五小時獲取一次資料,基本每次可獲取900多條資料),最終戀習Python獲取到7/15-7/18之間上萬條來作為資料集分析。
三、資料視覺化
今天我們就用pyecharts將清理過後的萬條評論資料來實現視覺化。pyecharts 是一個用於生成 Echarts 圖表的類庫。Echarts 是百度開源的一個資料視覺化 JS 庫。用 Echarts 生成的圖視覺化效果非常棒,pyecharts 是為了與 Python 進行對接,方便在 Python 中直接使用資料生成圖。(詳情請看:http://pyecharts.org/)
粉絲北上廣及沿海一帶居多


由上圖,可以看出北上廣一帶的使用者相對較多,這些地方的網際網路使用者基數本來就大,同時沿海一代的三四線城市也成為票房貢獻者的一部分
詳情程式碼如下:
from pyecharts import Style
from pyecharts import Geo
#讀取城市資料
city = []
with open('xie_zheng.txt',mode='r',encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
if len(row.split(',')) == 5:
city.append(row.split(',')[2].replace('\n',''))
def all_list(arr):
result = {}
for i in set(arr):
result[i] = arr.count(i)
return result
data = []
for item in all_list(city):
data.append((item,all_list(city)[item]))
style = Style(
title_color = "#fff",
title_pos = "center",
width = 1200,
height = 600,
background_color = "#404a59"
)
geo = Geo("《邪不壓正》粉絲人群地理位置","資料來源:戀習Python",**style.init_style)
attr,value= geo.cast(data)
geo.add("",attr,value,visual_range=[0,20],
visual_text_color="#fff",symbol_size=20,
is_visualmap=True,is_piecewise=True,
visual_split_number=4)
geo.render()評論兩極分化相對嚴重
獲取到近幾日的網友上萬條評論資料後,我們切換到今天主題,看看網友對這部電影究竟評論如何?
我們將資料集中的評論內容提取出來,將評論分詞後製作如下詞雲圖:

可以看出,排名靠前的熱詞分別是薑文、不錯、好看、彭於晏、劇情、看不懂等,可以看出大家對電影的評價還不錯,同時估計還有一大部分粉絲是專門看國民老公彭於晏的裸奔與八塊腹肌的(哈哈哈)

至於劇情方面,相對於《讓子彈飛》,《邪不壓正》用了更“薑文”更癲狂的方式來講了一個相對簡單的故事。
從砰砰砰幾槍打出片名的那一刻起,影片就在一個極度亢奮的節奏之下不停向前推進著,伴隨著應接不暇的戲謔臺詞,薑文無時無刻不在釋放自己的任性,太瘋了,甚至有些極端。對於普通觀眾來說,太難消化了,上一秒還沒琢磨明白,下一秒又迎來了一個亢奮且莫名的環境和臺詞中(也驗證評論中一部分網友對劇情看不懂的評價)。

詳情程式碼如下:
import pickle
from os import path
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
comment = []
with open('quan.txt',mode='r',encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
if len(row.split(',')) == 5:
comment.append(row.split(',')[4].replace('\n',''))
comment_after_split = jieba.cut(str(comment),cut_all=False)
wl_space_split= " ".join(comment_after_split)
#匯入背景圖
backgroud_Image = plt.imread('C:\\Users\\Administrator\\Desktop\\1.jpg')
stopwords = STOPWORDS.copy()
#可以加多個遮蔽詞
stopwords.add("電影")
stopwords.add("一部")
stopwords.add("一個")
stopwords.add("沒有")
stopwords.add("什麼")
stopwords.add("有點")
stopwords.add("這部")
stopwords.add("這個")
stopwords.add("不是")
stopwords.add("真的")
stopwords.add("感覺")
stopwords.add("覺得")
stopwords.add("還是")
#設定詞雲引數
#引數分別是指定字型、背景顏色、最大的詞的大小、使用給定圖作為背景形狀
wc = WordCloud(width=1024,height=768,background_color='white',
mask=backgroud_Image,font_path="C:\simhei.ttf",
stopwords=stopwords,max_font_size=400,
random_state=50)
wc.generate_from_text(wl_space_split)
img_colors= ImageColorGenerator(backgroud_Image)
wc.recolor(color_func=img_colors)
plt.imshow(wc)
plt.axis('off')#不顯示坐標軸
plt.show()
#儲存結果到本地
wc.to_file('儲存路徑')一星級影評佔比高達20%
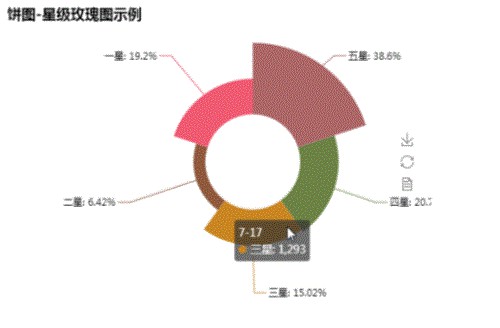
圖中可以看出,五星級比例接近40%,而一星級比例與四星級比例幾乎差不多,幾乎為都為20%。(備註:一星級數量等於1與0.5的總和,以此類推)
很明顯,薑文再次掀起了影評人和觀眾的論戰,儘管薑文對影評人並不友好,但影評人還是願意去袒護薑文。其實,薑文的電影關鍵在於你期待什麼?型別片?薑文拍的從來都不是型別片。藝術片?薑文的電影裡的藝術不是一遍就可以看懂的。他的電影就是帶著一種“後搖風格”,濃烈、生猛。
薑文和觀眾都很自我,薑文端著,不肯向市場低頭;觀眾正是因為沒端著,所以看薑文的電影過於疲憊。誰都沒錯,誰都不用救。
詳情程式碼如下:
from pyecharts import ThemeRiver
rate = []
with open('quan.txt',mode='r',encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
if len(row.split(',')) == 5:
rate.append(row.split(',')[3].replace('\n',''))
print(rate.count('5')+rate.count('4.5'))
print(rate.count('4')+rate.count('3.5'))
print(rate.count('3')+rate.count('2.5'))
print(rate.count('2')+rate.count('1.5'))
print(rate.count('1')+rate.count('0.5'))
#餅狀圖
from pyecharts import Pie
attr = ["五星", "四星", "三星", "二星", "一星"]
#分別代表各星級評論數
v1 = [3324,1788,1293,553,1653]
pie = Pie("餅圖-星級玫瑰圖示例", title_pos='center', width=900)
pie.add("7-17", attr, v1, center=[75, 50], is_random=True,
radius=[30, 75], rosetype='area',
is_legend_show=False, is_label_show=True)
pie.render()
關於《邪不壓正》網友評論資料就分析到此結束!
你覺得《邪不壓正》不好看是對的,因為它太薑文了。你若覺得《邪不壓正》好看也是對的,因為它真的太薑文了。成也薑文,敗也薑文!但這也許就是他孤傲的世界吧。
●編號463,輸入編號直達本文
●輸入m獲取文章目錄

演演算法與資料結構
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。