
1. 背景
上一篇文章“淺析GPU通訊技術:GPUDirect P2P”中我們提到透過GPUDirect P2P技術可以大大提升GPU伺服器單機的GPU通訊效能,但是受限於PCI Expresss匯流排協議以及拓撲結構的一些限制,無法做到更高的頻寬,為瞭解決這個問題,NVIDIA提出了NVLink匯流排協議。
本篇文章我們就來談談NVIDIA提出的NVLink匯流排協議,看看它到底是何方神聖。
2. NVlink介紹
2.1 釋出
NVLink技術是在2014年3月的NVIDIA GTC 2014上釋出的。對普通消費者來說,這一屆的GTC似乎沒有太多的亮點,也沒有什麼革命性的產品釋出。這次GTC上,黃仁勛展示了新一代單卡雙芯卡皇GeForce Titan Z,下一代GPU架構Pascal也只是初露崢嶸。在黃仁勛演講中只用大約五六頁PPT介紹的NVLink也很容易被普通消費者忽視,但是有心的專業人士確從此舉看到了NVIDIA背後巨大的野心。
首先我們簡單看下NVIDIA對NVLink的介紹:NVLink能在多GPU之間和GPU與CPU之間實現非凡的連線頻寬。頻寬有多大?2016釋出的P100是搭載NVLink的第一款產品,單個GPU具有160GB/s的頻寬,相當於PCIe Gen3 * 16頻寬的5倍。去年GTC 2017上釋出的V100搭載的NVLink 2.0更是將GPU頻寬提升到了300G/s,差不多是PCIe的10倍了。
好了,這下明白了為什麼NVIDIA的NVLink會如此的引人註意了。但是NVLink背後的佈局遠不只是如此。
2.2 解讀
我們來看看NVLink出現之前的現狀:
1)PCIe:
PCIe Gen3每個通道(每個Lane)的雙向頻寬是2B/s,GPU一般是16個Lane的PCIe連線,所以PCIe連線的GPU通訊雙向頻寬可以達到32GB/s,要知道PCIe匯流排堪稱PC系統中第二快的裝置間匯流排(排名第一的是記憶體匯流排)。但是在NVLink 300GB/s的頻寬面前,只有被碾壓的份兒。
2)視訊記憶體頻寬:
上一代卡皇Geforce Titan XP的GDDR5X視訊記憶體頻寬已經達到547.7 GB/s,搭載HBM2視訊記憶體的V100的頻寬甚至達到了900GB/s。顯示卡核心和視訊記憶體之間的資料交換通道已經達到如此高的頻寬,但是GPU之間以及GPU和CPU之間的資料交換確受到PCIe匯流排的影響,成為了瓶頸。這當然不是NVIDIA希望看到的,而NVLink的出現,則是NVIDIA想打破這個瓶頸的宣言。
3)CPU連線:
實際上,NVLink不但可以實現GPU之間以及GPU和CPU之間的互聯,還可以實現CPU之間的互聯。從這一點來看,NVLink的野心著實不小。
我們知道,Intel的CPU間互聯匯流排是QPI,20位寬的QPI連線頻寬也只有25.6GB/s,在NVLink面前同樣差距巨大。可想而知,如果全部採用NVLink匯流排互聯,會對系統資料交換通道的頻寬有多大提升。
當然,NVIDIA自己並沒有CPU,X86仍然是當今CPU的主流架構,被Intel把持方向和趨勢,NVLink絕沒有可能進入X86 CPU連線匯流排的陣營。於是便有了NVIDIA和IBM組成的OpenPower聯盟。
NVIDIA是受制於沒有CPU,而IBM則恰好相反,IBM有自己的CPU,Power 處理器的效能驚艷,但IBM缺少相應的平行計算晶片,因此僅僅依靠自己的CPU,很難在目前的異構計算中發揮出優秀的效能、規模和效能功耗比優勢。從這一點來看,IBM和NVIDIA互補性就非常強了,這也是IBM為什麼要和NVIDIA組建OpenPower超級計算聯盟的原因了。
考慮到目前POWER生態的逐漸萎縮,要想在人工智慧浪潮下趁機搶佔X86的市場並不是件容易的事情,但至少給了NVIDIA全面抗衡Intel的平臺。
所以有點扯遠了,NVLink目前更主要的還是大大提升了GPU間通訊的頻寬。
2.3 結構和拓撲
2.3.1 NVLink訊號與協議
NVLink控制器由3層組成,即物理層(PHY)、資料鏈路層(DL)以及交易層(TL)。下圖展示了P100 NVLink 1.0的各層和鏈路:
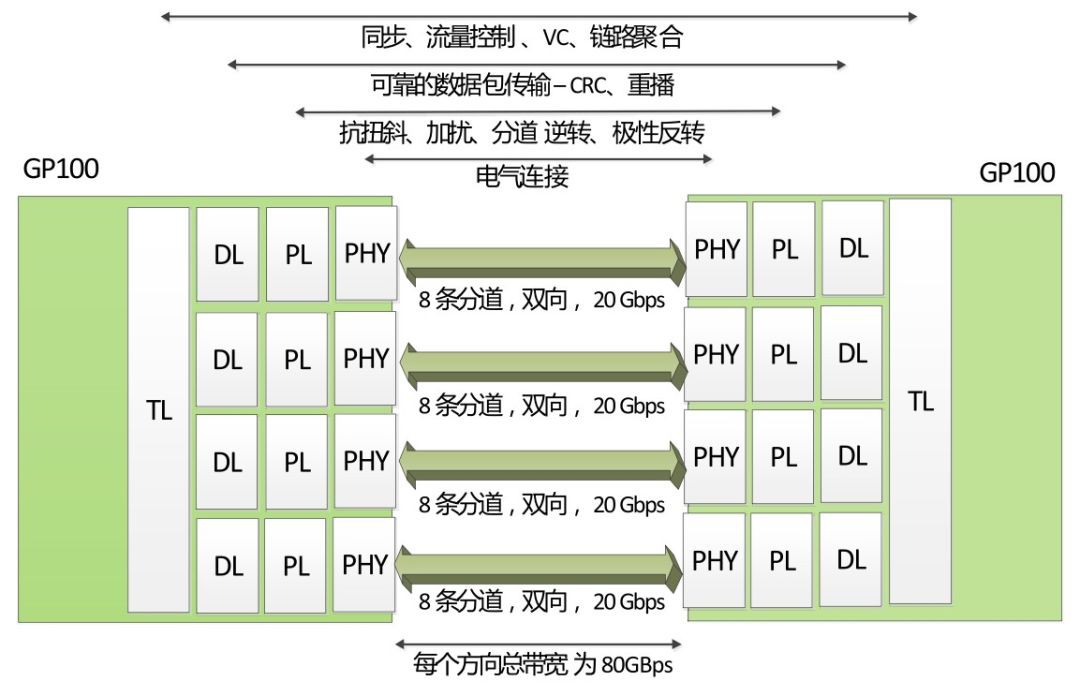
P100搭載的NVLink 1.0,每個P100有4個NVLink通道,每個擁有40GB/s的雙向頻寬,每個P100可以最大達到160GB/s頻寬。
V100搭載的NVLink 2.0,每個V100增加了50%的NVLink通道達到6個,訊號速度提升28%使得每個通道達到50G的雙向頻寬,因而每個V100可以最大達到300GB/s的頻寬。
2.3.2 拓撲
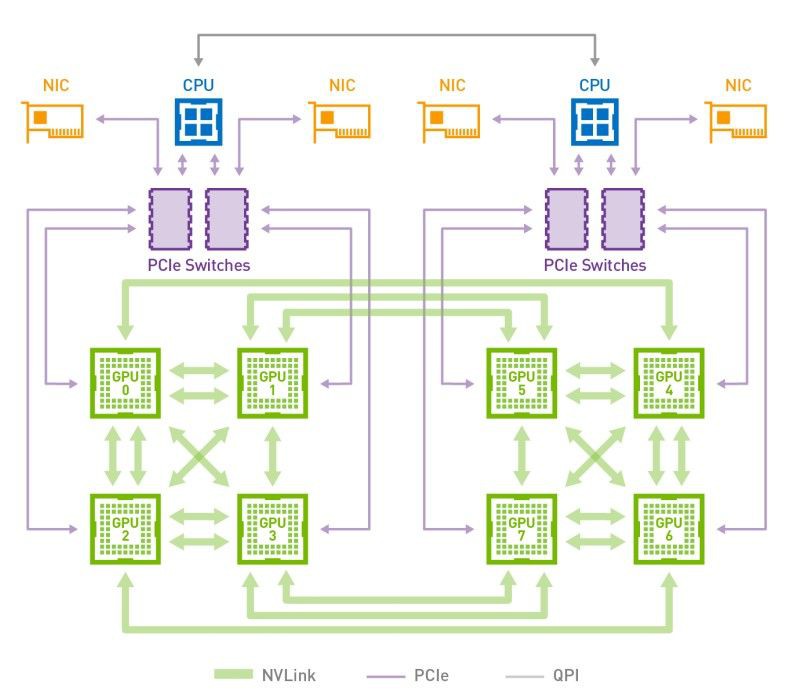
下圖是HGX-1/DGX-1使用的8個V100的混合立方網格拓撲結構,我們看到雖然V100有6個NVlink通道,但是實際上因為無法做到全連線,2個GPU間最多隻能有2個NVLink通道100G/s的雙向頻寬。而GPU與CPU間通訊仍然使用PCIe匯流排。CPU間通訊使用QPI匯流排。這個拓撲雖然有一定侷限性,但依然大幅提升了同一CPU Node和跨CPU Node的GPU間通訊頻寬。
2.3.3 NVSwitch
為瞭解決混合立方網格拓撲結構的問題,NVIDIA在今年GTC 2018上釋出了NVSwitch。
類似於PCIe使用PCIe Switch用於拓撲的擴充套件,NVIDIA使用NVSwitch實現了NVLink的全連線。NVSwitch作為首款節點交換架構,可支援單個伺服器節點中 16 個全互聯的 GPU,並可使全部 8 個 GPU 對分別以 300 GB/s 的驚人速度進行同時通訊。這 16 個全互聯的 GPU (32G視訊記憶體V100)還可作為單個大型加速器,擁有 0.5 TB 統一視訊記憶體空間和 2 PetaFLOPS 計算效能。
關於NVSwitch的相關技術細節可以參考NVIDIA官方技術檔案。應該說這一技術的引入,使得GPU間通訊的頻寬又大大上了一個臺階。
3. 效能
NVIDIA NVLink 將採用相同配置的伺服器效能提高 31%。
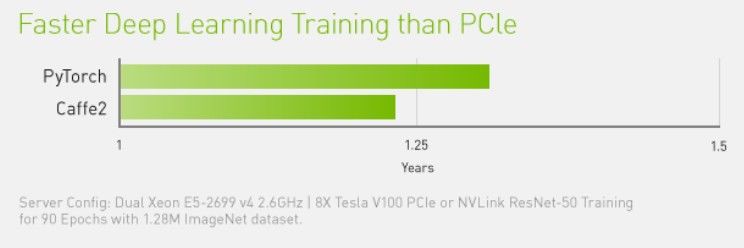
使用NVSwitch的DGX-2則能夠達到2倍以上的深度學習和高效能運算的加速。

