作為一個三國迷,我就有了這樣的想法:能不能用文字處理的方法,得到《三國演義》中的人物社交網路,再進行分析呢?python中有很多好工具能夠幫助我實踐我好奇的想法,現在就開始動手吧。
作者:blmoistawinde
來源:資料森麟(ID:shujusenlin)
01 準備工作
獲得《三國演義》的文字。
chapters = get_sanguo() # 文字串列,每個元素為一章的文字
print(chapters[0][:106])
第一回 宴桃園豪傑三結義 斬黃巾英雄首立功
滾滾長江東逝水,浪花淘盡英雄。是非成敗轉頭空。
青山依舊在,幾度夕陽紅。
白髮漁樵江渚上,慣看秋月春風。一壺濁酒喜相逢。
古今多少事,都付笑談中
《三國演義》並不是很容易處理的文字,它接近古文,我們會面對古人的字號等一系列別名。比如電腦怎麼知道“玄德”指的就是“劉備”呢?那就要我們給它一些知識。我們人透過學習知道“玄德”是劉備的字,電腦也可以用類似的方法完成這個概念的連線。
我們需要告訴電腦,“劉備”是物體(類似於一個物件的標準名),而“玄德”則是“劉備”的一個指稱,告訴的方式,就是提供電腦一個知識庫。
entity_mention_dict, entity_type_dict = get_sanguo_entity_dict()
print("劉備的指稱有:",entity_mention_dict["劉備"])
劉備的指稱有: ['劉備', '劉玄德', '玄德', '使君']
除了人的物體和指稱以外,我們也能夠包括三國勢力等別的型別的指稱,比如“蜀”又可以叫“蜀漢”,所以知識庫裡還可以包括物體的型別資訊來加以區分。
print("劉備的型別為",entity_type_dict["劉備"])
print("蜀的型別為",entity_type_dict["蜀"])
print("蜀的指稱有",entity_mention_dict["蜀"])
劉備的型別為 人名
蜀的型別為 勢力
蜀的指稱有 ['蜀', '蜀漢']
有了這些知識,理論上我們就可以程式設計聯絡起物體的各個綽號啦。不過若是要從頭做起的話,其中還會有不少的工作量。而HarvestText[1]是一個封裝了這些步驟的文字處理庫,可以幫助我們輕鬆完成這個任務。
ht = HarvestText()
ht.add_entities(entity_mention_dict, entity_type_dict) # 載入模型
print(ht.seg("誓畢,拜玄德為兄,關羽次之,張飛為弟。",standard_name=True))
['誓畢', ',', '拜', '劉備', '為兄', ',', '關羽', '次之', ',', '張飛', '為弟', '。']
02 社交網路建立
成功地把指稱統一到標準的物體名以後,我們就可以著手挖掘三國的社交網路了。具體的建立方式是利用鄰近共現關係。每當一對物體在兩句話內同時出現,就給它們加一條邊。那麼建立網路的整個流程就如同下圖所示:
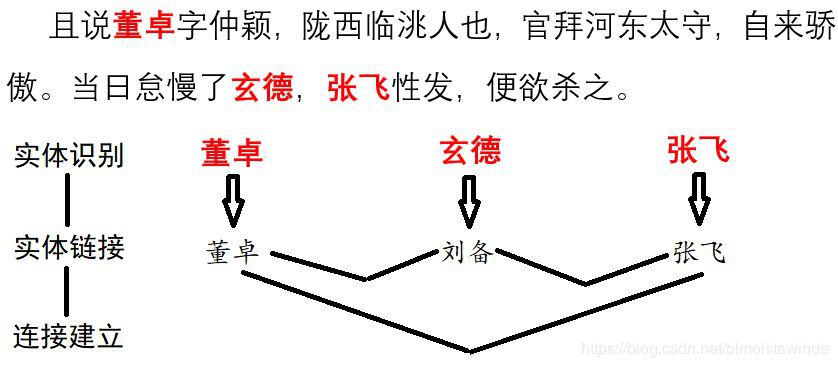
我們可以使用HarvestText提供的函式直接完成這個流程,讓我們先在第一章的小文字上實踐一下:
# 準備工作
doc = chapters[0].replace("操","曹操") # 由於有時使用縮寫,這裡做一個微調
ch1_sentences = ht.cut_sentences(doc) # 分句
doc_ch01 = [ch1_sentences[i]+ch1_sentences[i+1] for i in range(len(ch1_sentences)-1)] #獲得所有的二連句
ht.set_linking_strategy("freq")
# 建立網路
G = ht.build_entity_graph(doc_ch01, used_types=["人名"]) # 對所有人物建立網路,即社交網路
# 挑選主要人物畫圖
important_nodes = [node for node in G.nodes if G.degree[node]>=5]
G_sub = G.subgraph(important_nodes).copy()
draw_graph(G_sub,alpha=0.5,node_scale=30,figsize=(6,4))
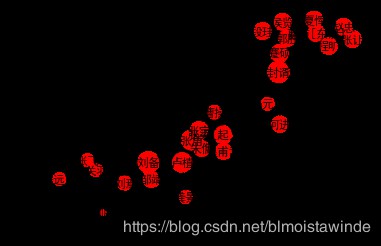
他們之間具體有什麼關係呢?我們可以利用文字摘要得到本章的具體內容:
stopwords = get_baidu_stopwords() #過濾停用詞以提高質量
for i,doc in enumerate(ht.get_summary(doc_ch01, topK=3, stopwords=stopwords)):
print(i,doc)
玄德見皇甫嵩、朱儁,具道盧植之意。嵩曰:“張梁、張寶勢窮力乏,必投廣宗去依張角。
時張角賊眾十五萬,植兵五萬,相拒於廣宗,未見勝負。植謂玄德曰:“我今圍賊在此,賊弟張梁、張寶在潁川,與皇甫嵩、朱儁對壘。
次日,於桃園中,備下烏牛白馬祭禮等項,三人焚香再拜而說誓曰:“念劉備、關羽、張飛,雖然異姓,既結為兄弟,則同心協力,
本章的主要內容,看來就是劉關張桃園三結義,並且共抗黃巾賊的故事。
03 三國全網路繪製
有了小範圍實踐的基礎,我們就可以用同樣的方法,整合每個章節的內容,畫出一張橫跨三國各代的大圖。
G_chapters = []
for chapter in chapters:
sentences = ht.cut_sentences(chapter) # 分句
docs = [sentences[i]+sentences[i+1] for i in range(len(sentences)-1)]
G_chapters.append(ht.build_entity_graph(docs, used_types=["人名"]))
# 合併各張子圖
G_global = nx.Graph()
for G0 in G_chapters:
for (u,v) in G0.edges:
if G_global.has_edge(u,v):
G_global[u][v]["weight"] += G0[u][v]["weight"]
else:
G_global.add_edge(u,v,weight=G0[u][v]["weight"])
# 忽略遊離的小分支只取最大連通分量
largest_comp = max(nx.connected_components(G_global), key=len)
G_global = G_global.subgraph(largest_comp).copy()
print(nx.info(G_global))
Name:
Type: Graph
Number of nodes: 1290
Number of edges: 10096
Average degree: 15.6527
整個社交網路有1290個人那麼多,還有上萬條邊!那麼我們要把它畫出來幾乎是不可能的,那麼我們就挑選其中的關鍵人物來畫出一個子集吧。
important_nodes = [node for node in G_global.nodes if G_global.degree[node]>=30]
G_main = G_global.subgraph(important_nodes).copy()
用pyecharts進行視覺化
from pyecharts import Graph
nodes = [{"name": "結點1", "value":0, "symbolSize": 10} for i in range(G_main.number_of_nodes())]
for i,name0 in enumerate(G_main.nodes):
nodes[i]["name"] = name0
nodes[i]["value"] = G_main.degree[name0]
nodes[i]["symbolSize"] = G_main.degree[name0] / 10.0
links = [{"source": "", "target": ""} for i in range(G_main.number_of_edges())]
for i,(u,v) in enumerate(G_main.edges):
links[i]["source"] = u
links[i]["target"] = v
links[i]["value"] = G_main[u][v]["weight"]
graph = Graph("三國人物關係力導引圖")
graph.add("", nodes, links)
graph.render("./images/三國人物關係力導引圖.html")
graph
部落格上不能顯示互動式圖表,這裡就給出截圖:顯示了劉備的鄰接結點
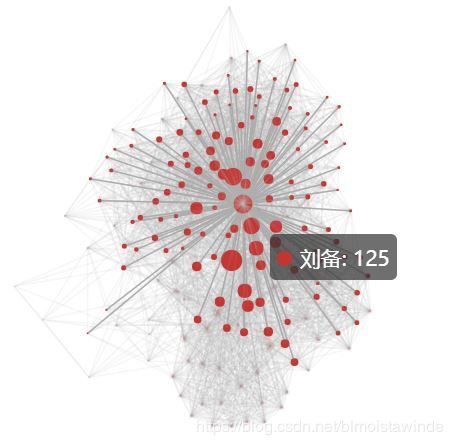
整個網路錯綜複雜,背後是三國故事中無數的南征北伐、爾虞我詐。不過有了計算機的強大算力,我們依然可以從中梳理出某些關鍵線索,比如:
04 人物排名-重要性
對這個問題,我們可以用網路中的排序演演算法解決。PageRank就是這樣的一個典型方法,它本來是搜尋引擎利用網站之間的聯絡對搜尋結果進行排序的方法,不過對人物之間的聯絡也是同理。讓我們獲得最重要的20大人物:
page_ranks = pd.Series(nx.algorithms.pagerank(G_global)).sort_values()
page_ranks.tail(20).plot(kind="barh")
plt.show()
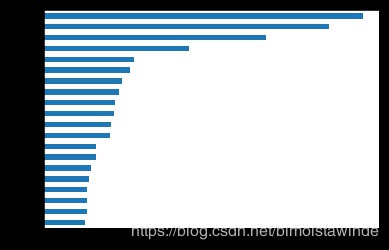
《三國演義》當仁不讓的主角就是他們了,哪怕你對三國不熟悉,也一定會對這些人物耳熟能詳。
05 人物排名-權力值
這個問題看上去跟上面一個問題很像,但其實還是有區別的。就像人緣最好的人未必是領導一樣,能在團隊中心起到凝聚作用,使各個成員相互聯絡合作的人才是最有權力的人。中心度就是這樣的一個指標,看看三國中最有權力的人是哪些吧?
between = pd.Series(nx.betweenness_centrality(G_global)).sort_values()
between.tail(20).plot(kind="barh")
plt.show()
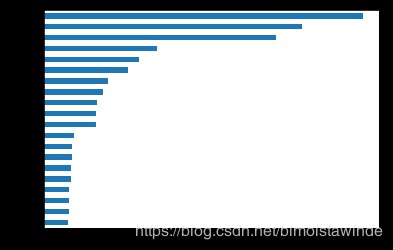
結果的確和上面的排序有所不同,我們看到劉備、曹操、孫權、袁紹等主公都名列前茅。而另一個有趣的發現是,司馬懿、司馬昭、司馬師父子三人同樣榜上有名,而曹氏的其他後裔則不見其名,可見司馬氏之權傾朝野。司馬氏之心,似乎就這樣被大資料揭示了出來!
06 社群發現
人物關係有親疏遠近,因此往往會形成一些集團。社交網路分析裡的社群發現演演算法就能夠讓我們發現這些集團,讓我使用community庫[2]中的提供的演演算法來揭示這些關係吧。
import community # python-louvain
partition = community.best_partition(G_main) # Louvain演演算法劃分社群
comm_dict = defaultdict(list)
for person in partition:
comm_dict[partition[person]].append(person)
在下麵3個社群裡,我們看到的主要是魏蜀吳三國重臣們。(只有一些小“問題”,有趣的是,電腦並不知道他們的所屬勢力,只是使用演演算法。)
draw_community(2)
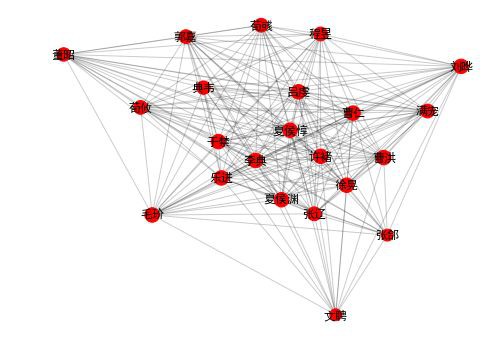
community 2: 張遼 曹仁 夏侯惇 徐晃 曹洪 夏侯淵 張郃 許褚 樂進 李典 於禁
荀彧 劉曄 郭嘉 滿寵 程昱 荀攸 呂虔 典韋 文聘 董昭 毛玠
draw_community(4)
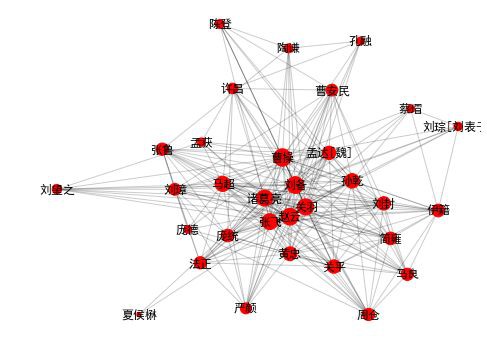
community 4: 曹操 諸葛亮 劉備 關羽 趙雲 張飛 馬超 黃忠 許昌 孟達[魏] 孫乾
曹安民 劉璋 關平 龐德 法正 伊籍 張魯 劉封 龐統 孟獲 嚴顏 馬良 簡雍 蔡瑁
陶謙 孔融 劉琮[劉表子] 劉望之 夏侯楙 周倉 陳登
draw_community(3)
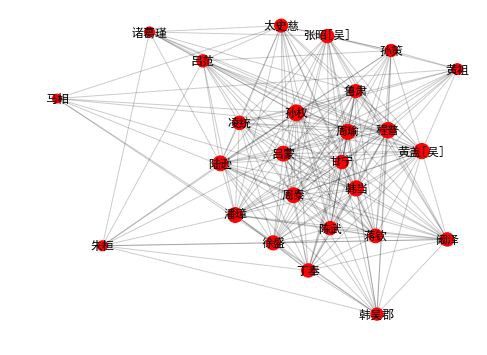
community 3: 孫權 孫策 周瑜 陸遜 呂蒙 丁奉 周泰 程普 韓當 徐盛 張昭[吳] 馬相 黃蓋[吳] 潘璋 甘寧 魯肅 凌統 太史慈 諸葛瑾 韓吳郡 蔣欽 黃祖 闞澤 朱桓 陳武 呂範
draw_community(0)
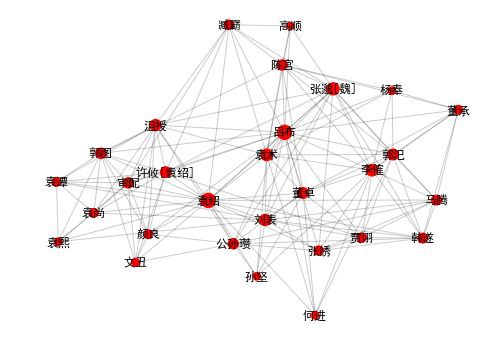
community 0: 袁紹 呂布 劉表 袁術 董卓 李傕 賈詡 審配 孫堅 郭汜 陳宮 馬騰
袁尚 韓遂 公孫瓚 高順 許攸[袁紹] 臧霸 沮授 郭圖 顏良 楊奉 張繡 袁譚 董承
文醜 何進 張邈[魏] 袁熙
還有一些其他社群。比如在這裡,我們看到三國前期,孫堅、袁紹、董卓等主公們群雄逐鹿,好不熱鬧。
draw_community(1)
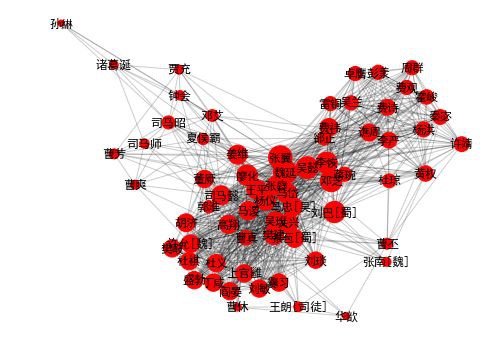
community 1: 司馬懿 魏延 薑維 張翼 馬岱 廖化 吳懿 司馬昭 關興 吳班 王平
鄧芝 鄧艾 張苞[蜀] 馬忠[吳] 費禕 譙周 馬謖 曹真 曹丕 李恢 黃權 鐘會 蔣琬
司馬師 劉巴[蜀] 張嶷 楊洪 許靖 費詩 李嚴 郭淮 曹休 樊建 秦宓 夏侯霸 楊儀
高翔 張南[魏] 華歆 曹爽 郤正 許允[魏] 王朗[司徒] 董厥 杜瓊 霍峻 胡濟 賈充
彭羕 吳蘭 諸葛誕 雷銅 孫綝 卓膺 費觀 杜義 閻晏 盛勃 劉敏 劉琰 杜祺 上官雝
丁鹹 爨習 樊岐 曹芳 周群
這個社群是三國後期的主要人物了。這個網路背後的故事,是司馬氏兩代三人打敗薑維率領的蜀漢群雄,又掃除了曹魏內部的曹家勢力,終於登上權力的頂峰。
07 動態網路
研究社交網路隨時間的變化,是個很有意思的任務。而《三國演義》大致按照時間線敘述,且有著極長的時間跨度,順著故事線往下走,社交網路會發生什麼樣的變化呢?
這裡,我取10章的文字作為跨度,每5章記錄一次當前跨度中的社交網路,就相當於留下一張快照,把這些快照連線起來,我們就能夠看到一個社交網路變化的動畫。快照還是用networkx得到,而製作動畫,我們可以用moviepy。
江山代有才人出,讓我們看看在故事發展的各個階段,都是哪一群人活躍在舞臺中央呢?
import moviepy.editor as mpy
from moviepy.video.io.bindings import mplfig_to_npimage
width, step = 10,5
range0 = range(0,len(G_chapters)-width+1,step)
numFrame, fps = len(range0), 1
duration = numFrame/fps
pos_global = nx.spring_layout(G_main)
def make_frame_mpl(t):
i = step*int(t*fps)
G_part = nx.Graph()
for G0 in G_chapters[i:i+width]:
for (u,v) in G0.edges:
if G_part.has_edge(u,v):
G_part[u][v]["weight"] += G0[u][v]["weight"]
else:
G_part.add_edge(u,v,weight=G0[u][v]["weight"])
largest_comp = max(nx.connected_components(G_part), key=len)
used_nodes = set(largest_comp) & set(G_main.nodes)
G = G_part.subgraph(used_nodes)
fig = plt.figure(figsize=(12,8),dpi=100)
nx.draw_networkx_nodes(G,pos_global,node_size=[G.degree[x]*10 for x in G.nodes])
# nx.draw_networkx_edges(G,pos_global)
nx.draw_networkx_labels(G,pos_global)
plt.xlim([-1,1])
plt.ylim([-1,1])
plt.axis("off")
plt.title(f"第{i+1}到第{i+width+1}章的社交網路")
return mplfig_to_npimage(fig)
animation = mpy.VideoClip(make_frame_mpl, duration=duration)
animation.write_gif("./images/三國社交網路變化.gif", fps=fps)
美觀起見,動畫中省略了網路中的邊。

隨著時間的變化,曾經站在歷史舞臺中央的人們也漸漸地會漸漸離開,讓人不禁唏噓感嘆。正如《三國演義》開篇所言:
古今多少事,都付笑談中。
今日,小輩利用python做的一番笑談也就到此結束吧……
本文為簡潔起見省略了一些細節程式碼,公眾號後臺回覆三國,可以獲取本文程式碼地址。
註:
[1] harvesttext是本人的作品,已在Github上開源並可透過pip直接安裝,旨在幫助使用者更輕易地完成像本文這樣的文字資料分析。除了本文涉及的功能以外,還有情感分析、新詞發現等功能。大家覺得有用的話,不妨親身嘗試下,看看能不能在自己感興趣的文字上有更多有趣有用的發現呢?
[2]commutity庫的本名是python-louvain,使用了和Gephi內建相同的Louvain演演算法進行社群發現
[3]由於處理古文的困難性,本文中依然有一些比較明顯的錯誤,希望大家不要介意~
關於作者:blmoistawinde, 西南某高校學森一枚,喜歡有意思的資料挖掘分析。希望給世界帶來些清新空氣~個人部落格地址:
https://blog.csdn.net/blmoistawinde
