作者:Matthew Mayo 翻譯:張玲 校對:李潔
本文約2200字,建議閱讀10分鐘。
本文總結了四種機器學習主流定義,分別從學習的最佳化過程、計算力、相似性和演演算法,研究了先驅者們和著名研究員們對機器學習本質的理解。
這是一篇不是十分正式的文章,旨在探討機器學習的本質。毫無疑問,過去你已經讀過許多關於機器學習的深度或半深度的文章,並探索了它與眾多其他主題的關係。當討論這樣複雜的概念,最好從最初的一些共同參考資料開始。可問題是,對於機器學習這樣的主題,存在著無數這樣的參考資料。
所以我想,為什麼不深入研究下這些參考資料呢?

來源:https://imarticus.org/what-is-machine-learning-and-does-it-matter/
乾脆我們來探討一下機器學習的定義,將其視作是一個語意學的練習。
湯姆米切爾(Tom Mitchell)
第一個定義,是我個人最喜歡的,由著名的電腦科學家、機器學習研究員,卡內基梅隆大學的湯姆米切爾(Tom Mitchell)教授提出。
對於某類任務T和效能度量P,如果一個計算機程式在某些任務T上以P度量的效能隨著經驗E的增加而提高,那麼我們稱這個計算機程式是在從經驗E中學習[1]。
Mitchell的這個定義在機器學習領域中是眾所周知的,而且是經過時間驗證的,這句話首次出現在Mitchell 1977年出版的《Machine Learning》一書中。
這句話對我有很大的影響,多年來我多次提及它,在碩士論文中也取用了它。此外,Goodfellow、Bengio 和 Courville最新出版的權威著作《Deep Learning》中,這段引文在其第5章中格外顯眼,因為他們將其作為該書解釋學習演演算法的起點。
圖1是Mitchell定義正規化的說明。
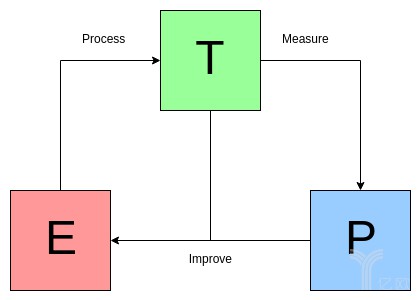
圖1:Mitchell 定義正規化
伊恩·古德費羅(Ian Goodfellow)、約舒亞·本吉奧(Yoshua Bengio)和亞倫·庫爾維爾(Aaron Courville)
提到伊恩·古德費羅(Ian Goodfellow)、約舒亞·本吉奧(Yoshua Bengio)和亞倫·庫爾維爾(Aaron Courville),就不得不提他們合著的《Deep Learning》,其中對機器學習的定義是這樣的:
機器學習本質上屬於應用統計學,更多地關註如何利用計算機對複雜函式進行統計估計,而不太關註如何估算這些函式的置信區間[2]。
在實際應用中,不再使用Mitchell對機器學習的定義,原因是它沒有規範性地給出如何實現最佳化的說明,只是側重於說明與機器學習最佳化過程相關的特定元件。相反,《Deep Learning》中對機器學習的定義實際上則更規範些。它指出,當不再強調傳統的置信區間時,應當最大化利用計算力(實際上強調了對計算力的利用)。
伊恩·威騰(Ian Witten)、埃貝·弗蘭克(Eibe Frank)和馬克·霍爾(Mark Hall)
在我看來,另一個特別值得關註的機器學習定義來自Witten, Frank & Hall 所著的《Data Mining: Practical Machine Learning Tool and Techniques》,這是我完整地閱讀有關這個主題的第一本書。這本書很少涉及數學,但有很多實用性的解釋,所以一直以來都是我為機器學習領域新手推薦必讀書目的首選(可能有偏見)。
他們最開始探討機器學習定義的方式有些零散,試圖在機器學習和資料挖掘的背景下將學習、效能和知識的概念組合在一起。離題部分已被剔除,以下是值得關註的引文:
我們感興趣的是新情境下效能的提升或者是效能提升的潛力。
當以一種可以使自身在未來表現更好的方式改變自己的行為時,就是在學習。
學習意味著思考和標的,必須有標的地去學習。
經驗表明,在機器學習和資料挖掘的許多應用中,獲得清晰的知識結構,即結構化描述,以及在新實體預測中表現良好的能力,這兩者至少是同樣重要的。人們通常使用資料挖掘來獲取知識,而不僅僅是用來預測[3]。
“資料挖掘”這個術語是機器學習的補充術語的說法是不需要關註的。上述引文出自這本書的第3版,出版於2011年,當時資料挖掘比現在更有吸引力;刪掉資料挖掘的相關內容,本書仍然適用於機器學習本身。
不管怎樣,雖然Witten, Frank & Hall在序言中貶低了他們想要偏離哲學性的希望,他們實際上做了一項非常棒的工作,變得有一些哲學性。這本書提供了有一定幫助作用的摘錄,因為它為機器學習的定義提供了一個不同的角度:Mitchell專註於最佳化過程的特定元件,Goodfellow、Bengio和Courville傾向於更規範的定義,指出計算力的相對重要性,而這本書則嘗試關註“學習”的哪些方面在機器學習過程中是相似的和重要的。上述引文還提供了重要的一點,頗具哲學性和實用性,即在最後一段中指出,獲得知識和使用知識的能力都是機器學習的重點部分(見訓練和推理)。
克裡斯托弗·畢肖普(Christopher Bishop)
讓我們來看看最後一篇文章-學者Christopher Bishop的《樣式識別和機器學習》對機器學習的定義。值得註意的是,Bishop並沒有開門見山地定義這個術語,而是以演演算法為中心,間接地為機器學習提供了非常好的定義(在數字分類任務中討論到)。
機器學習演演算法的結果可以表示為一個函式 y (x),輸入新數字影象 x,產生向量 y,用同樣的方法編碼來作為標的向量。在訓練階段(即學習階段),根據訓練資料確定y (x)精確的形式。一旦訓練完模型,就可以用它來確認測試集中新數字影象的類別,正確分類新數字影象的能力被稱為泛化,這些新數字影象不同於訓練時的數字影象。在實際應用中,輸入向量的多樣性使得訓練資料只能包含所有可能輸入向量中的一小部分,因此泛化是樣式識別的核心標的[4]。
首先,當談論“樣式識別時”,我們討論的是有監督機器學習,而不是無監督學習或強化學習(或其他形式的機器學習)。第二,更重要的是,這是唯一一個闡述機器學習處理步驟的定義,無論這些步驟在這個示例中是否簡短。同樣有趣的是,隨後的內容以及Bishop書一半的篇幅簡述了許多額外的機器學習概念,並將它們很好地結合在一起。這本書提供了具有可讀性的概述而沒有陷入數學的泥潭中(大部分內容做到了這一點)。
所以,我們有四種定義機器學習的方法:
-
第一種是根據最佳化過程,抽象地定義機器學習;
-
第二種是更具規範性的定義,指出計算力在機器學習中的重要性;
-
第三種是關註“學習”哪些方面在機器學習過程中是相似的和重要的;
-
最後一種是從演演算法角度概述機器學習。
這些定義都沒有錯誤,但都不是完整的。
這不僅僅是語意學的任務,探討先驅者們和受人尊敬的學者們所認為的“機器學習”定義將有助於擴充套件我們自己對機器學習的定義。
參考資料:
[1] Machine Learning, Tom Mitchell, McGraw Hill, 1997.
http://www.cs.cmu.edu/afs/cs.cmu.edu/user/mitchell/ftp/mlbook.html
[2] Deep Learning, Ian Goodfellow, Yoshua Bengio & Aaron Courville, MIT Press, 2016.
https://www.deeplearningbook.org/
[3] Data Mining: Practical Machine Learning Tools and Techniques (3rd ed.), Ian Witten, Eibe Frank & Mark Hall, Morgan Kaufmann, 2011.
https://www.cs.waikato.ac.nz/ml/weka/book.html
[4] Pattern Recognition and Machine Learning, Christopher M. Bishop, Springer, 2006.
https://www.springer.com/gp/book/9780387310732
原文標題:
The Essence of Machine Learning
原文連結:
https://www.kdnuggets.com/2018/12/essence-machine-learning.html
譯者簡介:張玲,在崗資料分析師,計算機碩士畢業。從事資料工作,需要重塑自我的勇氣,也需要終生學習的毅力。但我依舊熱愛它的嚴謹,痴迷它的藝術。資料海洋一望無境,資料工作充滿挑戰。感謝資料派THU提供如此專業的平臺,希望在這裡能和最專業的你們共同進步! 轉自:資料派THU ;
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
