“君之所以明者,兼聽也;其所以暗者,偏信也。”——漢·王符《潛夫論·明暗》
資料分析,不管對於個人,還是公司,都是一種核心能力。和一些資料朋友聊天時,會談及一些有效的資料分析工具。一位友人說,“我用Python,Jupyter notebook和Python相應的庫(numpy, matplotlib,seaborn和pandas等)做資料分析工作,非常有效,也很便利”。懷揣著學習和進取的心態,我立刻在google上面檢索關鍵詞:python jupyter notebook data analysis,閱讀了一些與這個主題相關的系列文章,並且積極地進行實踐之,讓自己一來熟悉jupyter notebook這個工具,二來藉助這個工具實現更有效地做資料分析。同時,發現一篇用jupyter notebook做資料分析的淺顯易懂的教程,特翻譯之,以備學習之用。
譯者:王路情
作者:Wei Tang
原文連結:
http://www.storybench.org/getting-started-with-python-and-jupyter-notebooks-for-data-analysis/
讓我們討論一下用Python做資料分析。在本教程中,您將在使用Python和pandas探索資料集時學習一些簡單的資料分析過程。
在我們開始之前,請確保您已經為這個實踐設定了環境。請安裝Python 3.6、pandas和matplotlib。此外,我們將在本教程中使用一個Jupyter Notebook。如果您還沒有聽說過這個組合工具,那麼這一段 Linear Digressions 可以很好地解釋它們。
我將使用Anaconda,它是一個執行Python的平臺,包含一套資料分析工具。本教程將分為三個部分:問題、處理和探索。
在這裡下載本教程的Jupyter Notebook。
決定您的資料集和問題
資料分析總是從問題開始。反過來,這些將決定您收集什麼型別的資料。在本教程中,我們將探索NewsWhip在2016年11月至2017年5月期間收集的由世界500強新聞出版商釋出在Facebook上的10,000篇新聞文章的資料集。我們可能會問,哪些新聞機構在這組新聞中發表的文章最多,標題中最重要的關鍵詞是什麼。
將資料集匯入一個Jupyter Notebook
讓我們下載資料集,然後在一個Jupyter Notebook中匯入和開啟它。當你把Jupyter notebook 輸入終端時,一個Jupyter Notebook會立即啟動。
接下來,你將會看到這樣的一個頁面:
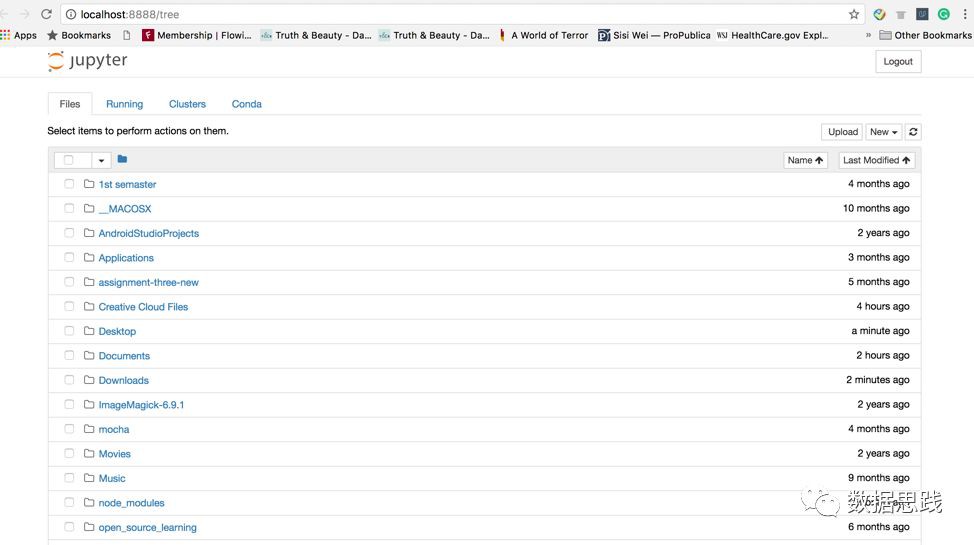
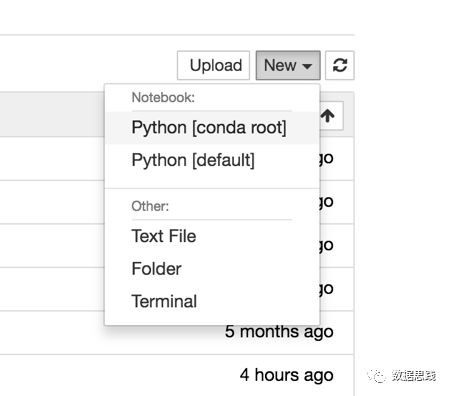
接下來,單擊upload按鈕上傳資料集。然後點選“新建”下拉選單,選擇Python [conda root]。
請跟隨我匯入本教程所需的所有包。
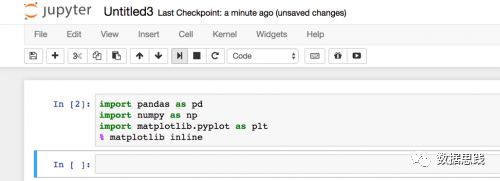
然後,讓我們匯入資料集
1df = pd.read_csv("file_name.csv")
透過輸入df.head(10),您可以檢視該資料集中的前10行。
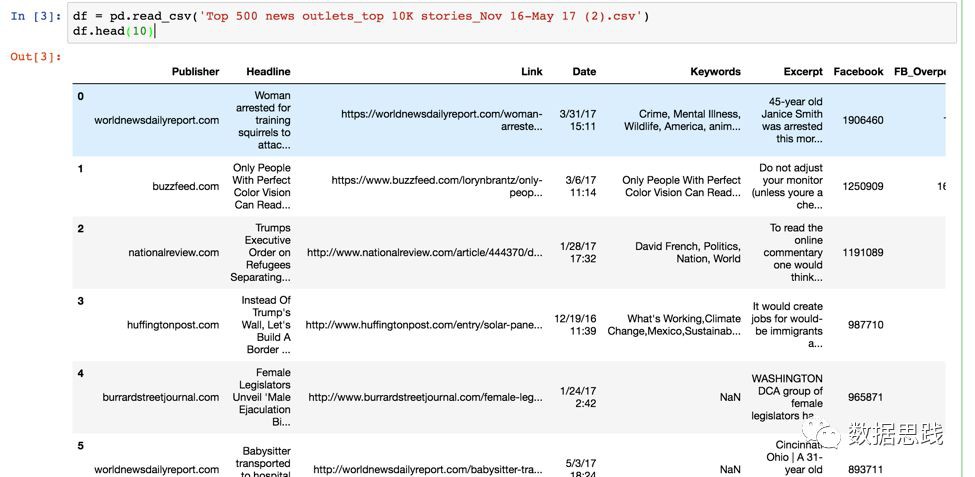
處理(Wrangle)
一旦我們匯入資料集之後,我們需要處理資料以幫助回答前面提到的問題。沒有一個資料集是完美的,這就是為什麼我們需要檢查這個資料集中的問題並修複它們。
讓我們輸入df.shape來檢查這個資料集中有多少列和行。

這意味著我們有10,000行和12列。接下來,輸入df.dtypes檢查每個列的資料型別。
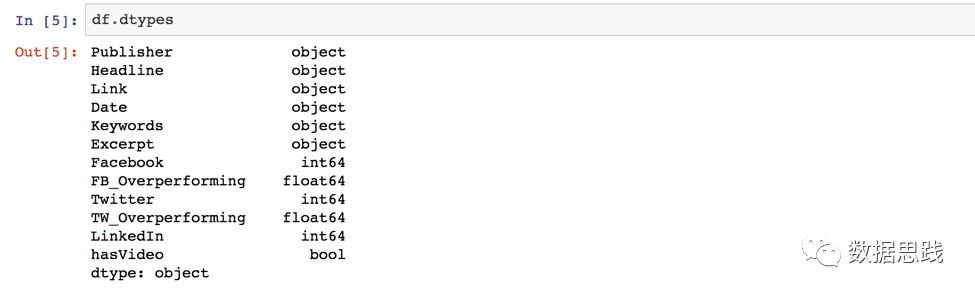
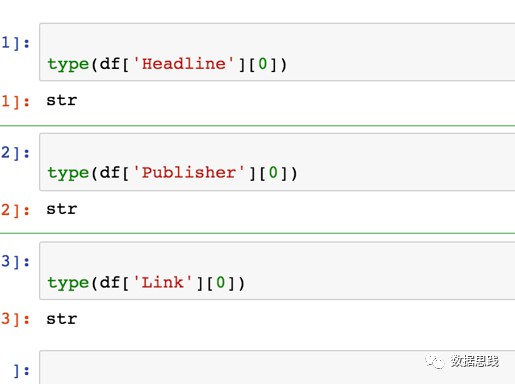
註意到Publisher, Headline, Link, 和Date都是作為物件列出的。這是奇怪的。進一步的研究表明,它們實際上是字串,我透過輸入:
1type(df['column name'][0])
將日期列從物件轉換為日期時間
讓我們將Date的資料型別從object更改為datetime。
輸入:
1df[' Date '] = pd.to_datetime(df[' Date '])
完成後,請輸入df.types,以確保它工作。
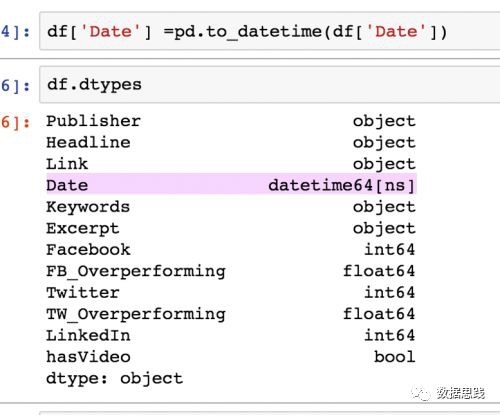
很好,Date的資料型別現在是datetime64[ns]。接下來,讓我們檢查這個資料集中是否有缺失的值。我們會輸入:
1df.info()
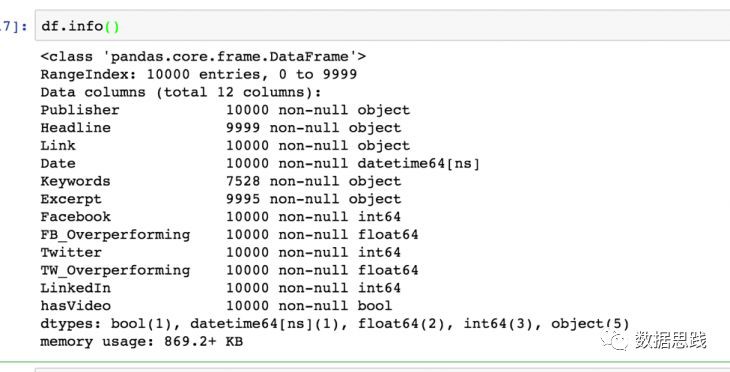
註意在Keywords,在10,000行中,只有7,528行包含Keywords列中的物件。這意味著大約有2500個缺失值。這意味著這些文章沒有關鍵詞。請記住這一點,因為在討論資料分析時,我們需要包括這一點。
接下來,我們輸入df.duplicate()檢查是否有任何重覆的資料

這看起來不錯。我們不需要刪除任何重覆的資料。
探索和視覺化資料
現在您已經清理了資料,您可以使用一些數學操作(如sum和count)來顯示資料中的樣式。透過使用value_counts函式,我們可以統計列中唯一值的個數。然後,我們可以呼叫結果上的plot函式來建立柱狀圖。
讓我們來算一下哪個出版商發表的文章最多。輸入:
1 df['column name’].value_counts()
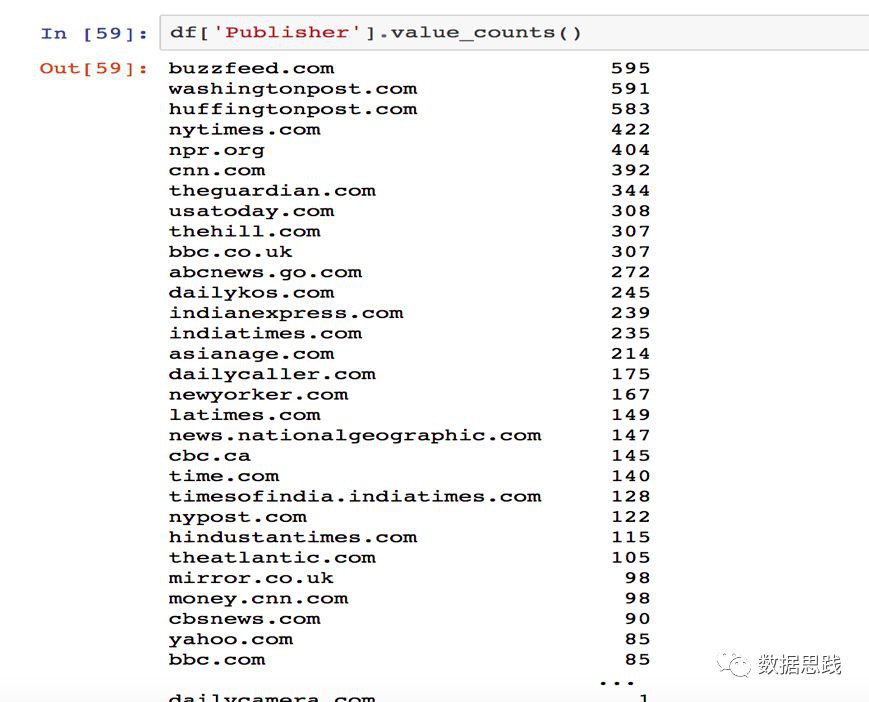
我們發現BuzzFeed在資料集中發表的文章最多。為了使其視覺化,我們可以使用matplotlib製作一個柱狀圖。在Jupyter notebook 中建立視覺化時,有一件事非常方便,那就是matplot inline,它允許您在notebook中檢視繪圖。
我們可以使用df[‘ Publisher ‘].value_counts()繪製一個簡單的柱狀圖。使用figsize改變圖的大小。
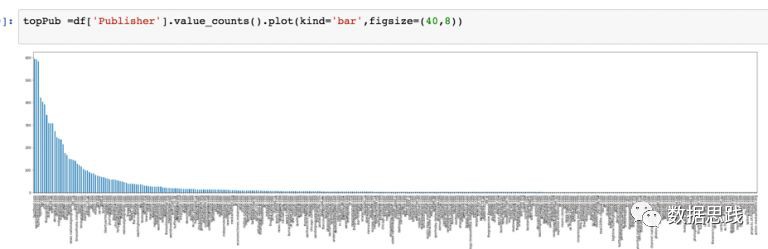
哇!這個圖有點亂。讓我們按降序來篩選前10位釋出者。
我們可以透過設定ascending = false來實現這一點,然後透過將top10[:10]分配給變數top10來獲得前Top10:
1top10 = df["Publisher"].value_counts()
2top10.sort_values(ascending=False)
3top10 = top10[:10]
4top10.plot(kind="bar")
然後,繪製變數Top10的柱狀圖:
1top10.plot(kind="bar")
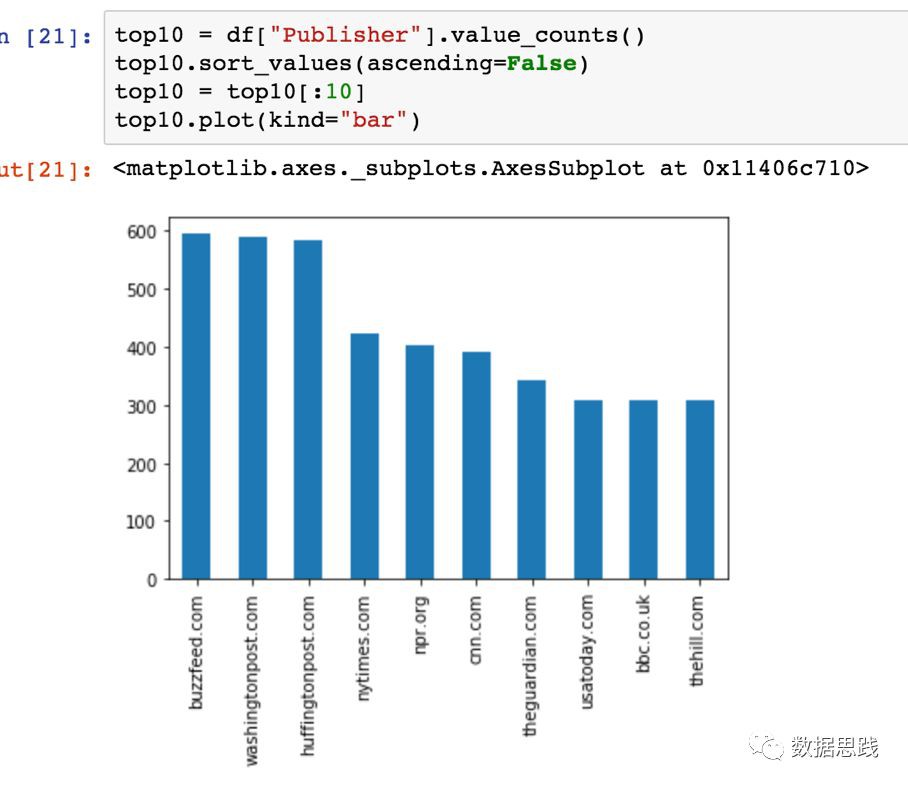
很好,我們得到了第一個柱狀圖!
繪製Top20的關鍵詞
接下來,讓我們嘗試建立一個柱狀圖來顯示Keywords列中的前20個關鍵字。
這個問題有點複雜,因為關鍵字不是單個單詞,而是由逗號分隔的字串。如果不這樣做,這就是我們所視覺化的:
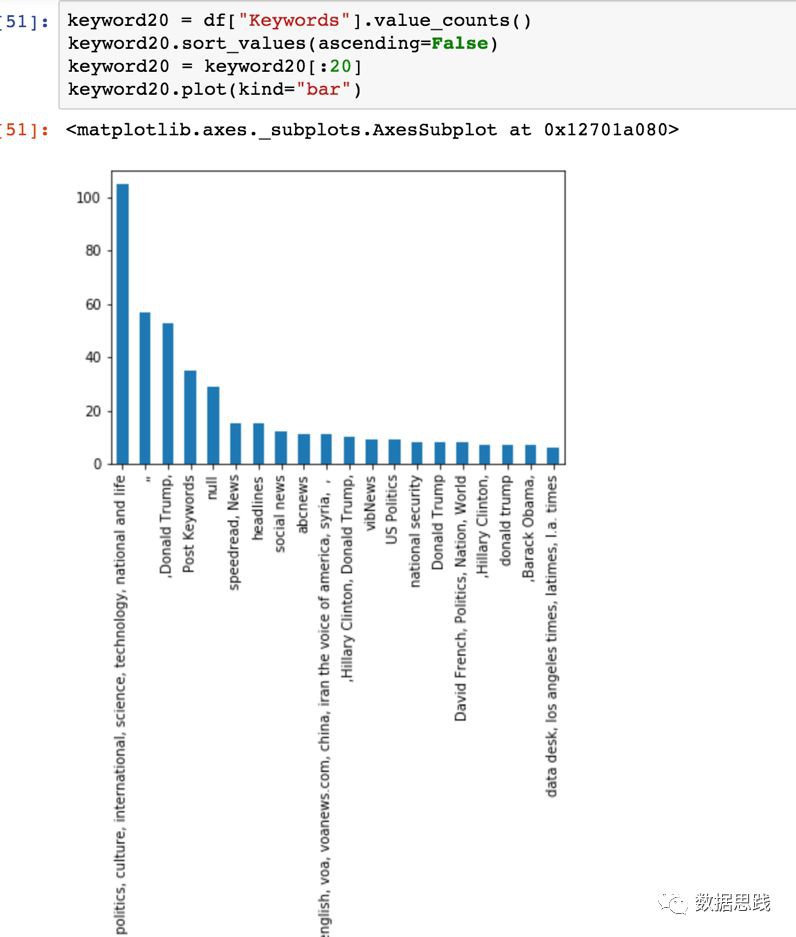
為了獲得準確的關鍵字計數,我們需要將列拆分為單個單詞並將它們放入陣列中—在panda中稱為series。
讓我們把這一列拆成單個單詞,並把它們放到一個序列中。然後,迴圈遍歷本序列中的每個單詞,我們就可以的關鍵字的準確計數。
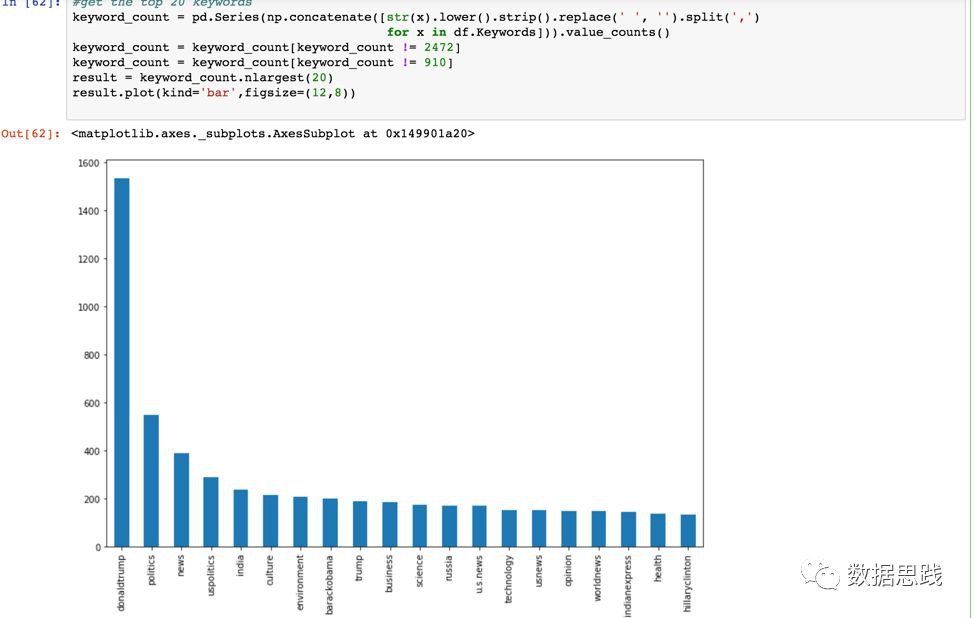

1keyword_count = pd.Series(np.concatenate([str(x).lower().strip().replace(' ', '').split(',')
2 for x in df.Keywords])).value_counts()
3keyword_count = keyword_count[keyword_count != 2472]
4keyword_count = keyword_count[keyword_count != 910]
5result = keyword_count.nlargest(20)
6result.plot(kind='bar',figsize=(12,8))
7print (keyword_count)
讓我解釋一下我寫的程式碼。第一行是計算關鍵字是NULL的總數,然後將它們從序列中刪除。第二行是計算關鍵字為空的總數,然後將它們從序列中刪除。
我們可以為這個結果做一個餅狀圖。
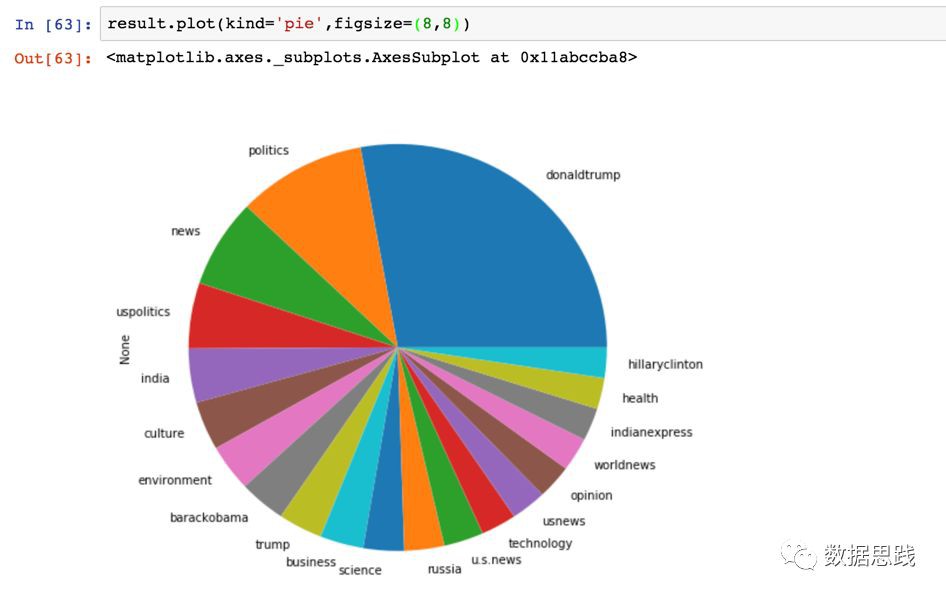
讓我們展開這個餅狀圖以便更好地進行比較。它看起來很酷!
1labels = keyword_count = 'donaldtrump ','politics','news','uspolitics','india','culture','environment','barackobama','russia','u.s.news'
2sizes =[1723,549,388,288,236,213,205,199,170,169]
3explode =(0.2,0.2,0.2,0.2,0.2,0.2,0.2,0.2,0.3,0.3)
4fig1, ax1 = plt.subplots()
5ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
6 shadow=True, startangle=90)
7ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
8
9plt.show()
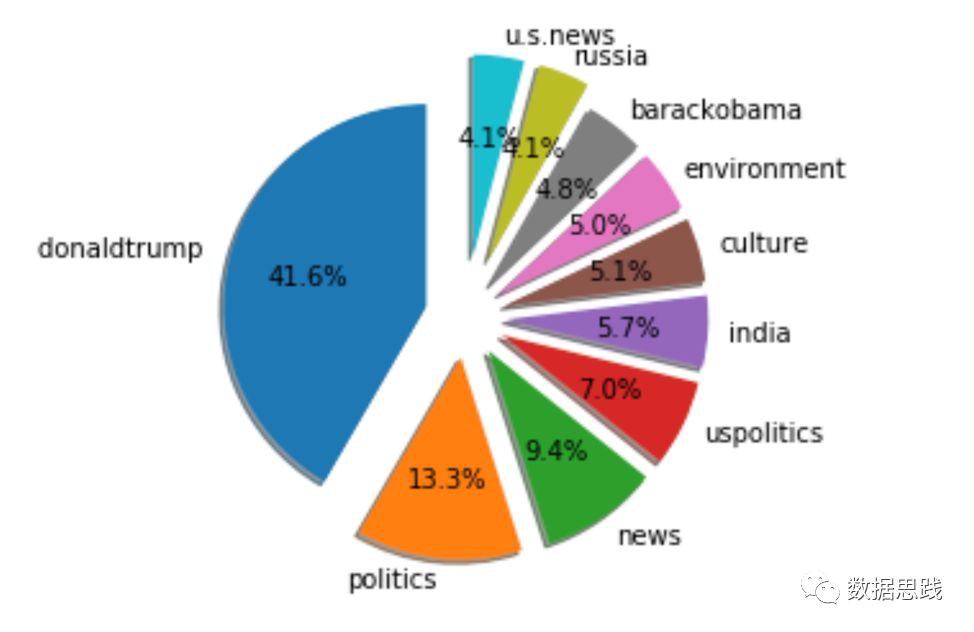
為了繪製這個餅狀圖,我們需要新增一些特徵。標簽是我們獲得的前10個關鍵詞;size是每個關鍵字的總數;Explode以不同的程度分割每個標簽——數字越大,差距就越大;startangle =90是我們自定義的起始角,這意味著所有東西都是逆時針旋轉90度。
希望您喜歡本教程。評論?建議嗎?請留言。
上善若水。水善利萬物而不爭,處眾人之所惡, 故幾於道。居,善地;心,善淵;與,善仁;言,善信;正,善治;事,善能;動,善時。夫唯不爭,故無尤。——老子《道德經》第八章
