緣起
前幾天看到了這個腦洞清奇的對聯AI,大家都玩瘋了一文,覺得挺有意思,難得的是作者還整理並公開了資料集,所以決定自己嘗試一下。
動手
“對對聯”,我們可以看成是一個句子生成任務,可以用 Seq2Seq 完成,跟我之前寫的玩轉Keras之Seq2Seq自動生成標題一樣,稍微修改一下輸入即可。上面提到的文章所用的方法也是 Seq2Seq,可見這算是標準做法了。
分析
然而,我們再細想一下就會發現,相對於一般的句子生成任務,“對對聯”有規律得多:1)上聯和下聯的字數一樣;2)上聯和下聯的每一個字幾乎都有對應關係。
如此一來,其實對對聯可以直接看成一個序列標註任務,跟分詞、命名物體識別等一樣的做法即可。這便是本文的出發點。
說到這,其實本文就沒有什麼技術含量了,序列標註已經是再普通不過的任務了,遠比一般的 Seq2Seq 來得簡單。
所謂序列標註,就是指輸入一個向量序列,然後輸出另外一個通常長度的向量序列,最後對這個序列的“每一幀”進行分類。相關概念來可以在簡明條件隨機場CRF介紹 | 附帶純Keras實現一文進一步瞭解。
模型
本文直接邊寫程式碼邊介紹模型。如果需要進一步瞭解背後的基礎知識的讀者,還可以參考《中文分詞系列:基於雙向LSTM的Seq2Seq字標註》[1]、《中文分詞系列:基於全摺積網路的中文分詞》[2]、《基於CNN和VAE的作詩機器人:隨機成詩》[3]。
我們所用的模型程式碼如下:
x_in = Input(shape=(None,))
x = x_in
x = Embedding(len(chars)+1, char_size)(x)
x = Dropout(0.25)(x)
x = gated_resnet(x)
x = gated_resnet(x)
x = gated_resnet(x)
x = gated_resnet(x)
x = gated_resnet(x)
x = gated_resnet(x)
x = Dense(len(chars)+1, activation='softmax')(x)
model = Model(x_in, x)
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam')
其中 gated_resnet 是我定義的門摺積模組:
def gated_resnet(x, ksize=3):
# 門摺積 + 殘差
x_dim = K.int_shape(x)[-1]
xo = Conv1D(x_dim*2, ksize, padding='same')(x)
return Lambda(lambda x: x[0] * K.sigmoid(x[1][..., :x_dim]) \
+ x[1][..., x_dim:] * K.sigmoid(-x[1][..., :x_dim]))([x, xo])
僅此而已,就這樣完了,剩下的都是資料預處理的事情了。當然,讀者也可以嘗試也可以把 gated_resnet 換成普通的層疊雙向 LSTM,但我實驗中發現層疊雙向 LSTM 並沒有層疊 gated_resnet 效果好,而且 LSTM 相對來說也很慢。
效果
訓練的資料集來自以下連結,感謝作者的整理。
https://github.com/wb14123/couplet-dataset
完整程式碼:
https://github.com/bojone/seq2seq/blob/master/couplet_by_seq_tagging.py
訓練過程:
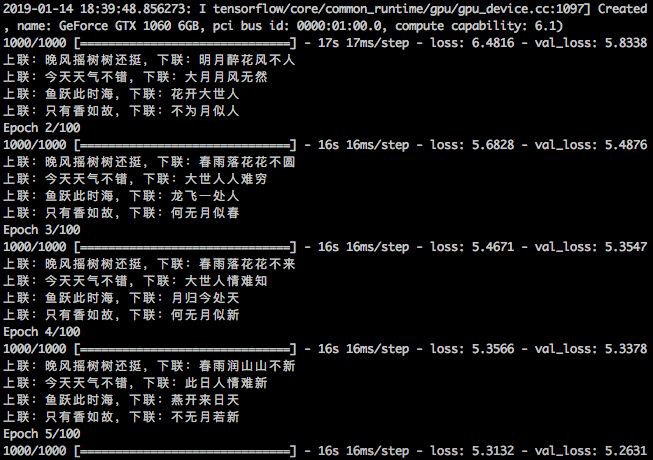
▲ 對聯機器人訓練過程
部分效果:

看起來還是有點味道的。註意“晚風搖樹樹還挺”是訓練集的上聯,標準下聯是“晨露潤花花更紅”,而模型給出來的是“夜雨敲花花更香”,說明模型並不是單純地記住訓練集的,還是有一定的理解能力;甚至我覺得模型對出來的下聯更生動一些。
總的來說,基本的字的對應似乎都能做到,就缺乏一個整體感。總體效果沒有下麵兩個好,但作為一個小玩具,應該能讓人滿意了。
王斌版AI對聯:https://ai.binwang.me/couplet/
微軟對聯:https://duilian.msra.cn/default.htm
結語
最後,也沒有什麼好總結的。我就是覺得這個對對聯應該算是一個序列標註任務,所以就想著用一個序列標註的模型來試試看,結果感覺還行。
當然,要做得更好,需要在模型上做些調整,還可以考慮引入 Attention 等,然後解碼的時候,還需要引入更多的先驗知識,保證結果符合我們對對聯的要求。這些就留給有興趣做下去的讀者繼續了。
相關連結
[1] https://kexue.fm/archives/3924
[2] https://kexue.fm/archives/4195
[3] https://kexue.fm/archives/5332