有些人喜歡使用 HTTP REST APIs,但是他們可能會碰到自身的佇列問題;有些人則傾向使用諸如 RabbitMQ 之類舊的訊息佇列,然而他們不得不考慮擴容和運營等相關問題。
因此以 Kafka 為核心的架構應運而生,它旨在解決上述兩方面的問題。
在本文中,我們將和您討論 Apache Kafka 是如何改進過去在微服務中,所用到的 HTTP REST API 和訊息佇列架構,以及它是如何進一步擴充套件自己的服務能力。
兩大陣營的故事
第一大陣營是指:通訊被透過呼叫諸如 HTTP REST API、或遠端過程呼叫(Remote Procedure Calls,RPC)等其他服務的形式來直接處理。
第二大陣營則借用了面向服務的架構(Service-Oriented Architecture,SOA)的企業服務匯流排(Enterprise Service Bus)的概念,使用某個負責與其他服務進行通訊的訊息佇列(如 RabbitMQ),作為訊息代理來實現各種操作。
此法雖然能夠給通訊免去逐個服務直接進行“交流”的負載,但是在網路中增加了額外“一跳(hop)”的成本。
使用 HTTP REST APIs 的微服務
HTTP REST APIs 是一種在服務之間進行 RPC 的流行方式。它的主要好處在於簡化了初始化設定,並提升傳送訊息的相對效率。
然而,這種樣式需要其實現者考慮佇列之類的問題,以及如何應對傳入請求的數量超過該節點容量的問題。
例如:假設您有一個服務長鏈,其中的一個 preceding(先導)超過了節點的處理容量。
那麼我們就需要對該服務鏈中的所有 preceding 服務進行相同型別的背壓處理(back pressure handling,譯者註:系統自適應地降低源頭或者上游的傳送速率),以應對該問題。
此外,這種樣式要求所有的單個 HTTP REST API 服務都具備高可用性。而在那些由各種微服務所組成的長管道(pipeline)中,沒有一個微服務可以承受失去其所有元件的“損失”。
因此,只要在給定組中至少一個行程仍在正常執行,那麼這種通訊就仍然可以運作。
當然,我們通常需要在這些微服務的前端配置負載均衡模組。同時,由於不同的微服務需要知道哪裡能夠透過呼叫來實現通訊,因此服務發現(service discovery)模組也往往是必須的。
這種樣式的優點之一在於:延時非常低。由於在給定的請求路徑上,幾乎省去了中間人的角色,因此,諸如 Web 伺服器和負載平衡之類的元件,都經得起實戰的“檢驗”,並具有高效能。
可見,對於不同 RPC 型別的微服務而言,我們需要處理它們之間的普通依賴性,因此它們往往會很快變得相當複雜,並最終影響、甚至拖慢開發的行程。
如今,業界也推出了一些新的解決方案。例如 Envoy 代理,它使用的是服務網格(service mesh)來解決此類問題。
雖然該樣式解決了諸如負載均衡和服務發現等問題,但是相對於簡單且直接的 RPC 呼叫而言,我們系統的整體複雜程度還是增加了不少。
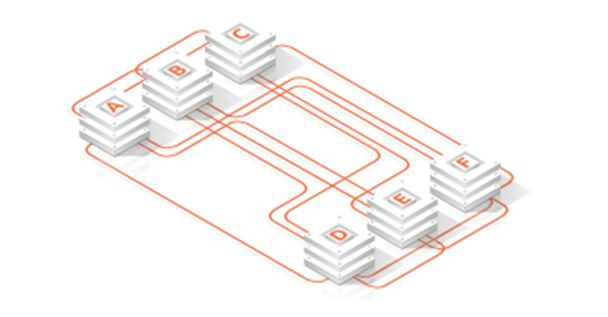
如下圖所示,許多公司起初可能只有幾個微服務需要相互通訊,而隨著其系統的逐漸“成長”,相互之間的呼叫關係和通訊渠道會最終變得像一碗義大利麵那些錯綜複雜。
訊息佇列
構建微服務之間通訊的另一種方式是:基於訊息匯流排或訊息佇列系統的使用。
以前那些舊的面向服務架構將這種方式稱為企業服務匯流排(ESB)。通常情況下,它們需要用 RabbitMQ 或 ActiveMQ 作為訊息代理(message brokers)。
訊息代理作為集中式的訊息服務,能夠方便所有與之相連的微服務進行彼此通訊。
同時,藉助訊息服務的排隊處理機制和高可用性,各個服務之間的通訊也能夠得以保障。
例如:有了訊息佇列的支援,各種訊息能夠被有序地接收到,以便系統進行後期處理。
而不會在出現請求峰值,且超過了處理容量的極限時,系統直接丟棄後續的佇列。
然而,許多訊息代理都已經明確地告知使用者:它們在叢集環境中,對於訊息的傳遞和永續性的處理能力缺少可擴充套件性,甚至有所限制。
對於訊息佇列而言,另一個值得專註的地方是:它們在錯誤發生時的處理方式。
例如:系統在訊息傳遞過程的可靠機制,是能夠至少保證一次呢?還是最多也只能保證有一次?
當然,其語意的選擇,則完全依賴於訊息佇列的實現。也就是說,您必須熟悉自己所選用的訊息傳遞、及其相配的語意規則。
此外,將訊息佇列新增到現有系統的架構中,勢必會增加有待操作和維護的新元件。
同時為了傳送各類訊息,而在網路中新增“一跳”,也將會給網站產生一些額外的延時與等待。
客觀地說,該樣式透過對各種訊息佇列系統,採用集中式的訪問控制串列(Access Control Lists,ACL),從而簡化了各類安全事項。
即:這種集中式管控方式統一地運用各種規則,限定了誰可以讀取和寫入什麼樣的訊息。
集中式通訊的另一個好處是:網路安全。例如:過去所有的微服務都採用的是彼此自行通訊的方式。
而採用訊息代理之後,您可以將所有的連線都經由訊息佇列服務來進行中轉,透過類似防火牆的規則設定,來濾除掉其他微服務之間的直接聯絡,進而減少了被攻擊面。
以 Kafka 為中心的優勢
由 LinkedIn 建立的 Apache Kafka 是一個開源的事件流平臺。與過去舊的訊息佇列系統截然不同的是:它具有將傳送者與接收者完全分離的能力。也就是說,傳送者並不需要知道誰將會去接收其傳送的訊息。
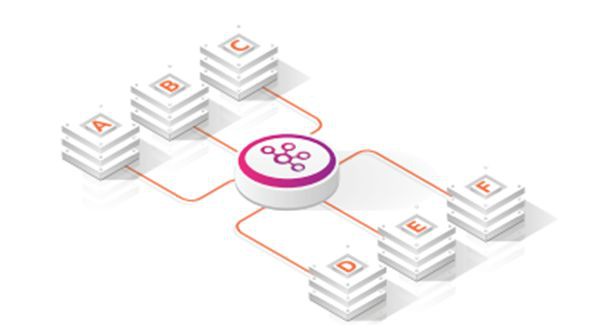
在其他許多訊息代理系統中,它們必須事先知道誰會去讀取所發的訊息。這多少阻礙了我們將一些新的未知用例新增到傳統的排隊系統之中。
而在使用 Apache Kafka 時,各種訊息被髮送者寫入一個被稱為 topic(主題)的日誌式資料流裡,他們完全沒有必要去關心誰、或那些應用將會真正地去讀取該訊息。
因此,這留給了新的用例去根據自己的新用途,考慮如何處置 Kafka 的相關 topic 內容的發揮空間。
對於 Kafka 而言,它不但不會去理會各種傳送訊息的具體載荷,還會讓訊息以任意方式進行序列化。
因此,大多數使用者還是會使用 JSON、AVRO、或 Protobufs 來實現其資料格式上的序列化。
另外,您也可以輕鬆地透過設定 ACL,來限制各種 producers(生產者)和 consumers(消費者)能夠對系統中的哪些 topic 進行讀取或寫入,以便您實現對所有訊息的集中式安全控制。
因此,您會經常看到 Kafka 被作為一種 firehose 式資料管道,用來接收潛在的超大量資料。
例如:Netflix 公司就聲稱,他們正在使用 Kafka 來處理每天二萬億條訊息的體量。
值得註意的是,Kafka 的 consumers 具有一個重要的特性:隨著訊息負載的增加,Kafka 的 consumers 會根據故障和容量需求的增多而發生變化,此時 Kafka 會自動地重新平衡各個 consumers 之間的處理負荷。
可見,開發者從需要保證微服務內部的高可用性,轉移到了 Apache Kafka 服務本身。
相應地,Kafka 這種能夠處理流資料(streaming data)的運營能力,也將其從一個訊息系統發展成為了一個流資料平臺。
而且可喜的是,Apache Kafka 的使用雖然給網路新增了額外的“一跳”,但是它作為各種請求的微服務通訊匯流排,卻沒有增加(或者說降低了)任何延時。
總之,上述提到的低延時、自動擴容、集中管理、以及成熟的高可用性,都讓 Apache Kafka 在微服務的通訊開發中能夠脫穎而出,為您可能用到的各種流資料實時分析創造了穩定的執行環境。
轉載自:51CTO技術棧
