mysql叢集方案這裡介紹2種,PXC 和 Replication。
大型網際網路程式使用者群體龐大,所以架構設計單節點資料庫已經無法滿足需求。大家也深有體會,有一萬人在學校網站查成績或是選課的時候網站時常是訪問不了或者相應特別特別慢。這種情況就凸顯出來單機單節點上效能的不足。無論你使用什麼樣的資料庫免費的或者付費的單機單節點都是無法承受某個點上面的併發的,另外一方面就是資料庫沒有做冗餘設計。這時候我們就需要做叢集和冗餘保證資料庫的高可用和高效能提升使用者體驗。
下麵我們先來用一組資料來做資料庫單節點壓力測試:
1.使用5000個使用者做5000次查詢,平均下拉每個使用者查詢一次。

我們看到系統結果顯示5000次併發的話執行的時間是 7.671秒,以上5000併發來講的話資料庫發揮還是比較正常的沒有出現崩潰宕機。
2.下麵我們把5000次併發和查詢次數都增大1倍改成10000看看會出現什麼情況。

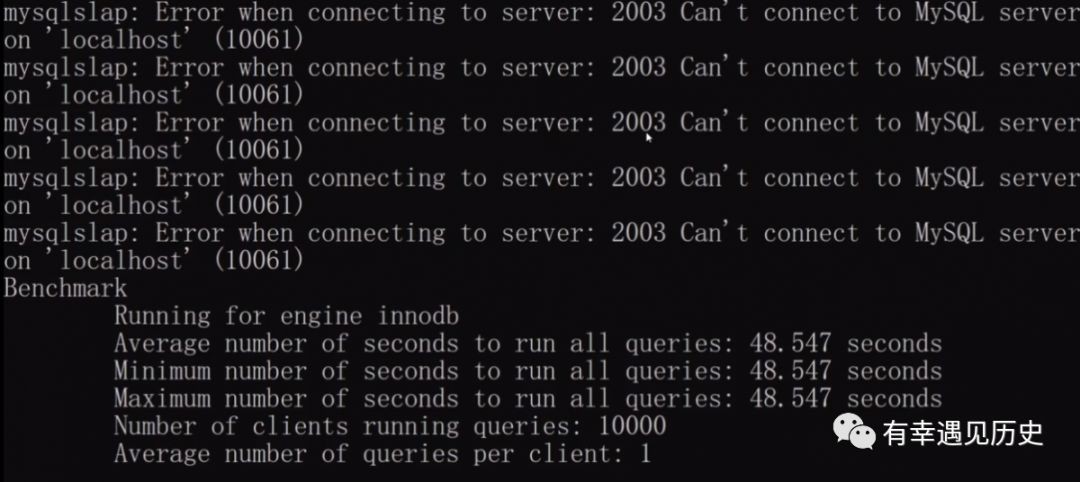
如上當併發為10000的時候系統提示 沒有那麼多的連線應對併發的訪問,系統拒絕了很多請求。最終執行的結果是48.547秒,這並不是說系統執行了我們所有的請求,它只是執行了一部分用了48秒。那麼我們如果在網站上使用單機單節點的部署只要有1000併發訪問那麼系統馬上崩潰!這還僅僅是1000個使用者,那麼對於搞電商的同學如何來應對運營的秒殺 促銷活動?所以對於我們晨光這樣的大公司在做資料庫設計的時候一定採用叢集叢集叢集這樣的方案。
接下來我們介紹一下晨光科力普資料庫叢集是如何去設計搭建以及如何進化的。
1.PXC方案
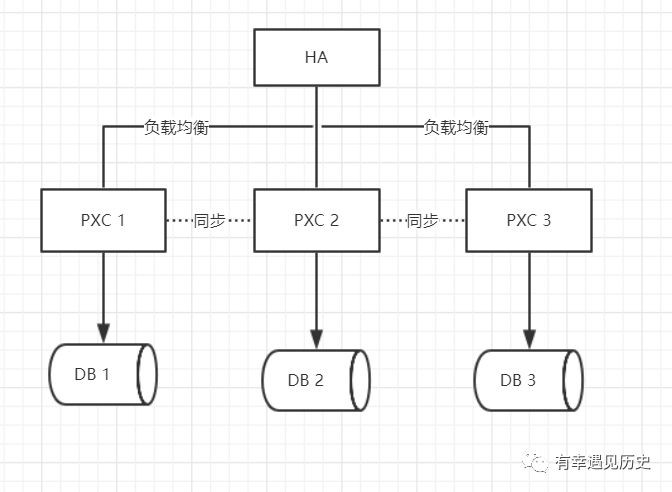
我們先是採用目前最主流的PXC方案把資料庫叢集在一起。PXC它最大的特性就是讀寫強一致並且每個節點都是可以作為讀寫的入口,這種方案的好處就是我們無論在任何一個節點寫入資料那麼其他的庫肯定會同步到這條資料,絕對絕對不會出現說在A庫上面寫資料然後B庫查不到這種假設。
我們使用 haproxy 負載均衡中介軟體,當HA接收到一個增刪改查的請求時他會把你的sql陳述句路由分發到不同的PXC節點讓他們去分別執行。
那麼你以為這樣的設計就Ok了?我告訴你這樣是遠遠不夠的,我們知道mysql有一個效能瓶頸就是單表資料超過2000W 那麼它的效能會急劇下降,所以我們在操作的時候要儘量避免單表儲存的資料超過2000W。
那麼這時候我們就要涉及到另外一個概念 資料切分, 所以資料切分我們還是採用同樣的PXC叢集方案如下圖:
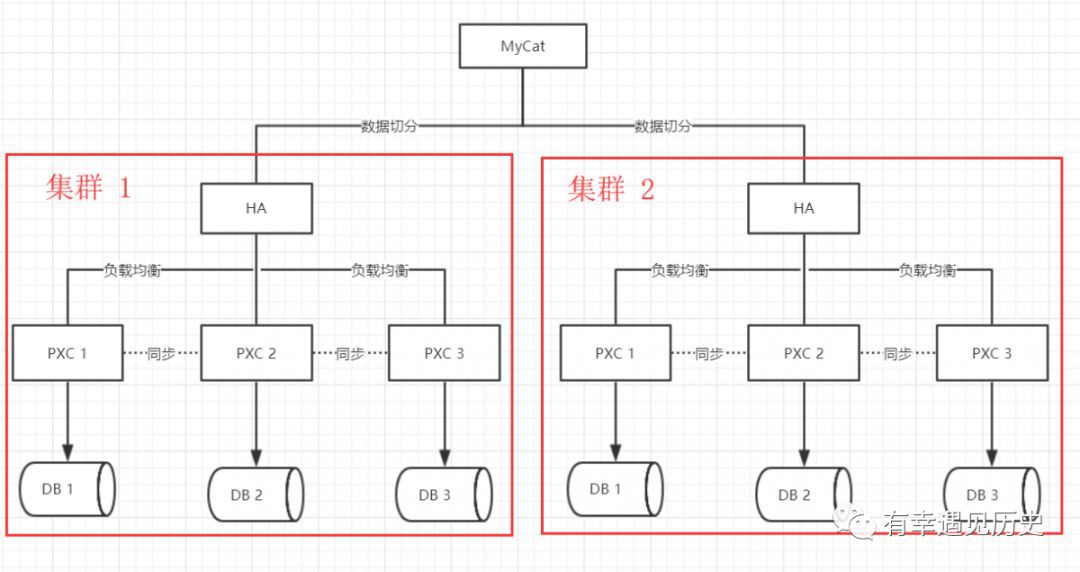
這裡我們使用MyCat做資料切分,MyCat是阿裡開源的一個mysql資料切分中介軟體,支援 離散分片(列舉,程式指定分割槽,十進位制求模,字串hash,一致hash)和 連續分片(自定義數字範圍,按日期分,按單月小時,按自然月分)等mysql資料庫分片策略。
這裡有個術語叫做分片,例如上圖中 叢集1是一個分片區 叢集2 就是另外一個分片區。
我們在執行一個Insert sql陳述句的時候mycat就可以根據指定的策略來儲存我們的資料,例如按照月份把 1月 3月 5月的資料儲存到叢集1中 其他月份的儲存在叢集2中。
採用這種方案我們就避免了mysql單表的效能瓶頸,如果2個叢集不夠就在加叢集,使勁加加ok。縱覽全域性這樣才是一個比較好的mysql叢集方案,但是。這樣還沒有完,PXC叢集方案是以犧效能為代價的,所以才保證了資料庫的強一致性,所以你的pxc資料庫越多效能就會越低,接下來我介紹另外一種叢集方案Replication。
2.Replication方案介紹

Replication這種方案不會犧牲效能,但是有個問題就是非強一致性,例如你在DB1中寫入資料可能會因為網路抖動在DB2中查詢不到資料,這時候客戶端接收到的狀態是已經操作成功。另外有一點是這種叢集方案只能在一個節點中做寫入操作,因為他的底層同步原理是單向同步的。
這種方案我們也會有mysql單表2000W資料瓶頸,我們也要做資料的切分,這裡也會用mycat這個中介軟體來做資料切分,如下圖:

以上2種方案,一種是資料強一致性,一種是非強一致性,強一致性的話可以用來儲存一些有價值的資料例如訂單,支付等,非強一致性方案可以用來儲存使用者的操作或者使用者行為瀏覽等資料。一個大型系統中單採用某一種方案是不夠的。下麵我們演進為2種方案結合使用如下圖。

我們可以根據不同的業務和資料等級讓MyCat來分片決定要把資料落到哪個庫上!
3. PXC介紹

PXC 全稱 Percona XtraDB Cluster,它是基於mysql自帶的一種叢集技術 Galera做的改進來實現的一種資料庫叢集方案,它有一個很明顯的特點就是任何節點都是可讀寫的,都可以被充當主節點來使用的。
並且他是資料強一致性的只要在任何一個節點種寫入資料其他的節點種肯定會同步到這條資料的。
PXC原理:
我們使用UML圖來介紹一下PXC的執行過程。

這裡我們用PXC中3個DB節點來介紹其原理,分別是DB1 DB3 和DB3, 資料的同步使用PXC。
先從clent說起 clent在執行insert del up 的時候,正常db1會給我們傳回執行的結果,如果我們不提交事務的話是不能持久化到資料庫中的。我們想要真實的持久化就必須要提交事務。這裡在提交事務的時候不僅僅要在當前節點裡面持久化資料還要在其他節點持久化資料畢竟我們是在pxc環境中操作的。
首先在提交事務的時候,db1會把資料傳遞給pxc, pxc會複製當前節點的資料 然後分發給DB2 和DB3,分發後要做的就是持久化這些資料。
事務的執行操作在pxc中會生產一個GTID編號,然後由db2 和db3去分別執行這個事務,每個db執行完成後會把結果傳回給db1,然後db1收到其他db的執行結果後在本地也執行一下GTID的這個事務db1執行完成後沒問題問題的話最終會把執行的結果傳回給客戶端。
透過這個時序圖我們可以知道在pxc中的資料強一致,肯定是所有的資料庫中的資料都是一致的。
4: pxc與replication 方案優劣:
pxc 採用的是同步複製,事務在所有叢集中要麼全提交要麼不提交,保證了資料的一致性。它寫入資料速度慢
replication 採用的是非同步複製,無法保證資料的一致性。它寫入資料速度快。
這2種方案僅僅是都實現了資料的同步,沒有資料切分功能。
5:pxc與replication 方案組合:
pxc方案儲存高價值資料 如:賬戶 訂單 交易資料等。。
replication 方案儲存低價值資料:如 通知 日誌 等。。
用其他的中介軟體如mycat來切分資料管理叢集。
如果你覺得所有收穫請多多支援。

