
來源:Python程式員
ID:pythonbuluo
在我看來,對於Numpy以及Matplotlib,Pandas可以幫助建立一個非常牢固的用於資料挖掘與分析的基礎。而Scipy(會在接下來的帖子中提及)當然是另一個主要的也十分出色的科學計算庫,但是我認為前三者才是真正的Python科學計算的支柱。
所以,不需要太多精力,讓我們馬上開始Python科學計算系列的第三帖——Pandas。如果你還沒有檢視其他帖子,不要忘了去看一下哦!
匯入Pandas
我們首先要匯入我們的演出明星——Pandas。

這是匯入Pandas的標準方式。顯然,我們不希望每時每刻都在程式中寫’pandas’,但是保持程式碼簡潔、避免命名衝突還是相當重要的。因而我們折衷一下,用‘pd’代替“pandas’。如果你仔細檢視其他人使用Pandas的程式碼,你會發現這條匯入陳述句。
Pandas的資料型別
Pandas基於兩種資料型別:series與dataframe。
一個series是一個一維的資料型別,其中每一個元素都有一個標簽。如果你閱讀過這個系列的關於Numpy的文章,你就可以發現series類似於Numpy中元素帶標簽的陣列。其中,標簽可以是數字或者字串。
一個dataframe是一個二維的表結構。Pandas的dataframe可以儲存許多種不同的資料型別,並且每一個坐標軸都有自己的標簽。你可以把它想象成一個series的字典項。
將資料匯入Pandas
在我們開始挖掘與分析之前,我們首先需要匯入能夠處理的資料。幸好,Pandas在這一點要比Numpy更方便。
在這裡我推薦你使用自己所感興趣的資料集來使用。你的或其他國家的政府網站上會有一些好的資料源。例如,你可以搜尋英國政府資料或美國政府資料來獲取資料源。當然,Kaggle是另一個好用的資料源。
在此,我將採用英國政府資料中關於降雨量資料,因為他們十分易於下載。此外,我還下載了一些日本降雨量的資料來使用。

這裡我們從csv檔案中讀取到了資料,並將他們存入了dataframe中。我們只需要呼叫read_csv函式並將csv檔案的路徑作為函式引數即可。essay-header關鍵字告訴Pandas這些資料是否有列名,在哪裡。如果沒有列名,你可以將其置為None。Pandas非常智慧,所以你可以省略這一關鍵字。
將你的資料準備好以進行挖掘和分析
現在我們已經將資料匯入了Pandas。在我們開始深入探究這些資料之前,我們一定迫切地想大致瀏覽一下它們,並從中獲得一些有用資訊,幫助我們確立探究的方向。
想要快速檢視前x行資料:

我們僅僅需要使用head()函式並傳入我們期望獲得的行數。
你將獲得一個類似下圖一樣的表:

另一方面,你可能想要獲得最後x行的資料:

類似於head,我們只需要呼叫tail函式並傳入我們想獲取的行數。需要註意的是,Pandas不是從dataframe的結尾處開始倒著輸出資料,而是按照它們在dataframe中固有的順序輸出給你。
你將獲得類似下圖的表

當你在Pandas中查詢列時,你通常需要使用列名。這樣雖然非常便於使用,但有時候,資料可能會有特別長的列名,例如,有些列名可能是問卷表中的某整個問題。把這些列名變短會讓你的工作更加輕鬆:

有一點需要註意的是,在這裡我故意讓所有列的標簽都沒有空格和橫線。後面你將會看到,如果我們這樣命名變數,Pandas會將它們存成什麼型別。
你將獲得同之前一樣的資料,但是列名已經變了:

另一件你很想知道的關於你的資料的重要的事情是資料一共有多少條目。在Pandas中,一個條目等同於一行,所以我們可以透過len方法獲取資料的行數,即條目數。

這將給你一個整數告訴你資料的行數。在我的資料集中,我有33行。
此外,你可能需要知道你資料的一些基本的統計資訊。Pandas讓這件事變得非常簡單。

這將傳回一個包含多種統計資訊的表格,例如,計數,均值,標準方差等。它看起來像這樣:

過濾
當你檢視你的資料集時,你可能希望獲得一個特殊的樣本資料。例如,如果你有一個關於工作滿意度的問卷調查資料,你可能想要獲得所有在同一行業或同一年齡段的人的資料。
Pandas為我們提供了多種方法來過濾我們的資料並提取出我們想要的資訊。有時候你想要提取一整列。可以直接使用列標簽,非常容易。

註意到當我們提取了一列,Pandas將傳回一個series,而不是一個dataframe。是否還記得,你可以將dataframe視作series的字典。所以,如果我們取出了某一列,我們獲得的自然是一個series。
還記得我所說的命名列標簽的註意事項嗎?不使用空格和橫線等可以讓我們以訪問類屬性相同的方法來訪問列,即使用點運運算元。

這裡傳回的結果和之前的一模一樣,即一個包含我們所選列的資料的series。
如果你讀過這一系列中Numpy那一篇帖子,你可能會記得一項技術叫做‘boolean masking’,即我們可以在陣列上執行一個條件陳述句來獲得對應的布林值陣列。好,我們也可以在Pandas中做同樣的事。

上述程式碼將範圍一個布林值的dataframe,其中,如果9、10月的降雨量低於1000毫米,則對應的布林值為‘True’,反之,則為’False’。
我們也可以使用這些條件運算式來過濾一個已知的dataframe。

這將傳回一個僅僅包含9、10月降雨量低於1000mm的條目的dataframe。
你也可以使用多條條件運算式來進行過濾:

這將傳回rain_octsep小於1000並且outflow_octsep小於4000的那些條目。
值得註意的是,由於運運算元優先順序的問題,在這裡你不可以使用關鍵字‘and’,而只能使用’&’與括號

好訊息是,如果在你的資料中有字串,你也可以使用字串方法來過濾資料。

註意到你必須使用.str.[string method],你不能直接在字串上直接呼叫字串方法。這一陳述句傳回1990年代的所有條目。

索引
前幾部分為我們展示瞭如何透過列操作來獲得資料。實際上,Pandas同樣有標簽化的行操作。這些行標簽可以是數字或是其他標簽。獲取行資料的方法也取決於這些標簽的型別。
如果你的行有數字索引,你可以使用iloc取用他們:

iloc僅僅作用於數字索引。它將會傳回該行的一個series。在傳回的series中,這一行的每一列都是一個獨立的元素。
可能在你的資料集裡有年份的列,或者年代的列,並且你希望可以用這些年份或年代來索引某些行。這樣,我們可以設定一個(或多個)新的索引。

這將會給’water_year’一個新的索引值。註意到列名雖然只有一個元素,卻實際上需要包含於一個串列中。如果你想要多個索引,你可以簡單地在串列中增加另一個列名。

在上面這個例子中,我們把我們的索引值全部設定為了字串。這意味著我們不可以使用iloc索引這些列了。這種情況該如何?我們使用loc。

這裡,loc和iloc一樣會傳回你所索引的行資料的一個series。唯一的不同是此時你使用的是字串標簽進行取用,而不是數字標簽。
ix是另一個常用的取用一行的方法。那麼,如果loc是字串標簽的索引方法,iloc是數字標簽的索引方法,那什麼是ix呢?事實上,ix是一個字串標簽的索引方法,但是它同樣支援數字標簽索引作為它的備選。

正如loc和iloc,上述程式碼將傳回一個series包含你所索引的行的資料。
既然ix可以完成loc和iloc二者的工作,為什麼還需要它們呢?最主要的原因是ix有一些輕微的不可預測性。還記得我說數字標簽索引是ix的備選嗎?數字標簽可能會讓ix做出一些奇怪的事情,例如將一個數字解釋成一個位置。而loc和iloc則為你帶來了安全的、可預測的、內心的寧靜。然而必須指出的是,ix要比loc和iloc更快。
通常我們都希望索引是整齊有序地。我們可以在Pandas中透過呼叫sort_index來對dataframe實現排序。

由於我的所以已經是有序的了,所以為了演示,我設定了關鍵字引數’ascending’為False。這樣,我的資料會以降序排列。

當你為一列資料設定了一個索引時,它們將不再是資料本身了。如果你想把索引設定為原始資料的形式,你可以使用和set_index相反的操作——reset_index。

這將傳回資料原始的索引形式。

對資料集應用函式
有時候你會想以某些方式改變或是操作你資料集中的資料。例如,如果你有一列年份的資料而你希望建立一個新的列顯示這些年份所對應的年代。Pandas對此給出了兩個非常有用的函式,apply和applymap。

這會建立一個名為‘year‘的新列。這一列是由’water_year’列所匯出的。它獲取的是主年份。這便是使用apply的方法,即如何對一列應用一個函式。如果你想對整個資料集應用某個函式,你可以使用dataset.applymap()。
操作一個資料集結構
另一件經常會對dataframe所做的操作是為了讓它們呈現出一種更便於使用的形式而對它們進行的重構。
首先,groupby:

grouby所做的是將你所選擇的列組成一組。上述程式碼首先將年代組成一組。雖然這樣做沒有給我們帶來任何便利,但我們可以緊接著在這個基礎上呼叫其它方法,例如max, min, mean等。例子中,我們可以得到90年代的均值。

你也可以對多行進行分組操作:


接下來的unstack操作可能起初有一些困惑。它的功能是將某一列前置成為列標簽。我們最好如下看看它的實際效果。

這個操作會將我們在上面小節建立的dataframe轉變成如下形式。它將標識‘year’索引的第0列推起來,變為了列標簽。

我們再附加一個unstack操作。這次我們對’rain_octsep’索引的第1列操作:


現在,在我們下一個操作前,我們首先創造一個新的dataframe。

上述程式碼為我們建立瞭如下的dataframe,我們將對它進行pivot操作。

pivot實際上是在本文中我們已經見過的操作的組合。首先,它設定了一個新的索引(set_index()),然後它對這個索引排序(sort_index()),最後它會進行unstack操作。組合起來就是一個pivot操作。看看你能不能想想會發生什麼:

註意到最後有一個.fillna(‘’)。這個pivot創造了許多空的或值為NaN的條目。我個人覺得我的dataframe被亂七八糟的NaN分散了註意力,所以使用了fillna(‘’)將他們變成了空字串。你也可以輸入任何你喜歡的東西,例如一個0。我們也可以使用函式dropna(how=’any’)來刪除所有的帶有NaN的行。然而在這個例子裡,它可能會把所有東西都刪了,所以我們沒有這樣做。

上述dataframe為我們展現了所有降雨量大於1250的年份中的總雨量。不可否認的是,這個並不是一個pivot的最好的示範,但是希望你能get到它的核心。看看你能在你自己的資料集中想出什麼點子。
合併資料集
有時候你有兩個單獨的資料集,它們直接互相關聯,而你想要比較它們的差異或者合併它們。沒問題,Pandas可以很容易實現:

開始時你需要透過’on’關鍵字引數指定你想要合併的列。你也可以忽略這個引數,這樣Pandas會自動確定合併哪列。
如下你可以看到,兩個資料集在年份這一類上已經合併了。rain_jpn資料集僅僅包含年份以及降雨量。當我們以年份這一列進行合併時,僅僅’jpn_rainfall’這一列和我們UK雨量資料集的對應列進行了合併。

採用Pandas快速繪製圖表
Matplotlib很好用,但是想要畫出一個中途下降的圖表還是需要費一番功夫的。而有的時候你僅僅想要快速畫出一個資料的大致走勢來幫助你發掘搞清這些資料的意義。Pandas提供了plot函式滿足你的需求:

這裡非常輕鬆快速地利用plot畫出了一個你的資料的圖表。利用這個圖表,你可以緊接著直觀地發現深入挖掘的方向。例如,如果你看我畫出的我資料的圖表,你可以看到1995年英國可能發生了乾旱。
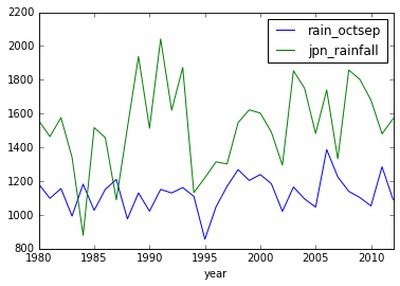
你也能發現英國的降雨量明顯低於日本,然而人們卻說英國雨下得很多!
儲存你的資料集
在清理、重構以及挖掘完你的資料後,你通常會剩下一些非常重要有用的東西。你不僅應當保留下你的原始資料,也同樣需要儲存下你最新處理過的資料集。

上述程式碼會將你的資料存入一個csv檔案以備下次使用。
到此為止,我們簡單介紹了Pandas。正如我之前說的,Pandas是非常好用的庫,而我們僅僅是接觸了一點皮毛。但是我希望透過我的介紹,你可以開始進行真正的資料清理與挖掘工作了。
像往常一樣,我非常希望你能儘快開始嘗試Pandas。找一兩個你喜歡的資料集,開一瓶啤酒,坐下來,然後開始探索你的資料吧。這確實是唯一的熟悉Pandas以及其他這一系列文章中提到的庫的方式。再加上你永遠不知道的,你會找到一些你感興趣的東西的。
英文原文:http://www.datadependence.com/2016/05/scientific-python-pandas/
譯者:LuCima
《Linux雲端計算及運維架構師高薪實戰班》2018年08月27日即將開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Linux好文請點選【閱讀原文】哦
↓↓↓
