
作者丨尹相楠
學校丨里昂中央理工博士在讀
研究方向丨人臉識別、對抗生成網路


Self Attention GAN 用到了很多新的技術。最大的亮點當然是 self-attention 機制,該機制是 Non-local Neural Networks [1] 這篇文章提出的。其作用是能夠更好地學習到全域性特徵之間的依賴關係。因為傳統的 GAN 模型很容易學習到紋理特徵:如皮毛,天空,草地等,不容易學習到特定的結構和幾何特徵,例如狗有四條腿,既不能多也不能少。
除此之外,文章還用到了 Spectral Normalization for GANs [2] 提出的譜歸一化。譜歸一化的解釋見本人這篇文章:詳解GAN的譜歸一化(Spectral Normalization)。
但是,該文程式碼中的譜歸一化和原始的譜歸一化運用方式略有差別:
1. 原始的譜歸一化基於 W-GAN 的理論,只用在 Discriminator 中,用以約束 Discriminator 函式為 1-Lipschitz 連續。而在 Self-Attention GAN 中,Spectral Normalization 同時出現在了 Discriminator 和 Generator 中,用於使梯度更穩定。除了生成器和判別器的最後一層外,每個摺積/反摺積單元都會上一個 SpectralNorm。
2. 當把譜歸一化用在 Generator 上時,同時還保留了 BatchNorm。Discriminator 上則沒有 BatchNorm,只有 SpectralNorm。
3. 譜歸一化用在 Discriminator 上時最後一層不加 Spectral Norm。
最後,self-attention GAN 還用到了 cGANs With Projection Discriminator 提出的 conditional normalization 和 projection in the discriminator。這兩個技術我還沒有來得及看,而且 PyTorch 版本的 self-attention GAN 程式碼中也沒有實現,就先不管它們了。
本文主要說的是 self-attention 這部分內容。
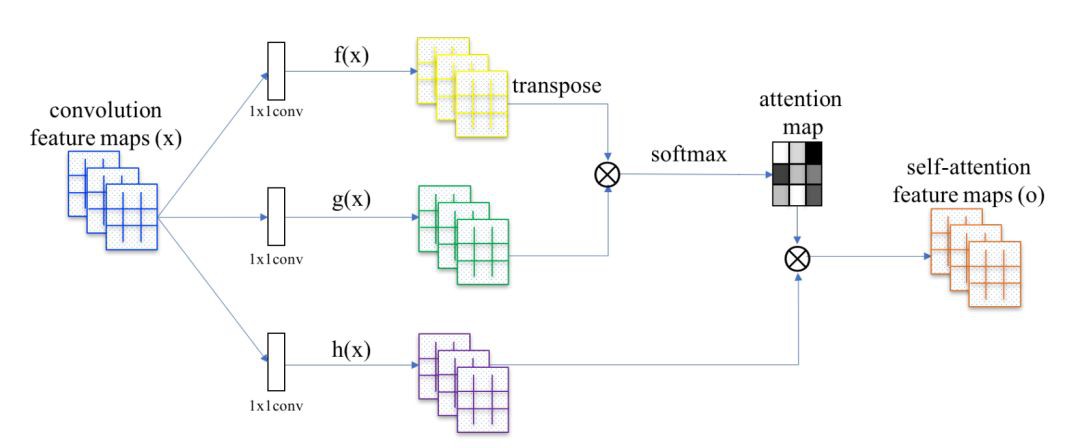
▲ 圖1. Self-Attention
Self-Attention
在摺積神經網路中,每個摺積核的尺寸都是很有限的(基本上不會大於 5),因此每次摺積操作只能改寫畫素點周圍很小一塊鄰域。
對於距離較遠的特徵,例如狗有四條腿這類特徵,就不容易捕獲到了(也不是完全捕獲不到,因為多層的摺積、池化操作會把 feature map 的高和寬變得越來越小,越靠後的層,其摺積核改寫的區域映射回原圖對應的面積越大。但總而言之,畢竟還得需要經過多層對映,不夠直接)。
Self-Attention 透過直接計算影象中任意兩個畫素點之間的關係,一步到位地獲取影象的全域性幾何特徵。
論文中的公式不夠直觀,我們直接看文章的 PyTorch 的程式碼,核心部分為 sagan_models.py:
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1) #
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention建構式中定義了三個 1 × 1 的摺積核,分別被命名為 query_conv , key_conv 和 value_conv 。
為啥命名為這三個名字呢?這和作者給它們賦予的含義有關。query 意為查詢,我們希望輸入一個畫素點,查詢(計算)到 feature map 上所有畫素點對這一點的影響。而 key 代表字典中的鍵,相當於所查詢的資料庫。query 和 key 都是輸入的 feature map,可以看成把 feature map 複製了兩份,一份作為 query 一份作為 key。
需要用一個什麼樣的函式,才能針對 query 的 feature map 中的某一個位置,計算出 key 的 feature map 中所有位置對它的影響呢?作者認為這個函式應該是可以透過“學習”得到的。那麼,自然而然就想到要對這兩個 feature map 分別做摺積核為 1 × 1 的摺積了,因為摺積核的權重是可以學習得到的。
至於 value_conv ,可以看成對原 feature map 多加了一層摺積對映,這樣可以學習到的引數就更多了,否則 query_conv 和 key_conv 的引數太少,按程式碼中只有 in_dims × in_dims//8 個。
接下來逐行研究 forward 函式:
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1)這行程式碼先對輸入的 feature map 摺積了一次,相當於對 query feature map 做了一次投影,所以叫做 proj_query。由於是 1 × 1 的摺積,所以不改變 feature map 的長和寬。feature map 的每個通道為如 (1) 所示的矩陣,矩陣共有 N 個元素(畫素)。

然後重新改變了輸出的維度,變成:
(m_batchsize,-1,width*height)
batch size 保持不變,width 和 height 融合到一起,把如 (1) 所示二維的 feature map 每個 channel 拉成一個長度為 N 的向量。
因此,如果 m_batchsize 取 1,即單獨觀察一個樣本,該操作的結果是得到一個矩陣,矩陣的的行數為 query_conv 摺積輸出的 channel 的數目 C( in_dim//8 ),列數為 feature map 畫素數 N。
然後作者又透過 .permute(0, 2, 1) 轉置了矩陣,矩陣的行數變成了 feature map 的畫素數 N,列數變成了通道數 C。因此矩陣維度為 N × C 。該矩陣每行代表一個畫素位置上所有通道的值,每列代表某個通道中所有的畫素值。

▲ 圖2. proj_query 的維度
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height)這行程式碼和上一行類似,只不過取消了轉置操作。得到的矩陣行數為通道數 C,列數為畫素數 N,即矩陣維度為 C × N。該矩陣每行代表一個通道中所有的畫素值,每列代表一個畫素位置上所有通道的值。

▲ 圖3. proj_key的維度
energy = torch.bmm(proj_query,proj_key)這行程式碼中, torch.bmm 的意思是 batch matrix multiplication。就是說把相同 batch size 的兩組 matrix 一一對應地做矩陣乘法,最後得到同樣 batchsize 的新矩陣。
若 batch size=1,就是普通的矩陣乘法。已知 proj_query 維度是 N × C, proj_key 的維度是 C × N,因此 energy 的維度是 N × N:
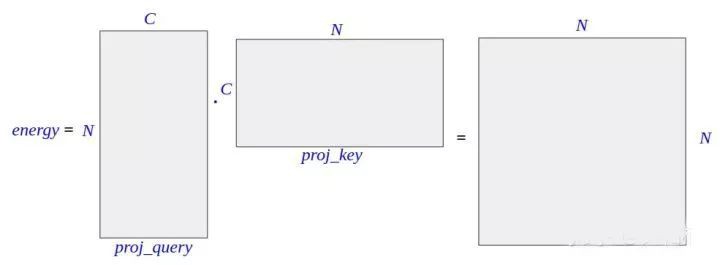
▲ 圖4. energy的維度
energy 是 attention 的核心,其中第 i 行 j 列的元素,是由 proj_query 第 i 行,和 proj_key 第 j 列透過向量點乘得到的。而 proj_query 第 i 行表示的是 feature map 上第 i 個畫素位置上所有通道的值,也就是第 i 個畫素位置的所有資訊,而 proj_key 第 j 串列示的是 feature map 上第 j 個畫素位置上的所有通道值,也就是第 j 個畫素位置的所有資訊。
這倆相乘,可以看成是第 j 個畫素對第 i 個畫素的影響。即,energy 中第 i 行 j 列的元素值,表示第 j 個畫素點對第 i 個畫素點的影響。
attention = self.softmax(energy)這裡 sofmax 是建構式中定義的,為按“行”歸一化。這個操作之後的矩陣,各行元素之和為 1。這也比較好理解,因為 energy 中第 i 行元素,代表 feature map 中所有位置的畫素對第 i 個畫素的影響,而這個影響被解釋為權重,故加起來應該是 1,故應對其按行歸一化。attention 的維度也是 N × N。
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height)上面的程式碼中,先對原 feature map 作一次摺積對映,然後把得到的新 feature map 改變形狀,維度變為 C × N ,其中 C 為通道數(註意和上面計算 proj_query proj_key 的 C 不同,上面的 C 為 feature map 通道數的 1/8,這裡的 C 與 feature map 通道數相同),N 為 feature map 的畫素數。
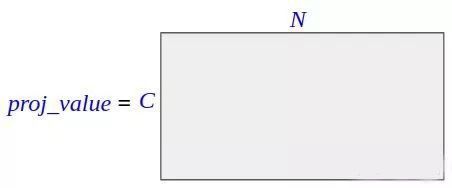
▲ 圖5. proj_value的維度
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)然後,再把 proj_value (C × N)矩陣同 attention 矩陣的轉置(N × N)相乘,得到 out (C × N)。之所以轉置,是因為 attention 中每行的和為 1,其意義是權重,需要轉置後變為每列的和為 1,施加於 proj_value 的行上,作為該行的加權平均。 proj_value 第 i 行代表第 i 個通道所有的畫素值, attention 第 j 列,代表所有畫素施加到第 j 個畫素的影響。
因此, out 中第 i 行包含了輸出的第 i 個通道中的所有畫素,第 j 串列示所有畫素中的第 j 個畫素,合起來也就是: out 中的第 i 行第 j 列的元素,表示被 attention 加權之後的 feature map 的第 i 個通道的第 j 個畫素的畫素值。再改變一下形狀, out 就恢復了 channel×width×height 的結構。
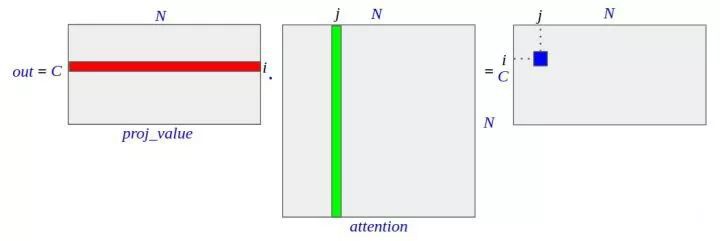
▲ 圖6. out的維度
out = self.gamma*out + x最後一行程式碼,借鑒了殘差神經網路(residual neural networks)的操作, gamma 是一個引數,表示整體施加了 attention 之後的 feature map 的權重,需要透過反向傳播更新。而 x 就是輸入的 feature map。
在初始階段, gamma 為 0,該 attention 模組直接傳回輸入的 feature map,之後隨著學習,該 attention 模組逐漸學習到了將 attention 加權過的 feature map 加在原始的 feature map 上,從而強調了需要施加註意力的部分 feature map。
總結
可以把 self attention 看成是 feature map 和它自身的轉置相乘,讓任意兩個位置的畫素直接發生關係,這樣就可以學習到任意兩個畫素之間的依賴關係,從而得到全域性特徵了。看論文時會被它複雜的符號迷惑,但是一看程式碼就發現其實是很 naive 的操作。
參考文獻
[1] Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He, Non-local Neural Networks, CVPR 2018.
[2] Takeru Miyato, Toshiki Kataoka, Masanori Koyama, Yuichi Yoshida, Spectral Normalization for Generative Adversarial Networks, ICLR 2018.

點選以下標題檢視更多往期內容:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 獲取最新論文推薦

