
菜菜呀,咱們業務BJKJ有個表資料需要做遷移


現在有多少資料?


大約21億吧,2017年以前的資料沒有業務意義了,給你半天時間把這個事搞定,績效給你A
有績效獎金嗎?
錢的事你去問X總,我當家不管錢
………..
 1. 資料庫採用Sqlserver 2008 R2,單表資料量21億
1. 資料庫採用Sqlserver 2008 R2,單表資料量21億

2. 無水平或者垂直切分,但是採用了分割槽表。分割槽表策略是按時間降序分的區,將近30個分割槽。正因為分割槽表的原因,系統才保證了在效能不是太差的情況下堅持至今。
3. 此表除聚集索引之外,無其他索引,無主鍵(主鍵其實是利用索引來快速查重的)。所以在頻繁插入新資料的情況下,索引調整所耗費的效能比較低。



資料遷移工作包括三個個步驟:
1. 從源資料表查詢出要遷移的資料
2. 把資料插入新表
3. 把舊表的資料刪除
1. 從源資料表分頁獲取資料,具體分頁條數,太少則查詢原表太頻繁,太多則查詢太慢。
SQL陳述句類似於
SELECT * FROM (
SELECT *,ROW_NUMBER() OVER(ORDER BY class_id,in_time) p FROM tablexx WHERE in_time <'2017.1.1'
) t WHERE t.p BETWEEN 1 AND 1003. 把資料刪除,其實這裡刪除還是有一個小難點,表沒有標示列。這裡不展開,因為這不是菜菜要說的重點。
如果你的資料量不大,以上方法完全沒有問題,但是在9億這個數字前面,以上方法顯得心有餘而力不足。一個字:慢,太慢,非常慢。
可以大體算一下,假如每秒可以遷移1000條資料,大約需要的時間為(單位:分)
1. 在9億資料前查詢必須命中索引,就算是非聚集索引菜菜也不推薦,首推聚集索引。
2. 如果你瞭解索引的原理,你應該明白,不停的插入新資料的時候,索引在不停的更新,調整,以保持樹的平衡等特性。尤其是聚集索引影響甚大,因為還需要移動實際的資料。
提取以上兩點共同的要素,那就是聚集索引。相應的解決方案也就應運而生:
1. 按照聚集索分頁引查詢資料
2. 批次插入資料迎合聚集索引,即:按照聚集索引的順序批次插入。
3. 按照聚集索引順序批次刪除
1. 一個表的聚集索引的順序就是實際資料檔案的順序,對映到磁碟上,本質上位於同一個磁軌上,所以操作的時候磁碟的磁頭不必跳躍著去操作。
2. 儲存在硬碟中的每個檔案都可分為兩部分:檔案頭和儲存資料的資料區。檔案頭用來記錄檔案名、檔案屬性、佔用簇號等資訊,檔案頭儲存在一個簇並對映在FAT表(檔案分配表)中。而真實的資料則是儲存在資料區當中的。平常所做的刪除,其實是修改檔案頭的前2個程式碼,這種修改對映在FAT表中,就為檔案作了刪除標記,並將檔案所佔簇號在FAT表中的登記項清零,表示釋放空間,這也就是平常刪除檔案後,硬碟空間增大的原因。而真正的檔案內容仍儲存在資料區中,並未得以刪除。要等到以後的資料寫入,把此資料區改寫掉,這樣才算是徹底把原來的資料刪除。如果不被後來儲存的資料改寫,它就不會從磁碟上抹掉。
DateTime dtMax = DateTime.Parse("2017.1.1");
var allClassId = DBProxy.GeSourcetLstClassId(dtMax)?.OrderBy(s=>s); D int pageIndex = 1; //頁碼
int pageCount = 20000;//每頁的資料條數
DataTable tempData =null;
int successCount = 0;
foreach (var classId in allClassId)
{
tempData = null;
pageIndex = 1;
while (true)
{
int startIndex = (pageIndex - 1) * pageCount+1;
int endIndex = pageIndex * pageCount;
tempData = DBProxy.GetSourceDataByClassIdTable(dtMax, classId, startIndex, endIndex);
if (tempData == null || tempData.Rows.Count==0)
{
//最後一頁無資料了,刪除源資料源資料然後跳出
DBProxy.DeleteSourceClassData(dtMax, classId);
break;
}
else
{
DBProxy.AddTargetData(tempData);
}
pageIndex++;
}
successCount++;
Console.WriteLine($"班級:{classId} 完成,已經完成:{successCount}個");
}DBProxy 完整程式碼:
class DBProxy
{
//獲取要遷移的資料所有班級id
public static IEnumerable<int> GeSourcetLstClassId(DateTime dtMax)
{
var connection = Config.GetConnection(Config.SourceDBStr);
string Sql = @"SELECT class_id FROM tablexx WHERE in_time ;
using (connection)
{
return connection.Query<int>(Sql, new { dtMax = dtMax }, commandType: System.Data.CommandType.Text);
}
}
public static DataTable GetSourceDataByClassIdTable(DateTime dtMax, int classId, int startIndex, int endIndex)
{
var connection = Config.GetConnection(Config.SourceDBStr);
string Sql = @" SELECT * FROM (
SELECT *,ROW_NUMBER() OVER(ORDER BY in_time desc) p FROM tablexx WHERE in_time ) t WHERE t.p BETWEEN @startIndex AND @endIndex ";
using (connection)
{
DataTable table = new DataTable("MyTable");
var reader = connection.ExecuteReader(Sql, new { dtMax = dtMax, classId = classId, startIndex = startIndex, endIndex = endIndex }, commandType: System.Data.CommandType.Text);
table.Load(reader);
reader.Dispose();
return table;
}
}
public static int DeleteSourceClassData(DateTime dtMax, int classId)
{
var connection = Config.GetConnection(Config.SourceDBStr);
string Sql = @" delete from tablexx WHERE in_time ;
using (connection)
{
return connection.Execute(Sql, new { dtMax = dtMax, classId = classId }, commandType: System.Data.CommandType.Text);
}
}
//SqlBulkCopy 批次新增資料
public static int AddTargetData(DataTable data)
{
var connection = Config.GetConnection(Config.TargetDBStr);
using (var sbc = new SqlBulkCopy(connection))
{
sbc.DestinationTableName = "tablexx_2017";
sbc.ColumnMappings.Add("class_id", "class_id");
sbc.ColumnMappings.Add("in_time", "in_time");
.
.
.
using (connection)
{
connection.Open();
sbc.WriteToServer(data);
}
}
return 1;
}
}1915560 / 60=31926 條/秒
cpu情況(不高):

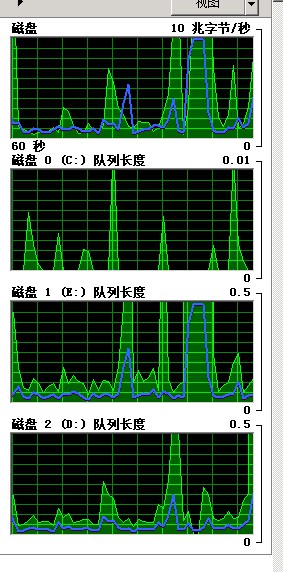
1. 源資料庫和標的資料庫硬碟為ssd,並且分別為不同的伺服器
2. 遷移程式和資料庫在同一個區域網,保障資料傳輸時候頻寬不會成為瓶頸
3. 合理的設定SqlBulkCopy引數
4. 菜菜的場景大多數場景下每次批次插入的資料量達不到設定的值,因為有的class_id 對應的資料量就幾十條,甚至幾條而已,開啟關閉資料庫連線也是需要耗時的
5. 單純的批次新增或者批次刪除操作


網際網路之路,菜菜與君一同成長
長按識別二維碼關註


