點選上方“芋道原始碼”,選擇“置頂公眾號”
技術文章第一時間送達!
原始碼精品專欄
天池中介軟體大賽Golang版Service Mesh思路分享
這次天池中介軟體效能大賽初賽和複賽的成績都正好是第五名,出乎意料的是作為Golang是這次比賽的“稀缺物種”,這次在前十名中我也是僥倖存活在C大佬和Java大佬的中間。
關於這次初賽《Service Mesh for Dubbo》難度相對複賽《單機百萬訊息佇列的儲存設計》簡單一些,最終成績是6983分,因為一些Golang的小夥伴在正式賽512併發壓測的時候大多都卡在6000分大關,這裡主要跟大家分享下我在這次Golang版本的一些心得和踩過的坑。
由於工作原因實在太忙,比賽只有週末的時間可以突擊,下一篇我會抽空整理下複賽《單機百萬訊息佇列的儲存設計》的思路方案分享給大家,個人感覺實現方案上也是決賽隊伍中比較特別的。
What’s Service Mesh?
Service Mesh另闢蹊徑,實現服務治理的過程不需要改變服務本身。透過以proxy或sidecar形式部署的 Agent,所有進出服務的流量都會被Agent攔截並加以處理,這樣一來微服務場景下的各種服務治理能力都可以透過Agent來完成,這大大降低了服務化改造的難度和成本。而且Agent作為兩個服務之間的媒介,還可以起到協議轉換的作用,這能夠使得基於不同技術框架和通訊協議建設的服務也可以實現互聯互通,這一點在傳統微服務框架下是很難實現的。
下圖是一個官方提供的一個評測框架,整個場景由5個Docker 實體組成(藍色的方框),分別運行了 etcd、Consumer、Provider服務和Agent代理。Provider是服務提供者,Consumer是服務消費者,Consumer消費Provider提供的服務。Agent是Consumer和Provider服務的代理,每個Consumer或 Provider都會伴隨一個Agent。etcd是登錄檔服務,用來記錄服務註冊資訊。從圖中可以看出,Consumer 與Provider 之間的通訊並不是直接進行的,而是經過了Agent代理。這看似多餘的一環,卻在微服務的架構演進中帶來了重要的變革。

有關Service Mesh的更多內容,請參考下列文章:
-
What’s a service mesh? And why do I need one? (中文翻譯)
-
聊一聊新一代微服務技術 Service Mesh
賽題要求
-
服務註冊和發現
-
協議轉換(這也是實現不同語言、不同框架互聯互通的關鍵)
-
負載均衡
-
限流、降級、熔斷、安全認證(不作要求)
當然Agent Proxy最重要的就是通用性、可擴充套件性強,透過增加不同的協議轉換可以支援更多的應用服務。最後Agent Proxy的資源佔用率一定要小,因為Agent與服務是共生的,服務一旦失去響應,Agent即使擁有再好的效能也是沒有意義的。
Why Golang?
個人認為關於Service Mesh的選型一定會在Cpp和Golang之間,這個要參考公司的技術棧。如果追求極致的效能還是首選Cpp,這樣可以避免Gc問題。因為Service Mesh鏈路相比傳統Rpc要長,Agent Proxy需要保證輕量、穩定、效能出色。
關於技術選型為什麼是Golang?這裡不僅僅是為了當做一次鍛煉自己Golang的機會,當然還出於以下一些原因:
-
一些大廠的經驗沉澱,比如螞蟻Sofa Mesh,新浪Motan Mesh等。
-
K8s、docker在微服務領域很火,而且以後Agent的部署一定依託於k8s,所以Go是個不錯的選擇,親和度高。
-
Go有協程,有高質量的網路庫,高效能方面應該佔優勢。
最佳化點剖析
官方提供了一個基於Netty實現的Java Demo,由於是阻塞版本,所以效能並不高,當然這也是對Java選手的一個福音了,可以快速上手。其他語言相對起步較慢,全部都要自己重新實現。
不管什麼語言,大家的最佳化思路大部分都是一樣的。這裡分享一下Kirito徐靖峰非常細緻的思路總結(Java版本):天池中介軟體大賽dubboMesh最佳化總結(qps從1000到6850),大家可以作為參考。
下麵這張圖基本涵蓋了在整個agent所有最佳化的工作,圖中綠色的箭頭都是使用者可以自己實現的。
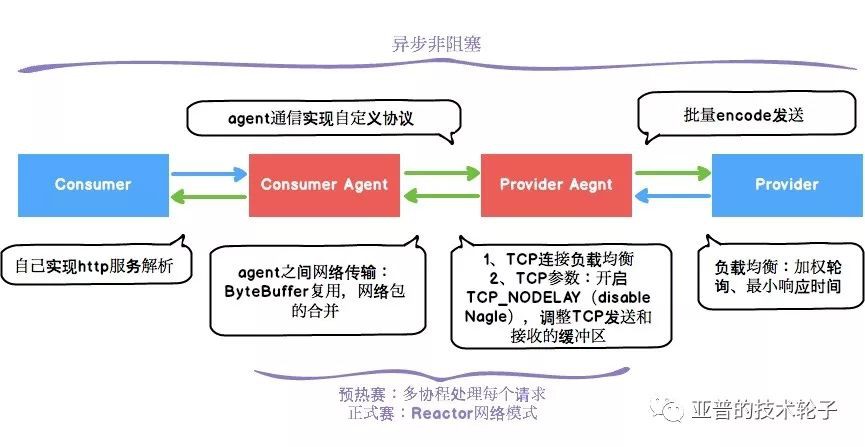
-
全部過程變成
非同步非阻塞、無鎖,所有請求均採用非同步回呼的形式。這也是提升最大的一點。 -
自己實現Http服務解析。
-
Agent之間通訊採用最簡單的自定義協議。
-
網路傳輸中
ByteBuffer復用。 -
Agent之間通訊
批次打包傳送。1ForBlock:
2for {
3 httpReqList[reqCount] = req
4 agentReqList[reqCount] = &AgentRequest;{
5 Interf: req.interf,
6 Method: req.callMethod,
7 ParamType: ParamType_String,
8 Param: []byte(req.parameter),
9 }
10 reqCount++
11 if reqCount == *config.HttpMergeCountMax {
12 break
13 }
14 select {
15 case req = 16 default:
17 break ForBlock
18 }
19} -
Provider負載均衡:加權輪詢、
最小響應時間(效果並不是非常明顯) -
Tcp連線負載均衡:支援按最小請求數選擇Tcp連線。
-
Dubbo請求
批次encode。 -
Tcp引數的最佳化:開啟TCP_NODELAY(disable Nagle algorithm),調整Tcp傳送和讀寫的緩衝區大小。
1if err = syscall.SetsockoptInt(fd, syscall.IPPROTO_TCP, syscall.TCP_NODELAY, *config.Nodelay); err != nil {
2 logger.Error("cannot disable Nagle's algorithm", err)
3}
4
5if err := syscall.SetsockoptInt(fd, syscall.SOL_SOCKET, syscall.SO_SNDBUF, *config.TCPSendBuffer); err != nil {
6 logger.Error("set sendbuf fail", err)
7}
8if err := syscall.SetsockoptInt(fd, syscall.SOL_SOCKET, syscall.SO_RCVBUF, *config.TCPRecvBuffer); err != nil {
9 logger.Error("set recvbuf fail", err)
10}
網路辛酸史 —— (預熱賽256併發壓測4400~4500)
Go因為有協程以及高質量的網路庫,協程切換代價較小,所以大部分場景下Go推薦的網路玩法是每個連線都使用對應的協程來進行讀寫。

這個版本的網路模型也取得了比較客觀的成績,QPS最高大約在4400~4500。對這個網路選型簡單做下總結:
-
Go因為有goroutine,可以採用多協程來解決併發問題。
-
在linux上Go的網路庫也是採用的epoll作為最底層的資料收發驅動。
-
Go網路底層實現中同樣存在“背景關係切換”的工作,只是切換工作由runtime排程器完成。
網路辛酸史 —— (正式賽512併發壓測)
然而在正式賽512併發壓測的時候我們的程式並沒有取得一個穩定提升的成績,大約5500 ~ 5600左右,cpu的資源佔用率也是比較高的,高達約100%。
獲得高分的秘訣分析:
-
Consumer Agent壓力繁重,給Consumer Agent減壓。
-
由於Consumer的效能很差,Consumer以及Consumer Agent共生於一個Docker實體(4C 8G)中,只有避免資源爭搶,才能達到極致效能。
-
Consumer在壓測過程中Cpu佔用高達約350%。
-
為了避免與Consumer爭搶資源,需要把Consumer Agent的資源利用率降到極致。
透過上述分析,我們確定了最佳化的核心標的:
盡可能降低Consumer Agent的資源開銷。
a. 最佳化方案1:協程池 + 任務佇列(廢棄)
這是一個比較簡單、常用的最佳化思路,類似執行緒池。雖然有所突破,但是並沒有達到理想的效果,cpu還是高達約70~80%。Goroutine雖然開銷很小,畢竟高併發情況下還是有一定背景關係切換的代價,只能想辦法再去尋找一些效能的突破。
經過慎重思考,我最終還是決定嘗試採用類似netty的reactor網路模型。關於Netty的架構學習在這就不再贅述,推薦同事的一些分享總結閃電俠的部落格。
b. 最佳化方案2:Reactor網路模型
選型之前諮詢了幾位好朋友,都是遭到一頓吐槽。當然他們沒法理解我只有不到50%的Cpu資源可以利用的困境,最終還是毅然決然地走向這條另類的路。
經過一番簡單的調研,我找到了一個看上去還挺靠譜(Github Star2000, 沒有一個PR)的開源第三方庫evio,但是真正實踐下來遇到太多坑,而且功能非常簡易。不禁感慨Java擁有Netty真的是太幸福了!Java取得成功的原因在於它的生態如此成熟,Go語言這方面還需要時間的磨煉,高質量的資源太少了。
當然不能全盤否定evio,它可以作為一個學習網路方面很好的資源。先看Github上一個簡單的功能介紹:
1evio is an event loop networking framework that is fast and small. It makes direct epoll and kqueue syscalls rather than using the standard Go net package, and works in a similar manner as libuv and libevent.
說明:關於kqueue是FreeBSD上的一種的多路復用機制,推薦學習。
為了能夠達到極致的效能,我對evio進行了大量改造:
-
支援主動連線(預設只支援被動連線)
-
支援多種協議
-
減少無效的喚醒次數
-
支援非同步寫,提高吞吐率
-
修複Linux下諸多bug造成的效能問題
改造之後的網路模型也是取得了很好的效果,可以達到6700+的分數,但這還遠遠不夠,還需要再去尋找一些突破。
c. 復用EventLoop
對最佳化之後的網路樣式再進行一次梳理(見下圖):

可以把eventLoop理解為io執行緒,在此之前每個網路通訊c->ca,ca->pa,pa->p都單獨使用的一個eventLoop。如果入站的io協程和出站的io協程使用相同的協程,可以進一步降低Cpu切換的開銷。於是做了最後一個關於網路模型的最佳化:復用EventLoop,透過判斷連線型別分別處理不同的邏輯請求。
1func CreateAgentEvent(loops int, workerQueues []chan *AgentRequest, processorsNum uint64) *Events {
2 events := &Events;{}
3 events.NumLoops = loops
4
5 events.Serving = func(srv Server) (action Action) {
6 logger.Info("agent server started (loops: %d)", srv.NumLoops)
7 return
8 }
9
10 events.Opened = func(c Conn) (out []byte, opts Options, action Action) {
11 if c.GetConnType() != config.ConnTypeAgent {
12 return GlobalLocalDubboAgent.events.Opened(c)
13 }
14 lastCtx := c.Context()
15 if lastCtx == nil {
16 c.SetContext(&AgentContext;{})
17 }
18
19 opts.ReuseInputBuffer = true
20
21 logger.Info("agent opened: laddr: %v: raddr: %v", c.LocalAddr(), c.RemoteAddr())
22 return
23 }
24
25 events.Closed = func(c Conn, err error) (action Action) {
26 if c.GetConnType() != config.ConnTypeAgent {
27 return GlobalLocalDubboAgent.events.Closed(c, err)
28 }
29 logger.Info("agent closed: %s: %s", c.LocalAddr(), c.RemoteAddr())
30 return
31 }
32
33 events.Data = func(c Conn, in []byte) (out []byte, action Action) {
34 if c.GetConnType() != config.ConnTypeAgent {
35 return GlobalLocalDubboAgent.events.Data(c, in)
36 }
37
38 if in == nil {
39 return
40 }
41 agentContext := c.Context().(*AgentContext)
42
43 data := agentContext.is.Begin(in)
44
45 for {
46 if len(data) > 0 {
47 if agentContext.req == nil {
48 agentContext.req = &AgentRequest;{}
49 agentContext.req.conn = c
50 }
51 } else {
52 break
53 }
54
55 leftover, err, ready := parseAgentReq(data, agentContext.req)
56
57 if err != nil {
58 action = Close
59 break
60 } else if !ready {
61 data = leftover
62 break
63 }
64
65 index := agentContext.req.RequestID % processorsNum
66 workerQueues[index] 67 agentContext.req = nil
68 data = leftover
69 }
70 agentContext.is.End(data)
71 return
72 }
73 return events
74}
復用eventloop得到了一個比較穩健的成績提升,每個階段的eventloop的資源數都設定為1個,最終512併發壓測下cpu資源佔用率約50%。
Go語言層面的一些最佳化嘗試
最後階段只能喪心病狂地尋找一些細節點,所以也對語言層面做了一些嘗試:
-
Ringbuffer來替代Go channel實現任務分發
RingBuffer在高併發任務分發的場景中比Channel效能有小幅度提升,但是站在工程的角度,個人還是推薦Go channel這種更加優雅的做法。
-
Go自帶的encoding/json包是基於反射實現的,效能是個詬病
使用字串自己拼裝Json資料,這樣壓測的資料越多,節省的時間越多。
-
Goroutine執行緒系結
1runtime.LockOSThread()
2defer runtime.UnlockOSThread() -
修改排程器預設時間片大小,自己編譯Go語言(沒啥效果)
總結
-
劍走偏鋒,花費了大量時間去改造網路,功夫不負有心人,結果是令人欣慰的。
-
Golang在高效能方面是足夠出色的,值得深入研究學習。
-
效能最佳化離不開的一些套路:非同步、去鎖、復用、零複製、批次等。
最後丟擲幾個想繼續探討的Go網路問題,和大家一起討論,有經驗的朋友還希望能指點一二:
-
在資源稀少的情況下,處理高併發請求的網路模型你會怎麼選型?(假設併發為1w長連線或者短連線)
-
百萬連線的規模下又將如何選型?
如果你對 Dubbo 感興趣,歡迎加入我的知識星球一起交流。

目前在知識星球(https://t.zsxq.com/2VbiaEu)更新瞭如下 Dubbo 原始碼解析如下:
01. 除錯環境搭建
02. 專案結構一覽
03. 配置 Configuration
04. 核心流程一覽
05. 拓展機制 SPI
06. 執行緒池
07. 服務暴露 Export
08. 服務取用 Refer
09. 註冊中心 Registry
10. 動態編譯 Compile
11. 動態代理 Proxy
12. 服務呼叫 Invoke
13. 呼叫特性
14. 過濾器 Filter
15. NIO 伺服器
16. P2P 伺服器
17. HTTP 伺服器
18. 序列化 Serialization
19. 叢集容錯 Cluster
20. 優雅停機
21. 日誌適配
22. 狀態檢查
23. 監控中心 Monitor
24. 管理中心 Admin
25. 運維命令 QOS
26. 鏈路追蹤 Tracing
…
一共 60 篇++
原始碼不易↓↓↓↓↓
點贊支援老艿艿↓↓