關於作者:劉環宇,浙江大學控制科學與工程自動化系碩士,曠視科技研究院演演算法研究員,全景分割演演算法 OANet 第一作者,研究方向包括全景分割、語意分割等;2018 COCO + Mapillary 全景分割比賽曠視 Detection 組冠軍團隊成員。
前言
在計算機視覺中,影象語意分割(Semantic Segmentation)的任務是預測每個畫素點的語意類別;實體分割(Instance Segmentation)的任務是預測每個實體物體包含的畫素區域。全景分割(Panoptic Segmentation)[1] 最先由 FAIR 與德國海德堡大學聯合提出,其任務是為影象中每個畫素點賦予類別 Label 和實體 ID ,生成全域性的、統一的分割影象。
ECCV 2018 最受矚目的 COCO + Mapillary 聯合挑戰賽也首次加入全景分割任務,是全景分割領域中最權威與具有挑戰性的國際比賽,代表著當前計算機視覺識別技術最前沿。
在全景分割比賽專案中,曠視研究院 Detection 組參與了COCO 比賽專案與 Mapillary 比賽專案,並以大幅領先第二名的成績實力奪魁,在全景分割指標 PQ 上取得了0.532的成績,超越了 human consistency ,另外,我們的工作 An End-to-End Network for Panoptic Segmentation 也發表於 CVPR 2019 上。
接下來我們將全面解讀全景分割任務,下麵這張思維導圖有助於大家整體把握全景分割任務特性:
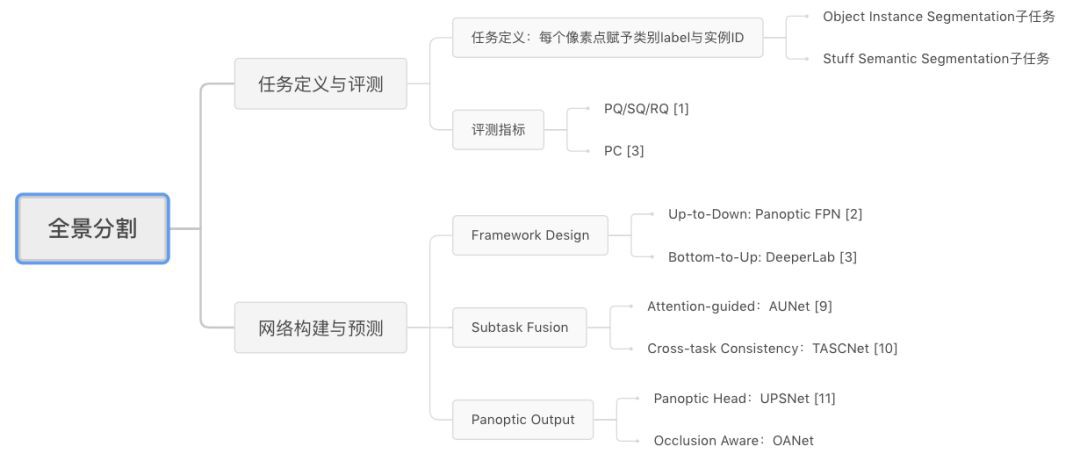
▲ 全景分割解讀思維導圖
首先,我們將分析全景分割任務的評價指標及基本特點,並介紹目前最新的研究進展;然後介紹我們發表於 CVPR 2019 的工作 Occlusion Aware Network (OANet),以及曠視研究院 Detection 組參與的 2018 COCO Panoptic Segmentation 比賽工作介紹;最後對全景分割當前研究進行總結與分析。
任務與前沿進展解讀
全景分割任務,從任務標的上可以分為 object instance segmentation 子任務與 stuff segmentation 子任務。全景分割方法通常包含三個獨立的部分:object instance segmentation 部分,stuff segmentation 部分,兩子分支結果融合部分。
通常 object instance segmentation 網路和 stuff segmentation 網路相互獨立,網路之間不會共享引數或者影象特徵,這種方式不僅會導致計算開銷較大,也迫使演演算法需要使用獨立的後處理程式融合兩支預測結果,並導致全景分割無法應用在工業中。
因此,可以從以下幾個角度分析與最佳化全景分割演演算法:
-
網路框架搭建;
-
子任務融合;
-
全景輸出預測。
這三個問題分別對應的是全景分割演演算法中的三個重要環節,下麵我們將分別分析這些問題存在的難點,以及近期相關工作提出的改進方法與解決方案。
全景分割評價指標
FAIR研究團隊 [1] 為全景分割定了新的評價標準 PQ (panoptic segmentation) 、SQ ( segmentation quality)、RQ (recognition quality) ,計算公式如下:

▲ PQ評價指標計算公式
其中,RQ 是檢測中應用廣泛的 F1 score,用來計算全景分割中每個實體物體識別的準確性,SQ 表示匹配後的預測 segment 與標註 segment 的 mIOU,如下圖所示,只有當預測 segment 與標註 segment 的 IOU 嚴格大於 0.5 時,認為兩個 segment 是匹配的。

▲ 全景分割預測結果與真實標註匹配圖解 [1]
從上面的公式能夠看到,在預測與標註匹配後的分割質量 SQ 計算時,評價指標 PQ 只關註每個實體的分割質量,而不考慮不同實體的大小,即大物體與小物體的分割結果對最終的 PQ 結果影響相同。
Yang et al. [6] 註意到在一些應用場景中更關註大物體的分割結果,如肖像分割中大圖的人像分割、自動駕駛中近距離的物體等,提出了 PC (Parsing Covering) 評價指標,計算公式如下:

▲ PC評價指標計算公式
其中, 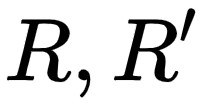 分別表示對應類別的預測 segments 與真實 segments,
分別表示對應類別的預測 segments 與真實 segments, 表示對應類別的實體在真實標註中畫素點數量,
表示對應類別的實體在真實標註中畫素點數量, 表示類別為 i 的真實標註畫素點總和。透過對大的實體物體賦予更大的權重,使評價指標能夠更明顯地反映大物體的分割指標。
表示類別為 i 的真實標註畫素點總和。透過對大的實體物體賦予更大的權重,使評價指標能夠更明顯地反映大物體的分割指標。
網路框架搭建
由於 object instance segmentation 子任務與 stuff segmentation 子任務分別屬於兩個不同的視覺預測任務,其輸入資料及資料增強方式、訓練最佳化策略與方法、網路結構與方法具有較大的不同,如何將兩個子任務融合併統一網路結構、訓練策略,是解決該問題的關鍵。
FAIR 研究團隊提出了一種簡潔有效的網路結構 Panoptic FPN [2],在網路框架層面將語意分割的全摺積網路(FCN)[3] 和實體分割網路 Mask RCNN [4] 統一起來,設計了單一網路同時預測兩個子任務,網路結構如下圖所示。
![]()
▲ Panoptic FPN網路框架圖
該網路結構能夠有效預測 object instance segmentation 子任務與 stuff segmentation 子任務。在 Mask RCNN 網路與 FPN [5] 的基礎上,作者設計了簡單而有效的 stuff segmentation 子分支:在 FPN 得到的不同層級的特徵圖基礎上,使用不同的網路引數得到相同大小的特徵圖,並對特徵圖進行加法合併,最後使用雙線性插值上取樣至原圖大小,併進行 stuff 類別預測。
MIT 與谷歌等聯合提出 DeeperLab [6] ,使用 bottom-to-up 的方法,同時實現 object instance segmentation 子任務與 stuff segmentation 子任務,其網路結構如下圖所示:

▲ DeeperLab網路結構圖
該網路包含了 encoder、decoder 與 prediction 三個環節,其中,encoder 和 decoder 部分對兩個子任務均是共享的,為了增強 encoder 階段的特徵,在 encoder 的末尾使用了ASPP (Atrous Spatial Pyramid Pooling) 模組 [7]。
而在 decoder 階段,首先使用 1×1 摺積對低層特徵圖與 encoder 輸出的特徵圖進行降維,並使用記憶體消耗較少的 space-to-depth [8, 9] 操作替代上取樣操作對低層特徵圖進行處理,從而將低層特徵圖(大小為原圖 1/4)與 encoder 輸出的特徵圖(大小為原圖 1/16 )拼接起來。
最後,使用兩層 7×7 的大卷積核增加感受野,然後透過 depth-to-space 操作降低特徵維度。
為了得到標的實體預測,作者採用類似 [10, 11, 12] 的使用基於關鍵點表示的方法,如下圖所示,在 object instance segmentation 子分支頭部,分別預測了 keypoint heatmap(圖a)、long-range offset map(圖b)、short-range offset map(圖c)、middle-range offset map(圖d)四種輸出,得到畫素點與每個實體關鍵點之間的關係,並依此融合形成類別不可知的不同實體,最後得到全景分割的結果。

▲ object instance segmentation子分支頭部預測標的
子任務融合
雖然透過特徵共享機制與網路結構設計,能夠將 object instance segmentation 子任務與 stuff segmentation 子任務統一起來,但是這兩個子分支之間的相互聯絡與影響並沒有得到充分的探究,例如:兩個子分支的任務是否能夠達到相互增益或者單向增益的效果?或者如何設計將兩個子分支的中間輸出或者預測關聯起來?這一部分問題我們可以統一將它稱作兩個子任務的相互提升與促進。
中科院自動化研究所提出了AUNet [13],文中設計了 PAM (Proposal Attention Module)與 MAM(Mask Attention Module)模組,分別基於 RPN 階段的特徵圖與 object instance segmentation 輸出的前景分割區域,為 stuff segmentation 提供了物體層級註意力與畫素層級註意力,其網路結構圖如下圖所示:

▲ AUNet網路結構圖
為了使 object instance segmentation 的預測輸出與 stuff segmentation 預測輸出保持一致性,豐田研究院設計了 TASCNet [14],其網路結構如下圖所示:

▲ TASCNet網路結構圖
網路首先將 object instance segmentation 子分支得到的實體前景掩膜區域,對映到原圖大小的特徵圖中,得到全圖尺寸下的實體前景掩膜區域,並與 stuff segmentation 預測的實體前景掩膜進行對比,使用 L2 損失函式最小化兩個掩膜的殘差。
全景輸出預測
Object instance segmentation 子分支與 stuff segmentation 子分支的預測結果在融合的過程中,一般透過啟髮式演演算法(heuristic algorithm)處理相衝突的畫素點,例如簡單地以 object instance segmentation 子分支的預測結果為準,並以 object instance segmentation 子分支的檢測框得分作為不同實體的合併依據。
這種方式依據簡單的先驗邏輯判斷,並不能較好地解決全景分割複雜的合併情況,因此,如何設計有效的模組解決 object instance segmentation 子分支與 stuff segmentation 子分支到全景分割輸出的融合過程,也是全景分割任務中的重要問題。
Uber 與港中文聯合提出了 UPSNet [15],其網路結構圖如下圖所示:

▲ UPSNet網路結構圖
將 object instance segmentation 子分支與 stuff segmentation 子分支的輸出透過對映變換,可得到全景頭部輸出的特徵張量,該張量大小為  ,其中,
,其中, 為動態變數,表示一張影象中實體的數量,
為動態變數,表示一張影象中實體的數量, 表示 stuff 類別個數,對於每張影象其數值是相同的,下文使用
表示 stuff 類別個數,對於每張影象其數值是相同的,下文使用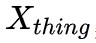 和
和 分別表示這兩種特徵張量。
分別表示這兩種特徵張量。
此外,網路對畫素進行了未知類別的預測(Unknown Prediction),從而使得網路能夠將部分畫素點判斷為未知類別併在測試的時候進行忽略,避免做出錯誤的類別導致 PQ 指標下降。
在得到 object instance segmentation 子分支與 stuff segmentation 子分支的輸出後,經過如下圖所示的變換,對映成和。

▲ panoptic segmentation head示意圖
可以直接從不規則類別分割的輸出中提取,中的第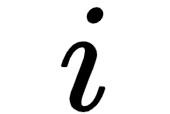 個實體的掩膜區域可由
個實體的掩膜區域可由 獲得,其中
獲得,其中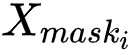 表示第
表示第 個實體對應的真實標註框與標註類別在 stuff segmentation 子分支輸出擷取的掩膜區域,表示第個實體對應的 instance segmentation 子分支得到的掩膜區域對映到原圖的掩膜區域,最後使用標準的逐畫素點的交叉熵損失函式對全景頭部輸出的張量進行監督訓練。
個實體對應的真實標註框與標註類別在 stuff segmentation 子分支輸出擷取的掩膜區域,表示第個實體對應的 instance segmentation 子分支得到的掩膜區域對映到原圖的掩膜區域,最後使用標準的逐畫素點的交叉熵損失函式對全景頭部輸出的張量進行監督訓練。
OANet專欄解讀


Motivation
在全景分割相關實驗中,我們發現,依據現有的啟髮式演演算法進行 object instance segmentation 子分支與 stuff segmentation 子分支的預測合併,會出現不同實體之間的遮擋現象。
為瞭解決不同實體之間的遮擋問題,我們提出了 Occlusion Aware Network (OANet),並設計了空間排序模組(Spatial Ranking Module),該模組能夠透過網路學習得到新的排序分數,併為全景分割的實體分割提供排序依據。
網路結構設計
我們提出的端到端的全景分割網路結構如下圖所示,該網路融合 object instance segmentation 子分支與 stuff segmentation 子分支的基礎網路特徵,在一個網路中同時實現全景分割的訓練與預測。
在訓練過程中,對於 stuff segmentation 我們同時進行了 object 類別與 stuff 類別的監督訓練,實驗表明這種設計有助於 stuff 的預測。
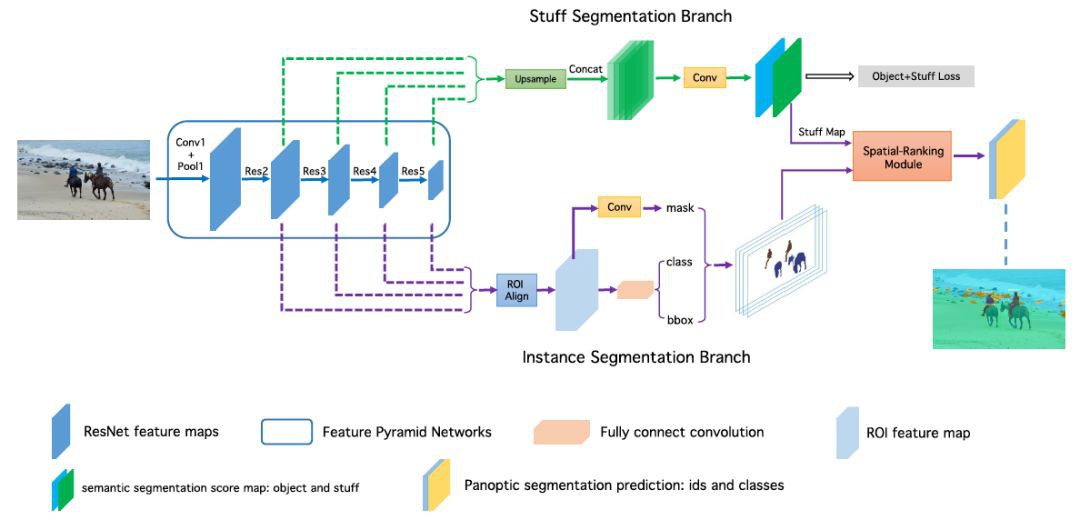
▲ OANet網路結構圖
採用一種類似語意分割的方法,我們提出一個簡單但非常有效的演演算法,稱作Spatial Ranking Module,能夠較好地處理遮擋問題,其網路結構如下所示:

▲ Spatial Ranking Module網路結構圖
我們首先將輸入的實體分割結果對映到原圖大小的張量之中,該張量的維度是實體物體類別的數量,不同類別的實體分割掩膜會對映到對應的通道上。張量中所有畫素點位置的初始化數值為零,實體分割掩膜對映到的位置其值設為 1。
在得到該張量後,使用大卷積核 [16] 進行特徵提取,得到空間排序得分圖;最後,我們計算出每個實體物件的空間排序得分,如下所示:

這裡, 表示類別為
表示類別為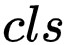 的、畫素點
的、畫素點 中的得分值,需要註意的是已被歸一化為機率,
中的得分值,需要註意的是已被歸一化為機率, 是掩膜畫素點指示符,表示畫素點是否屬於實體,每個實體的空間排序得分由預測的掩碼區域所有畫素點的排序分數平均得到,
是掩膜畫素點指示符,表示畫素點是否屬於實體,每個實體的空間排序得分由預測的掩碼區域所有畫素點的排序分數平均得到, 表示最終得到的每個實體的排序得分,並將此得分用於全景輸出。
表示最終得到的每個實體的排序得分,並將此得分用於全景輸出。
如下圖所示,若使用目前通用的啟髮式融合演演算法,即僅基於實體分割的檢測框的置信度作為遮擋處理依據。如圖所示,行人檢測框的置信度要明顯高於領帶檢測框的置信度,當兩個實體發生重疊時,領帶的實體會被行人實體遮擋;當加入空間排序得分模組後,我們透過該模組可以預測得到兩個實體的空間排序分數,依據空間排序分數得到的排序會更可靠,PQ 會有更大改善。

▲ 空間排序模組流程示意圖
實驗分析
我們對 stuff segmentation 分支的監督訊號進行了剝離實驗,如下表所示,實驗表明,同時進行 object 類別與 stuff 類別的監督訓練,能夠為 stuff segmentation 提供更多的背景關係資訊,並改進預測結果。

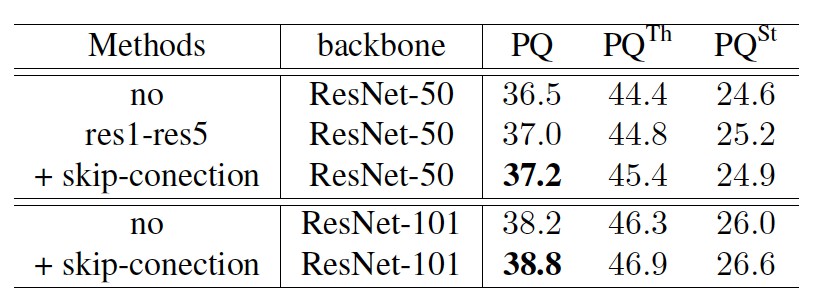
為了探究 object instance segmentation 子分支與 stuff segmentation 子分支的共享特徵方式,我們設計了不同的共享結構併進行實驗,如下表所示,實驗表明,共享基礎模型特徵與 FPN 結構的連線處特徵,能夠提高全景分割指標 PQ。
為了探究我們提出的 spatial ranking module 演演算法的有效性,我們在不同基礎模型下進行了實驗,如下表所示,其中,w/ spatial ranking module 表示使用我們提出的空間排序模組得到的結果,從實驗結果中可以看到,空間排序模組能夠在不同的基礎模型下大幅提高全景分割的評測結果。

為了測試不同摺積設定對學習處理遮擋的影響,進行瞭如下實驗,結果表明,提高摺積的感受也可以幫助網路學習獲得更多的背景關係特徵,並取得更好的結果。
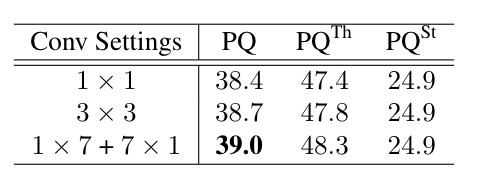
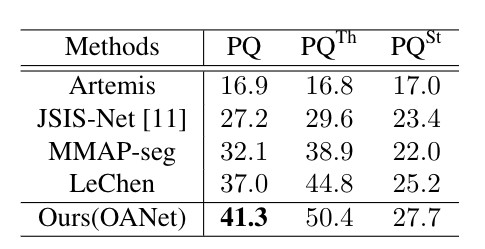
下表是本文提出的演演算法與現有公開指標的比較,從結果中可以看到,本文提出的演演算法能夠取得最優的結果。
2018 COCO全景分割比賽冠軍解讀
曠視研究院 Detection 組參與的全景分割 COCO 比賽專案與 Mapillary 比賽專案中,以大幅領先第二名的成績實力奪魁,在全景分割指標 PQ 上取得了 0.532 的成績,超越了 human consistency。

▲ COCO 2018 Panoptic Leaderboard

▲ 全景分割預測視覺化圖例
在比賽中,我們使用瞭如下圖所示的流程,首先分別預測 stuff semantic segmentation 與 object instance segmentation,然後透過後處理的操作得到全景分割的結果。

▲ 全景分割演演算法流程圖
在 stuff semantic segmentation 預測階段,首先我們對網路結構進行了部分調整以得到更好的分割效果。首先,網路最終的下取樣倍數設為 8 ,保證輸出結果的解析度;然後,由於網路的 encoder 不會擴大網路的感受野, 因此我們在標準 ResNet 之後使用了若干層 Res-Block。
另外,實驗發現 stuff 類別和 object 類別之間的背景關係對於 stuff 分割較為重要,因此我們在網路預測中融入了背景關係資訊,並透過多階段、多種監督的方式實現,網路結構如下圖所示:

▲ stuff semantic segmentation結構圖
對於 object instance segmentation,我們使用了與 Mask RCNN 相同的網路結構及訓練配置。最後,透過使用更大的網路基礎模型,multi scale + flip 的測試方法,以及多模型的ensemble操作,我們取得了最終的預測結果,如下圖所示:
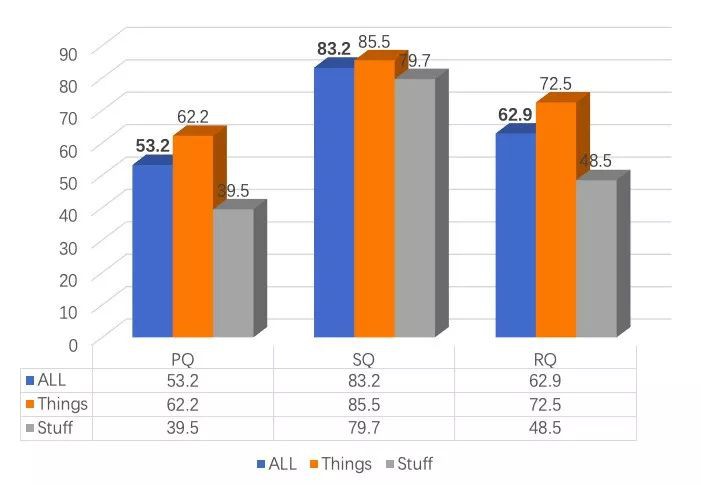
▲ Panoptic Results on COCO test-dev Dataset
總結與分析
從上文的文獻分析來看,全景分割任務的不同重要問題均得到了廣泛探究,但是全景分割任務依然是有挑戰性、前沿的場景理解問題,目前仍存在一些問題需要進行探究:
第一,由於全景分割可透過分別預測實體分割子任務與不規則類別分割子任務、兩個子任務預測結果融合得到,整個演演算法流程中包含較多的細節與後處理操作,包括 segments 的過濾、啟髮式融合演演算法、ignore 畫素點的判斷等。這些細節對全景分割指標有較大的影響,在一定程度上也阻礙了不同演演算法的對比與評測;
第二,全景分割評測指標雖然能夠較好地評測全景分割中實體物體檢測準確度,以及實體物體與不規則類別的分割準確度,但是該評測指標更側重每個實體,並沒有關註每個實體之間的區別。文獻 [6] 提出了對大物體有更好的評測指標 PC (Parsing Covering),使得大物體的分割效果對最終的評測指標影響更大,在一些關註大物體的任務如肖像分割、自動駕駛中更為有效;
第三,全景分割中子任務的融合問題,目前研究依然較多地將全景分割看做是 object instance segmentation 與 stuff segmentation 兩個子任務的合集,如何從全域性、統一的分割問題出發,針對性設計符合全景分割的統一網路,具有重要的意義。
加入我們
歡迎各位同學加入曠視科技 Face++ Detection Team,簡歷可以投遞給 Detection 組負責人俞剛 (yugang@megvii.com)。
參考文獻
[1] Kirillov A, He K, Girshick R, et al. Panoptic segmentation[J]. arXiv preprint arXiv:1801.00868, 2018.
[2] Kirillov A, Girshick R, He K, et al. Panoptic Feature Pyramid Networks[J]. arXiv preprint arXiv:1901.02446, 2019.
[3] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.
[4] He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2961-2969.
[5] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2117-2125.
[6] Yang T J, Collins M D, Zhu Y, et al. DeeperLab: Single-Shot Image Parser[J]. arXiv preprint arXiv:1902.05093, 2019.
[7] Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(4): 834-848.
[8] Shi W, Caballero J, Huszár F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 1874-1883.
[9] Sajjadi M S M, Vemulapalli R, Brown M. Frame-recurrent video super-resolution[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6626-6634.
[10] Papandreou G, Zhu T, Chen L C, et al. PersonLab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 269-286.
[11] Tychsen-Smith L, Petersson L. Denet: Scalable real-time object detection with directed sparse sampling[C] // Proceedings of the IEEE International Conference on Computer Vision. 2017: 428-436.
[12] Law H, Deng J. Cornernet: Detecting objects as paired keypoints [C] // Proceedings of the European Conference on Computer Vision (ECCV). 2018: 734-750.
[13] Li Y, Chen X, Zhu Z, et al. Attention-guided unified network for panoptic segmentation[J]. arXiv preprint arXiv:1812.03904, 2018.
[14] Li J, Raventos A, Bhargava A, et al. Learning to fuse things and stuff[J]. arXiv preprint arXiv:1812.01192, 2018.
[15] Xiong Y, Liao R, Zhao H, et al. UPSNet: A Unified Panoptic Segmentation Network[J]. arXiv preprint arXiv:1901.03784, 2019.
[16] Peng C, Zhang X, Yu G, et al. Large Kernel Matters–Improve Semantic Segmentation by Global Convolutional Network[C] // Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 4353-4361.
