概述
本文主要摘自brendangregg大神的blog: http://www.brendangregg.com/blog/2018-01-17/measure-working-set-size.html,研究如何衡量一個特定業務程式的working set size。先不談概念,讓我們一起先思考一下為什麼要研究WSS呢?舉個例子來說,某些後臺daemon為了效能,喜歡在程式在啟動階段就建立好各種fixed-size的記憶體池,且不支援動態grow/shrink,這些記憶體池的真實利用率如何?是否存在浪費?訪問頻率如何?讀者可能會想到透過在記憶體池實現上做一些簡單統計,不難得到程式的訪問頻率或者冷熱記憶體頁。那麼如果是一個第三方程式呢?對測量的人來說是一個黑盒子,這種場景則只能嘗試在作業系統層來考慮。本文從Linux的角度系統闡述了目前的常用手段,有什麼缺陷以及一些最佳化手段。
作者
鄧剛,馬濤,Linux系統工程師,來自阿裡雲系統組。
本文中若有任何疏漏錯誤,有任何建議和意見,請回覆核心月談微信公眾號,或透過gavin.dg at linux.alibaba.com>或者 tao.ma at linux.alibaba.com反饋。
阿裡雲系統團隊,是由原淘寶核心組擴建而成,2013年淘寶核心組響應阿裡巴巴集團的號召,整建制轉入阿裡雲,開始為雲端計算底層系統構建完善的系統支援。 阿裡雲系統團隊是由一群具有高度使命感和自我追求的核心開發人員組成,團隊中的大多數人,都是活躍的社群核心開發人員。目前的工作領域主要涉及(但不限於) Linux內核的記憶體管理、檔案系統、網路和核心維護構建,以及和核心相關聯的使用者態庫和工具。如果你對我們的工作很感興趣,歡迎加入我們,請將簡歷傳送至 tao.ma at linux.alibaba.com或者 boyu.mt at alibaba-inc.com。
正文
Working Set Size(WSS)是指一個app保持正常執行所須的記憶體。比如一個應用在初始階段申請了100G主存,在實際正常執行時每秒只需要50M,那麼這裡的50M就是一個WSS。評估WSS能幹嘛呢?它可以用來進行記憶體容量規劃併進行必要的記憶體擴容或者軟體最佳化。這個問題並不新鮮而且非常重要,然而brendangregg卻表示至今為止沒有實際可用的有效工具(譯者註:嚴重同意,而且在翻譯這篇文章之前譯者也開發了類似工具,在阿裡巴巴內部使用)。有經驗的讀者可能會註意到Linux top命令的輸出中,有兩列分別是VIRT與RES,其中VIRT是行程使用的虛擬記憶體地址空間大小,而RES則是實際使用的物理記憶體(如果考慮共享對映等,則需要用到smaps proc檔案的PSS或者top命令的SHARE,不過這兩者對於理解WSS無益,故不在此展開)。比如,一個行程剛啟動時透過私有匿名映射了(map_flags=MAP_PRIVATE | MAP_ANON)100G記憶體,然後實際只訪問其中50G,那麼VIRT=100G,RES=50G。那麼問題來了,如何評估這50G記憶體的訪存頻率呢?是否存在明顯的冷熱區分呢?針對這個問題,brendangregg開發了兩款基於Linux系統的小工具,下文將分別詳細介紹。
Method 1: Referenced Page flag
這是基於Linux Kernel 2.6.22引入的一個特性:the ability to set and read the referenced page flag from user space, added for analyzing memory usage. brendangregg大神基於此實現了一個https://github.com/brendangregg/wss wss.pl工具,下麵的案例在0.1s記憶體測量mysqld(PID=423)的WSS:

上面表示0.1秒內mysqld訪問了28M物理記憶體(總記憶體403.66M)。為什麼選取0.1s而不是更長?大神解釋說這樣短時間段內的測量可以幫助我們正確評估業務程式對CPU cache的使用(比如L1/L2/L3, TLB L1/L2等)。28M略大於CPU LLC的大小,所以cache並非工作得很完美。這個工具也支援累計樣式,僅重置一次referenced flag然後以固定間隔持續採集,輸出如下:

可以看到WSS在逐漸增加。其中各列的含義:
Est(s): 採集時刻;
RSS(MB):物理機記憶體使用(MBytes);
PSS(MB):按共享對映的次數,均攤算出的物理記憶體使用量(MBytes);
Ref(MB):在Est(s)內,行程實際訪問過的記憶體(MBytes)。
細心的讀者可能會發現,資料中的Est並非恰好是整數秒。這裡的原因是因為程式本身在重置referenced flag或者從proc介面讀取都需要消耗一定的時間,而且隨著行程使用的記憶體越多,開銷越大。
這個小工具的原理什麼呢?對x86 MMU架構有瞭解的讀者應該知道PTE有一個bit為 accessed bit。它的特性是:一旦CPU訪問了一個記憶體地址,那麼該地址相應的PTE的accessed bit將會被置上。這是一個硬體特性,至於如果利用它則需要我們一起發揮想象力了。著名的linux mm 子系統裡的LRU頁框回收演演算法,在除了以軟體的方式打tag之外,就依賴了該bit來區分頁的冷熱程度。這裡多說一句,其實WSS這個小工具的目的是找出特定時間段內被訪問過的頁,而LRU則是找出最近一段時間段內未被訪問過或訪問頻率低的頁,本質上是不是很像呢?所以大家都是用了相同的bit,做了類似的事情。回到正題,David Rientjes在2007年提了一個patchhttp://lkml.iu.edu/hypermail/linux/kernel/0702.1/0628.html,用於從核心匯出檔案/proc/PID/clear_refs,使用者可以在使用者態透過對特定行程清理page referenced flag,這樣在/proc/PID/smaps檔案中就可以檢視被訪問過的記憶體大小了。
這個工具的缺陷非常明顯,比如可能影響到被測試的業務行程(比如延遲增加10%,對於100G記憶體的行程,影響時間超過1s),而且該工具自身也需要消耗system time。另外,該工具由於從使用者態介面清理了page referenced flag,這也將影響到LRU演演算法的準確度,尤其是swap開啟以後,很可能將一些熱記憶體頁判定為冷記憶體並swap到disk。更嚴重的是,一些老核心還有panic風險。在Linux 4.3+版本中的引入了idle page flag特性可以解決此處提到的部分缺陷,後文再詳細介紹。
WSS profile charts
brendangregg大神尤其擅長將各種效能數字圖形化,本文當然也不例外。wss.pl支援profile樣式(-P),以等比數列步長(即當前步長 = 上一次步長 * 2)進行統計,輸出如下:

每相鄰兩行的採集間隔成等比遞增:短取樣間隔可以用來評估行程對cpu cache的利用,長取樣間隔則用來評估行程的物理記憶體使用趨勢。註意這僅是採集一輪的資料(譯者註:僅在取樣的初始階段清理一次page referenced flag,可以理解為 1* write + N * read,如果讀者想得到更一般化的資料,則應該採集多輪)。將上面的採集資料圖形化展示:

uniform 是指100M地址空間內uniform access distribution (譯者註:應是指“勻速”訪問100M地址空間),可以看到除第一個點外,其他點均穩定在100M,這是因為此時uniform訪問的行程還沒來得及訪問整個地址空間。為了對比,將地址空間調整為2G,如下圖所示(分別是對數坐標曲線以及線性曲線):


Method 2: Idle Page Flag
Idle page flag 是Vladimir Davydov在Linux4.3中實現的一個新特性,引入了兩種新的page flag:idle和young,它彌補了方案一的一個重要缺陷:影響page reclaim的邏輯。該方案仍然是基於PTE的accessed bit,透過在page_ext_flags引入了額外的idle&&young; page flag來保證page reclaim的邏輯不受此影響(譯者註:此處關於idle page tracking實現的描述不夠準確,譯者理解如下:方案一的缺陷在於清理PTE的accessed bit會導致page reclaim的邏輯誤判某些熱頁為冷頁,那麼透過引入一個軟體上的young flag來輔助記錄此頁為熱頁,清理accessed bit時將flag置位。這樣page reclaim如果遇到young flag置位的頁則認為其最近同樣被訪問過)。另外,上述兩個flag在64bit的kernel中被直接定義為page flag,在32bit的kerne中由於page flags空間不夠用,則基於page extension特性來定義。以下摘自核心原始碼樹中的檔案Documentation/vm/idle_page_tracking.txt vm/idle_page_tracking.txt:
That said, in order to estimate the amount of pages that are not used by a workload one should:
Mark all the workload’s pages as idle by setting corresponding bits in /sys/kernel/mm/page_idle/bitmap. The pages can be found by reading /proc/pid/pagemap if the workload is represented by a process, or by filtering out alien pages using /proc/kpagecgroup in case the workload is placed in a memory cgroup.
Wait until the workload accesses its working set.
Read /sys/kernel/mm/page_idle/bitmap and count the number of bits set. If one wants to ignore certain types of pages, e.g. mlocked pages since they are not reclaimable, he or she can filter them out using /proc/kpageflags.
brendangregg基於此特性寫了兩個版本的工具,在github https://github.com/brendangregg/wss 可以獲取原始碼,執行截圖如下:
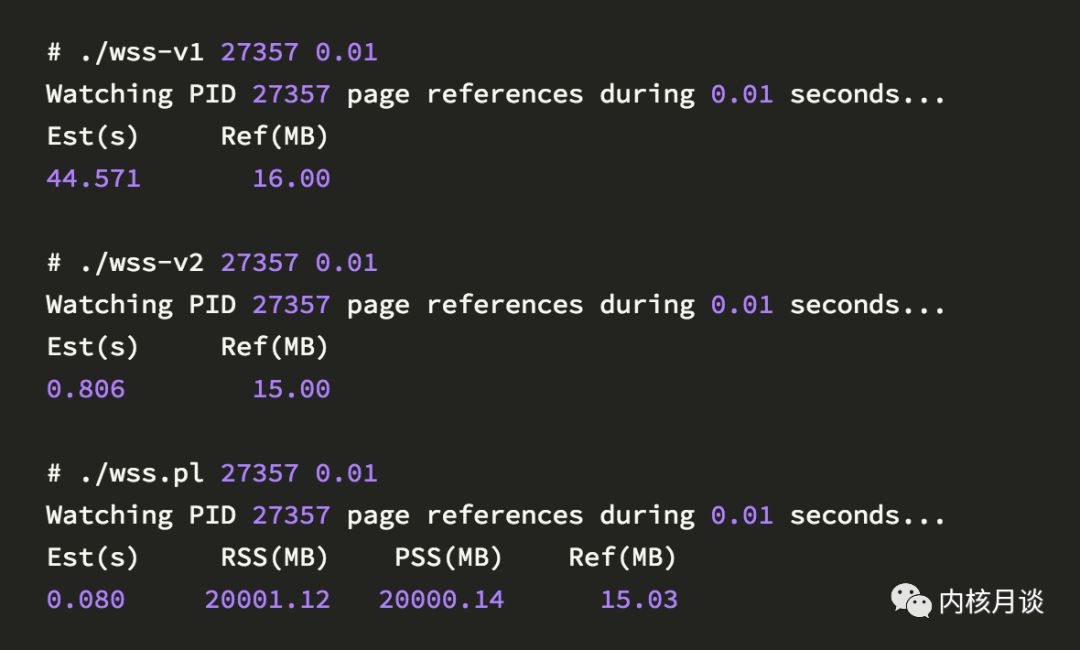
這裡v1與v2在統計結果上沒有差別,主要在於實現方式上:v1每次是一個page為單位進行處理,而v2是batch處理,以maps檔案中的每一行(即vma)為單位進行處理,時間消耗從44s降為0.8s。(譯者註:之前提到的譯者自己寫的工具也實現了類似的功能,採用的是v1與v2的折中方案,每次以65536個page為單位處理,不過考慮到測量行程本身的CPU開銷以及記憶體使用,最後放棄該方案)。brendangregg還提到瞭如果pagemap,idlebitmap,kpagecgroup等支援mmap(2)系統呼叫,可以避免過多的系統呼叫。同時大神還想一次性把系統所有page的idle flag都設定上,這樣可以得到整機的快照(譯者註:idle page tracking只支援掃描LRU連結串列上的頁,對net/kmalloc等kmem是透明的)。另外,第一次取樣間隔預期是0.01s(而目前掃描一次最小消耗0.8s),為了實現這個標的,brendangregg提到可以透過傳送SIGSTOP以及SIGCONT讓被測量的行程停止執行,顯然這很可能影響行程的正常邏輯,比如影響tcp視窗,觸發超時等。(譯者註:brendangregg似乎更關註於細粒度的取樣,輔助效能分析;其實粗粒度取樣也有參考價值,可以分析記憶體利用率或者叢集排程等,此為後話)。
結語
由於目前沒有有效的工具來測量WSS,所以brendangregg大神嘗試寫了兩個小工具。同時他還有一篇文章提到了一些其他方案來預估WSS,比如PMC,見http://www.brendangregg.com/wss.html ,裡面有一些更深入的討論,讀者有興趣可自行前往一觀。另外,譯者在阿裡內部也實現了幾個不同版本的工具,實現原理類似,方法則有不小的差異,歡迎大家來阿裡一起切磋。
