本文簡介
關於Linux記憶體管理逆向對映技術的歷史和現在的分析,投稿標題《逆向對映的演進》,後經過小編與郭大俠商議改為《Linux記憶體逆向對映(reverse mapping)技術的前世今生》。
作者簡介
郭健,一名普通的內核工程師,以鑽研Linux核心程式碼為樂,熱衷於技術分享,和朋友一起建立了蝸窩科技的網站,希望能彙集有同樣想法的技術人,以蝸牛的心態探討技術。
(小編畫外音:郭大俠是我最佩服的大俠,他為人低調,技術精湛又虛懷若谷,實為我輩Linuxer之楷模。他的http://www.wowotech.net/網站,有很多精彩的原創文章,已經使得百千萬讀者獲益。俠之大者,為國為民。)

稿件徵集
歡迎您給Linuxer投稿,贏得人民郵電非同步社群任意在售技術圖書。您隨便挑,詳情:Linuxer-“Linux開發者自己的媒體”首月稿件錄取和贈書名單
Linuxer-“Linux開發者自己的媒體”第二月稿件錄取和贈書名單
走過路過,不要錯過Linuxer哦,點選二維碼關註Linuxer!

一、前言
數學大師陳省身有一句話是這樣說的:瞭解歷史的變化是瞭解這門學科的一個步驟。今天,我把這句話應用到一個具體的Linux模組:瞭解逆向對映的最好的方法是瞭解它的歷史。本文介紹了Linux核心中的逆向對映機制如何從無到有,如何從笨重到輕盈的歷史過程,透過這些歷史的演進過程,希望能對逆向對映有更加深入的理解。
二、基礎知識
在切入逆向對映的歷史之前,我們還是簡單看看一些基礎的概念,這主要包括兩個方面:一個是逆向對映的定義,另外一個是引入逆向對映的原因。
1、什麼是逆向對映(reverse mapping)?
在聊逆向對映之前,我們先聊聊正向對映好了,當你明白了正向對映,逆向對映的概念也就易如反掌了。所謂正向對映,就是在已知虛擬地址和物理地址(或者page number、page struct)的情況下,為地址對映建立起完整的頁表的過程。例如,行程分配了一段VMA之後,並無對應的page frame(即沒有分配物理地址),直到程式訪問了這段VMA之後,產生異常,由核心為其分配物理頁面並建立起所有的各級的translation table。透過正向對映,我們可以將行程虛擬地址空間中的虛擬頁面對映到對應的物理頁面(page frame)。
逆向對映相反,在已知page frame的情況下(可能是PFN、可能是指向page descriptor的指標,也可能是物理地址,內核有各種宏定義用於在它們之間進行轉換),找到對映到該物理頁面的虛擬頁面們。由於一個page frame可以在多個行程之間共享,因此逆向對映的任務是把分散在各個行程地址空間中的所有的page table entry全部找出來。
一般來說,一個行程的地址空間內不會把兩個虛擬地址mapping到一個page frame上去,如果有多個mapping,那麼多半是這個page被多個行程共享。最簡單的例子就是採用COW的行程fork,在行程沒有寫的動作之前,內核是不會分配新的page frame的,因此父子行程共享一個物理頁面。還有一個例子和c lib相關,由於c lib是基礎庫,它會file mapping到很多行程地址空間中,那麼c lib中的程式正文段對應的page frame應該會有非常多的page table entries與之對應。
2、為何需要逆向對映?
之所以建立逆向對映機制主要是為了方便頁面回收。當頁面回收機制啟動之後,如果回收的page frame是位於核心中的各種記憶體cache中(例如 slab記憶體分配器),那麼這些頁面其實是可以直接回收,沒有相關的頁表操作。如果回收的是使用者行程空間的page frame,那麼在回收之前,核心需要對該page frame進行unmapping的操作,即找到所有的page table entries,然後進行對應的修改操作。當然,如果頁面是dirty的,我們還需要一些必要的磁碟IO操作。
可以給出一個實際的例子,例如swapping機制,在釋放一個匿名對映頁面的時候,要求對所有相關的頁表項進行更改,將swap area和page slot index寫入頁表項中。只有在所有指向該page frame的頁表項修改完畢後才可以將該頁交換到磁碟,並且回收這個page frame。demand paging的場景是類似的,只不過是需要把所有的page table entry清零,這裡就不贅述了。
三、史前文明
盤古開天闢地之前,宇宙混沌一片。對於逆向對映這個場景,我們的問題就是:沒有逆向對映之前,混沌的核心世界是怎樣的呢?這一章主要是回答這個問題的,分析的基礎是2.4.18內核的原始碼。
1、沒有逆向對映,系統如何運作?
也許年輕的內核工程師很難想象沒有逆向對映的核心世界,但實際上2.4時期的核心就是這樣的。讓我們想象一下,我們自己就是page reclaim機制的維護者,看看我們目前的困境:如果沒有逆向對映機制,那麼struct page中沒有維護任何的逆向對映的資料。這種情況下,核心不可能透過簡單的方法來找到page frame所對應的那些PTEs。當回收一個被多個行程共享的page frame,我們該怎麼辦呢?
本身回收使用者行程的物理頁幀並不複雜,這需要memory mapping和swapping機制的支援。這兩種機制的工作原理類似,只不過一個用於file mapped page,另外一個用於anonymous page。不過對於頁面回收而言,他們的工作原理類似:就是把某些行程不常使用的page frame交換到磁碟上去,同時解除行程和這個page frame的一切關係,完成這兩步之後,這個物理頁幀已經自由了,可以回收到夥伴系統中。
OK,瞭解了基本原理,現在需要看看如何具體實現:不常使用的page frame很好找(inactive lru連結串列),不過斷絕page frame和行程們之間的關係很難,因為沒有逆向對映。不過這難不倒Linux核心開發人員,他們選擇了掃描整個系統的各個行程的地址空間的方法。
2、如何對行程地址空間進行掃描?
下圖是一個對行程地址空間進行掃描的示意圖:

系統中的所有行程地址空間(memory descriptor)被串成一個連結串列,連結串列頭就是init_mm,系統中所有的行程地址空間都掛在了這個連結串列中。所謂scan當然就是沿著這條mm連結串列進行了。當然,頁面回收演演算法儘量不scan整個系統的全部行程地址空間,畢竟那是一個比較笨的辦法。回收演演算法可以考慮收縮記憶體cache,也可以遍歷inactive_list來試圖完成本次reclaim數目的要求(該連結串列中有些page不和任何行程相關),如果透過這些方法釋放了足夠多的page frame,那麼一切都搞定了,不需要scan行程地址空間。當然,情況並非總是那麼美好,有時候,必須啟動行程物理頁面回收過程才能滿足頁面回收的要求。
行程物理頁面回收過程是透過呼叫swap_out函式完成的,而scan行程地址空間的程式碼也是開始於這個函式。該函式是一個三層巢狀結構:
(1) 首先沿著init_mm,對每一個行程地址空間進行掃描
(2) 在掃描一個行程地址空間的時候,對屬於該行程地址空間的每一個VMA進行掃描
(3) 在掃描每一個VMA的時候,對屬於該VMA的每一個page進行掃描
在掃描過程中,如果命中了行程A的page frame0,由於該page只是被行程A 使用(即只是被A行程mapping),那麼可直接unmap並回收該page。對於共享頁面,我們不能這麼處理了,例如上圖中的page frame 1,但scan A行程的時候,如果條件符合,那麼我們會unmap該page,解除它和行程A的關係,當然,這時候不能回收該page,因為行程X還在使用該page。直到scan過程歷經千山萬水來到行程X,完成對page frame 1的unmaping操作,該物理頁面才可以真正會夥伴系統的懷抱。
3、地址空間掃描的細節問題
首先,第一個問題:到底scan多少虛擬地址空間才停止scan呢?當標的已經達到的時候,例如本次scan打算reclaim 32個page frame,如果標的達到,那麼scan停止,不需scan全部虛擬地址空間。還有一種比較悲慘的情況,那就是scan了系統中所有的地址空間之後,仍然沒有達成標的,這時候也就可以停止了,不過這屬於OOM的處理了。為了確保系統中的行程被均勻的scan(畢竟swap out會影響行程效能,我們肯定不能只逮住部分行程薅其羊毛),每次scan完成後,記錄當前scan的位置(儲存在swap_mm變數),等下次又啟動scan過程的時候,從swap_mm開始繼續scan。
由於對效能有影響,swap out需要雨露均霑,各個行程都跑不掉。同樣的道理,對於一個行程的地址空間,我們一樣也是需要公平對待,因此需要儲存每次scan的虛擬地址(mm->swap_address),這樣,每次重啟scan的時候,總是從swap_mm那個地址空間的mm->swap_address虛擬地址開始scan。
具體對一個page frame進行swap out的程式碼位於try_to_swap_out函式中,在這個函式中,如果條件滿足,會解除該page frame的該行程之間的關係,完成必要的IO操作,該page reference count減一,對應的pte清零或者設定swap entry等。當然,swap out一個page之後,我們並非一定能夠回收它,因為這個page很可能被多個行程共享。而在scan過程中,如果碰巧找到了該page對應的所有的頁面表條目,那麼說明該頁面已經不被任何行程取用,這時候該page frame就會被逐出磁碟,從而完成一個頁面的回收。
四、開天闢地
時間又回到2002年1月,那時VM大神Rik van Riel遭遇了人生中的一次重大挫折,他的耗費心血維護的程式碼被一個全新的VM子系統取代了。不過Rik van Riel並沒有消沉下去,他在憋大招,也就是傳說中的reverse mapping(後文簡稱rmap)。本章主要描述第一個版本的rmap,程式碼來自Linux 2.6.0。
1、設計概念
如何構建rmap?最直觀的想法就是針對每一個page frame,我們維護一個連結串列,儲存屬於該page的所有PTEs。因此,Rik van Riel給struct page增加了一個pte chain的成員,以便把所有mapping到該page的pte entry指標給串起來。這樣想要unmap一個page就易如反掌了,沿著這個pte chain就可以找到所有的mappings。一個基本的示意圖如下,下麵的小節會給出更詳細的解釋。
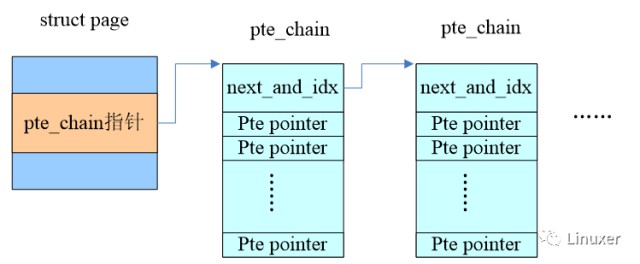
2、對Struct page的修改
Struct page的修改如下:
struct page {
……
union {
struct pte_chain *chain;
pte_addr_t direct;
} pte;
……
當然,很多頁面都不是共享的,只有一個pte entry,因此direct直接指向那個pte entry就OK了。如果存在頁面共享的情況,那麼chain成員則會指向一個struct pte_chain的連結串列。
3、定義struct pte_chain
struct pte_chain {
unsigned long next_and_idx;
pte_addr_t ptes[NRPTE];
} ____cacheline_aligned;
如果pte_chain只儲存一個pte entry的指標那麼就太浪費了,比較好的方法是把struct pte_chain對齊在cache line並讓整個struct pte_chain佔用一個cache line。除了next_and_idx用於指向下一個pte_chain,形成連結串列之外,其餘的空間都用於儲存pte entry指標。由於pte entry指標形成了陣列,因此我們還需要一個index指示下一個空閑的pte entry pointer的位置,由於pte_chain對齊在cache line,因此next_and_idx的LSB的若干個bit是等於0的,可以復用做index。
4、頁面回收演演算法的修改
在進入基於rmap的頁面回收演演算法之前,讓我們先回憶一下痛苦的過去。假設一個物理頁面P被A和B兩個行程共享,在過去,釋放P這個物理頁面需要掃描行程地址空間,首先scan到A行程,解除P和A行程的關係,但是這時候不能回收,B行程還在使用該page frame。當然掃描過程最終會來到B行程,只有在這時候才有機會回收這個物理頁面P。你可能會問:如果scan B行程地址空間的時候,A行程又訪問了P從而導致對映建立。然後scan A的時候,B行程又再次訪問,如此反反覆復,那麼P不就永遠無法回收了嗎?這個怎麼辦呢?這個……理論上是這樣的,別問我,其實我也很絕望。
有了rmap,頁面回收演演算法頓時感覺輕鬆多了,只要是頁面回收演演算法看中的page frame,總是能夠透過try_to_unmap解除和所有行程的關聯,從而將其回收到夥伴系統中。如果該page frame沒有共享(page flag設定PG_direct flag),那麼page->pte.direct直接命中pte entry,呼叫try_to_unmap_one來進行unmap的操作。如果對映到了多個虛擬地址空間,那麼沿著pte_chain依次呼叫try_to_unmap_one來進行unmap的操作。
五、女媧補天
雖然Rik van Riel開闢了逆向對映的新天地,但是,天和地都有著巨大的窟窿,需要有人修補。首先讓我們看看這個“巨大的窟窿”是什麼?
在引入第一個版本的rmap之後,Linux的頁面回收變得簡單、可控了,但是這個簡單的設計是有代價的:每一個struct page增加一個指標成員,在32bit的系統上也就是增加了4B。考慮到系統為了管理記憶體會為每一個page frame建立一個struct page物件,引入rmap而導致的記憶體開銷也不是一個小數目啊。此外,share page需要建立pte_chain連結串列,也是一個不小的記憶體開銷。除了記憶體方面的壓力,第一個版本的rmap對效能也造成了一定的影響。例如:在fork操作的時候,父子行程共享了很多的page frame,這樣,在copy page table的時候就會伴隨大量的pte_chain的操作,從而讓fork的速度變得緩慢。
本章就是帶領大家看看object-based reverse mapping(後文簡稱objrmap)是如何填補那個“巨大的窟窿”。本章的程式碼來自2.6.11版本的核心。
1、問題的引入
推動rmap最佳化的動力來自記憶體方面的壓力,與此相關的問題是:32-bit的Linux內核是否支援4G以上的memory。在1999年,Linus的決定是:32-bit的Linux核心永遠也不會支援2G以上的記憶體。不過歷史的洪流不可阻擋,處理器廠商設計了擴充套件模組以便定址更多的記憶體,高階的伺服器也配置了越來越多的記憶體。這也迫使Linus改變之前的思路,讓Linux核心支援更大的記憶體。
紅帽公司的Andrea Arcangeli當時正在做的工作就是讓32-bit的Linux執行在配置超過32G記憶體的公司伺服器上。在這些伺服器上往往啟動大量的行程,共享了大量的物理頁幀,消耗了大量的記憶體。對於Andrea Arcangeli來說,記憶體消耗的真正元兇是明確的:逆向對映模組,這個模組消耗了太多的low memory,從而導致了系統的各種crash。為了讓自己的工作繼續推進,他必須解決rmap引入的記憶體擴充套件性(memory scalability)問題。
2、file mapped的最佳化
並非只有Andrea Arcangeli關註到了rmap的記憶體問題,在2.5版本的開發過程中,IBM公司的Dave McCracken就已經提交了patch,試圖在保證逆向對映功能的基礎上,同時又能修正rmap帶來的各種問題。
Dave McCracken的方案是一種基於物件的逆向對映機制。在過去,透過rmap,我們可以從struct page直接獲取其對應的ptes,objrmap的方法藉助其他的資料物件來完成從struct page檢索到其對應ptes的過程,這個過程的示意圖如下:

對於objrmap而言,尋找一個page frame的mappings是一個比較長的路徑,它藉助了VMA(struct vm_area_struct)這個資料物件。我們知道對於某些page frame是有後備檔案的,這種型別的頁面和某個檔案相關,例如行程的正文段和該行程的可執行檔案相關。此外,行程可以呼叫mmap()對某個檔案進行mapping。對於這些頁幀我們稱之file mapped page。
對於這些檔案對映頁面,其struct page中有一個成員mapping指向一個struct address_space,address_space是和檔案相關的,它儲存了檔案page cache相關的資訊。當然,我們這個場景主要關註一個叫做i_mmap的成員。一個檔案可能會被對映到多個行程的多個VMA中,所有的這些VMA都被掛入到i_mmap指向的Priority search tree中。
當然,我們最終的標的是PTEs,下麵這幅圖展示瞭如何從VMA和struct page中的資訊匯出該page frame的虛擬地址的:
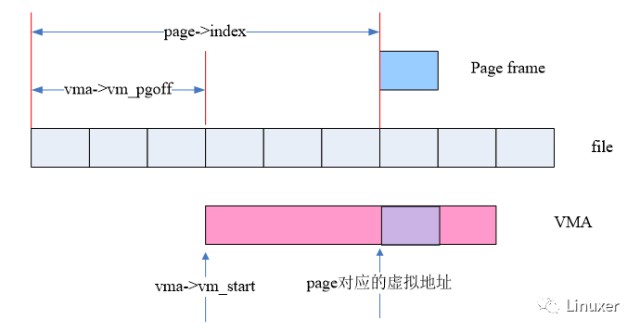
而在linux kernel中,函式vma_address可以完成這個功能:
static inline unsigned long
vma_address(struct page *page, struct vm_area_struct *vma)
{
pgoff_t pgoff = page->index << (PAGE_CACHE_SHIFT – PAGE_SHIFT);
unsigned long address;
address = vma->vm_start + ((pgoff – vma->vm_pgoff) << PAGE_SHIFT);
return address;
}
對於file mapped page,page->index表示的是對映到檔案內的偏移(Byte為單位),而vma->vm_pgoff表示的是該VMA對映到檔案內的偏移(page為單位),因此,透過vma->vm_pgoff和page->index可以得到該page frame在VMA中的地址偏移,再加上vma->vm_start就可以得到該page frame的虛擬地址。有了虛擬地址和地址空間(vma->vm_mm),我們就可以透過各級頁表找到該page對應的pte entry。
3、匿名頁面的最佳化
我們都知道,使用者空間行程的頁面主要有兩種,一種是file mapped page,另外一種是anonymous mapped page。Dave McCracken的objrmap方案雖好,但是隻是適用於file mapped page,對於匿名對映頁面,這個方案無能為力。因此,我們必須為匿名對映頁面也設計一種基於物件的逆向對映機制,最後形成full objrmap方案。
為瞭解決記憶體擴充套件性的問題,Andrea Arcangeli全力工作在full objrmap方案上,不過他還有一個競爭對手,Hugh Dickins,同時也提交了一系列full objrmap補丁,試圖併入核心主線,顯然,在匿名對映頁面上,最後勝出的是Andrea Arcangeli,他的匿名對映方案如下圖所示:

和file mapped類似,anonymous page也是透過VMA來尋找page frame對應的pte entry。由於檔案對映頁面的VMA數量可能非常大,因此我們採用Priority search tree這樣的資料結構。對於匿名對映頁面,其數量一般不會太大,所以使用連結串列結構就OK了。
為了節省記憶體,我們復用了struct page中的mapping指標:一個page frame如果是file mapped,其mapping指標指向對應檔案的address_space資料結構。如果是anonymous page,那麼mapping指標指向anon_vma資料結構。雖然節省了記憶體,但是降低了可讀性,但是由於核心會為每一個page frame建立一個對應的struct page資料物件,該資料結構即便是增加4B對整個系統的記憶體消耗都是巨大的,因此核心還是採用了較為醜陋的方式來定義mapping這個成員。透過struct page中的mapping成員我們可以獲得該page對映相關的資訊,總結如下:
(1) 等於NULL,表示該page frame不再記憶體中,而是被swap out到磁碟去了。
(2) 如果不等於NULL,並且least signification bit等於1,表示該page frame是匿名對映頁面,mapping指向了一個anon_vma的資料結構。
(3) 如果不等於NULL,並且least signification bit等於0,表示該page frame是檔案對映頁面,mapping指向了一個該檔案的address_space資料結構。
透過anon_vma資料結構,我們可以得到對映到該page的所有的VMA,至此,匿名對映和file mapped匯合,進一步解決的問題僅僅是如何從VMA到pte entry而已。上一節,我們描述了vma_address函式如何獲取file mapped page的虛擬地址,其實anonymous page的邏輯是一樣的,只不過vma->vm_pgoff和page->index的基礎點不一樣了,對於file mapped的場景,這個基礎點是檔案起始位置。對於匿名對映,起始點有兩種情況,一種是share anonymous mapping,起點位置是0。另外一種是private anonymous mapping,起點位置是mapping的虛擬地址(除以page size)。但是不管如何,從VMA和struct page得到對應虛擬地址的演演算法概念是類似的。
六、捲土重來
full objrmap進入核心之後,看起來一切都很完美了,比起她的前任,Rik van Riel的rmap方案,objrmap各方面的指標都是全面碾壓rmap。首次將逆向對映引入內核的大神Rik van Riel遭受了第二次的打擊,不過他依然鬥志昂揚並試圖東山再起。
Objrmap雖然完美,不過晴朗的天空中飄著一朵烏雲。大神Rik van Riel敏銳的看到了逆向對映的那朵“烏雲“,提出了自己的解決方案。本章主要描述新的anon_vma機制,程式碼來自4.4.6核心。
1、舊anon_vma機制有什麼問題?
我們先一起來看看舊anon_vma機制下,系統是如何運作的。VMA_P是父行程的一個匿名對映的VMA,A和C都已經分配了page frame,而其他的page都還都沒有分配物理頁面。在fork之後,子行程copy了VMA_P,當然由於採用了COW技術,這時候父子行程的匿名頁面會共享,同時在父子行程地址空間對應的pte entry中標註write protect的標記,如下圖所示:

按理說不同行程的匿名頁面(例如stack、heap)是私有的,不會共享,但是為了節省記憶體,在父行程fork子行程之後,父子行程對該頁面執行寫操作之前,父子行程的匿名頁是共享的,所以這些page frame指向同一個anon_vma。當然,共享只是短暫的,一旦有write操作就會產生異常,併在異常處理中分配page frame,解除父子行程匿名頁面的共享,具體如下圖的page A所示:

這時候由於寫操作,父子行程原本共享的page frame已經不再共享,然而,這兩個page卻仍然指向同一個anon_vma,不僅如此,對於B這樣的頁面,一開始就沒有在父子行程之間共享,當首次訪問的時候(無論是父行程還是子行程),透過do_anonymous_page函式分配的page frame也是同樣的指向一個anon_vma。也就是說,父子行程的VMA共享一個anon_vma。
在這種情況下,我們看看unmap page frame1會發生什麼。毫無疑問,page frame1對應的struct page的mapping成員指向了上圖中的anon_vma,遍歷anon_vma會命VMA_P和VMA_C,這裡面,VMA_C是無效的VMA,本來就不應該匹配到。如果anon_vma的連結串列沒有那麼長,那麼整體效能也OK。然而,在有些網路伺服器中,系統非常依賴fork,某個服務程式可能會fork巨大數量的子行程來處理服務請求,在這種情況下,系統效能嚴重下降。Rik van Riel給出了一個具體的示例:系統中有1000行程,都是透過fork生成的,每個行程的VMA有 1000個匿名頁。根據目前的軟體架構,anon_vma連結串列中會有1000個vma 的節點,而系統中有一百萬個匿名頁面屬於同一個anon_vma。
這樣的系統會導致什麼樣的問題呢?我們一起來看看try_to_unmap_anon函式,其程式碼框架如下:
static int try_to_unmap_anon(struct page *page)
{……
anon_vma = page_lock_anon_vma(page);
list_for_each_entry(vma, &anon;_vma->head, anon_vma_node) {
ret = try_to_unmap_one(page, vma);
}
spin_unlock(&anon;_vma->lock);
return ret;
}
當系統中的一個CPU在執行try_to_unmap_anon函式的時候,需要遍歷VMA連結串列,這時會持有anon_vma->lock這個自旋鎖。由於anon_vma存有了很多根本無關的VMA,透過,page table的檢索過程,你就會發現這個VMA根本和準備unmap的page無關,因此只能scan下一個VMA,整個過程需要消耗大量的時間,延長了臨界區(複雜度是O(N))。與此同時,其他CPU在試獲取這把鎖的時候,基本會被卡住,這時候整個系統的效能可想而知了。更加糟糕的是核心中並非只有unmap匿名頁面的時候會上鎖、遍歷VMA連結串列,還有一些其他的場景也會這樣(例如page_referenced函式)。想象一下,一百萬個頁面共享這一個anon_vma,對anon_vma->lock自旋鎖的競爭那是相當的激烈啊。
2、改進的方案
舊的方案的癥結所在是anon_vma承載了太多行程的VMA了,如果能將其變成per-process的,那麼問題就解決了。Rik van Riel的解決辦法是為每一個行程建立一個anon_vma結構並透過各種資料結構把父子行程的anon_vma(後面簡稱AV)以及VMA連結在一起。為了連結anon_vma,核心引入了一個新的結構,稱為anon_vma_chain(後面簡稱AVC):
struct anon_vma_chain {
struct vm_area_struct *vma;――指向該AVC對應的VMA
struct anon_vma *anon_vma;――指向該AVC對應的AV
struct list_head same_vma; ――連結入VMA連結串列的節點
struct rb_node rb;―――連結入AV紅黑樹的節點
unsigned long rb_subtree_last;
};
AVC是一個神奇的結構,每個AVC都有其對應的VMA和AV。所有指向相同VMA的AVC會被連結到一個連結串列中,連結串列頭就是VMA的anon_vma_chain成員。而一個AV會管理若干的VMA,所有相關的VMA(其子行程或者孫行程)都掛入紅黑樹,根節點就是AV的rb_root成員。
這樣的描述非常枯燥,估計第一次接觸逆向對映的同學是不會明白的,不如我們一起來看看AV、AVC和VMA的“大廈”是如何搭建起來的。
3、當VMA和VA首次相遇
由於採用了COW技術,子行程和父行程的匿名頁面往往是共享的,直到其中之一發起寫操作。但是如果子行程執行了exec的系統呼叫,載入了自己的二進位制image,這時候,子行程和父行程的執行環境(包括匿名頁面)就分道揚鑣了(參考flush_old_exec函式),我們的場景就是從這麼一個全新的exec後的行程開始。當該行程的匿名對映VMA透過page fault分配第一個page frame的時候,核心會構建下圖所示的資料關係:
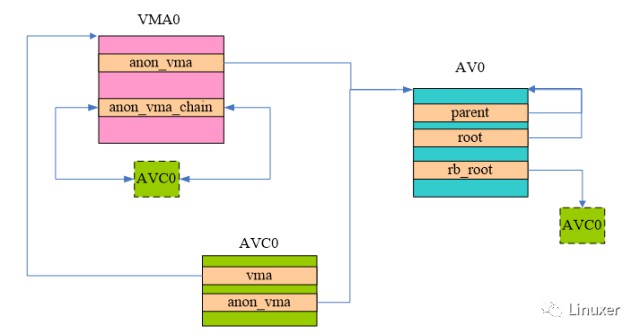
上圖中的AV0就是該行程的anon_vma,由於它是一個頂級結構,因此它的root和parent都是指向了自己。AV這個資料結構當然為了管理VMA了,不過新機制中,這是透過AVC進行中轉的。上圖中的AVC0搭建了該行程VMA和AV之間的橋梁,分別有指標指向了VMA0和AV0,此外,AVC0插入到AV的紅黑樹,同時也會插入到VMA的連結串列中。
對於這個新分配的page frame而言,它會mapping到VMA對應的某個虛擬地址上去,為了維護逆向對映的關係,struct page中的mapping指向了AV0,index成員指向了該page在整個VMA0中的偏移。圖中沒有畫出這個關係,主要因為這是老生常談了,相信大家都已經熟悉。
VMA0中隨後可能會有若干的page frame被mapping到該VMA的某個虛擬頁面,不過上面的結構不會變化,只不過每一個page中的mapping都指向了上圖中的AV0。另外,上圖中那個虛線綠色block的AVC0其實等於那個綠色實線的AVC0 block,也就是說這時候該VMA只有一個anon_vma_chain,即AVC0,上圖只是方便表示該AVC也會被掛入VMA的連結串列,掛入anon_vma的紅黑樹而已。
如果想參考相關的程式碼可以仔細看看do_anonymous_page或者do_cow_fault。
4、在fork的時候,匿名對映的VMA經歷了什麼?
一旦fork,那麼子行程會copy父行程的VMA(參考函式dup_mmap),子行程會有自己的VMA,同時也會分配自己的AV(舊的機制下,多個行程共享一個AV,而新的機制中,AV是per process的),然後建立父子行程之間的VMA、VA的“大廈”,主要的步驟如下:
(1) 呼叫anon_vma_clone函式,建立子行程VMA和“父行程們”VA的關係
(2) 建立子行程VMA和子行程VA的關係
怎樣叫做建立VMA和VA的關係?其實就是anon_vma_chain_link函式的呼叫過程,步驟如下:
(1) 分配一個AVC結構,成員指標指向對應的VMA和VA
(2) 將該AVC加入VMA連結串列
(3) 將該AVC加入VA紅黑樹
我們一開始先別把事情搞得太複雜,先看看一個全新行程fork子行程的場景。這時候,核心會構建下圖所示的資料關係:

首先看看如何建立子行程VMA1和父行程AV0的關係,這裡需要遍歷VMA0的anon_vma_chain連結串列,當然現在這個連結串列只有一個AVC0(link到AV0),為了建立和父行程的聯絡,我們分配了AVC_x01,它是一個橋梁,連線了父子行程。(註:AVC_x01中的x表示連線,01表示連線level 0和level 1)。透過這個橋梁,父行程可以找到子行程的VMA(因為AVC_x01插入AV0的紅黑樹中),而子行程也可以找到父行程的AV(因為AVC_x01插入VMA1的連結串列中)。
當然,自己的anon_vma也需要建立。在上圖中,AV1就是子行程的anon_vma,同時分配一個AVC1來連線該子行程的VMA1和AV1,並呼叫anon_vma_chain_link函式將AVC1插入VMA1的連結串列和AV1的紅黑樹中。
父行程也會建立其他新的子行程,新建立的子行程的層次和VMA1、VA1的類似,這裡就不描述了。不過需要註意的是:父行程每建立一個子行程,AV0的紅黑樹中會增加每一個起“橋梁”作用的AVC,以此連線到子行程的VMA。
5、構建三層大廈
上一節描述了父行程建立子行程的情況,如果子行程再次fork,那麼整個VMA-VA的大廈將形成三層結構,具體如下圖所示:

當然,首先要進行的仍然是建立孫行程VMA和“父行程們”VA的關係,這裡的“父行程們”其實是泛指孫行程的上層的那些行程們。對於這個場景,“父行程們”指的就是上圖中的A行程和B行程。如何建立?在fork的時候,我們進行VMA的複製:即分配VMA2並以VMA1為原型copy到VMA2中。Copy是沿著VMA1的AVC連結串列進行的,該連結串列有兩個元素:AVC1和 AVC_x01,分別和父行程A和子行程B的AV關聯。因此,在孫行程C中,我們會分配AVC_x02和AVC_x12兩個AVC,並建立level 2層和level 0層以及level 1層之間的關係。
同樣的,自己level的anon_vma也需要建立。在上圖中,AV2就是孫行程C的anon_vma,同時分配一個AVC2來連線該孫行程的VMA2和AV2,並呼叫anon_vma_chain_link函式將AVC2插入VMA2的連結串列和AV2的紅黑樹中。
AV2中的root指向root AV,也就是行程A的AV。Parent成員指向其B行程(C的父行程)的AV。透過Parent這樣的指標,不同level的AV建立了父子關係,而透過root指標,每一個level的AV都可以尋找找到root AV。
6、page frame是如何加入“大廈”中?
前面幾個小節重點討論了hierarchy AV的結構是如何搭建起來的,也就是描述fork的過程中,父子行程的VMA、AVC和AV是如何聯絡的。本小節我們將一起來看看父子行程之一訪問頁面,發生了page fault的處理過程。這個處理過程有兩個場景,一個是父子行程都沒有page frame,這時候,核心程式碼會呼叫do_anonymous_page分配page frame並呼叫page_add_new_anon_rmap函式建立該page和對應VMA的關係。第二個場景複雜一點,是父子共享匿名頁面的場景,當發生write fault的時候,也是分配page frame並呼叫page_add_new_anon_rmap函式建立該page和對應VMA的關係,具體程式碼位於do_wp_page函式。無論哪一個場景,最終都是將該page的mapping成員指向了該行程所屬的AV結構。
7、為何建立如此複雜的“大廈”?
如果你能堅持讀到這裡,那麼說明你對枯燥文字的忍受能力還是很強的,哈哈。Page、VMA、VAC、VA組成瞭如此複雜的層次結構到底是為什麼呢?是為了打擊你學習內核的興趣嗎?非也,讓我們還是用一個實際的場景來說明這個“大廈”的功能。

我們透過下麵的步驟建立起上圖的結構:
(1) P行程的某個VMA中有兩類頁面: 一類是有真實的物理頁面的,另外一類是還沒有配備物理頁面的。上圖中,我們分別跟蹤有物理頁面的A以及還沒有分配物理頁面的B。
(2) P行程fork了P1和P2
(3) P1行程fork了P12行程
(4) P1行程訪問了A頁面,分配了page frame2
(5) P12行程訪問了B頁面,分配了page frame3
(6) P2行程訪問了B頁面,分配了page frame1
(7) P2行程fork了P21行程
經過上面的這一些動作之後,我們來看看page frame共享的情況:對於P行程的page frame(是指該page 的mapping成員指向P行程的AV,即上圖中的AV_P)而言,他可能會被任何一個level的的子行程VMA中的page所有共享,因此AV_P需要包括其子行程、孫行程……的所有的VMA。而對於P1行程而言,AV_P1則需要包括P1子行程、孫行程……的所有的VMA,有一點可以確認:至少父行程P和兄弟行程P2的VMA不需要包括在其中。
現在我們回頭看看AV結構的大廈,實際上是符合上面的需求的。
8、頁面回收的時候,如何unmap一個page frame的所有的對映?
搭建了那麼複雜的資料結構大廈就是為了應用,我們一起看看頁面回收的場景。這個場景需要透過page frame找到所有對映到該物理頁面的VMAs。有了前面的鋪墊,這並不複雜,透過struct page中的mapping成員可以找到該page對應的AV,在該AV的紅黑樹中,包含了所有的可能共享匿名頁面的VMAs。遍歷該紅黑樹,對每一個VMA呼叫try_to_unmap_one函式就可以解除該物理頁幀的所有對映。
OK,我們再次回到這一章的開始,看看那個長臨界區導致的效能問題。假設我們的伺服器上有一個服務行程A,它fork了999個子行程來為世界各地的網友服務,行程A有一個VMA,有1000個page。下麵我們就一起來對比新舊機制的處理過程。
首先,百萬page共享一個anon_vma的情況在新機制中已經解決,每一個行程都有自己特有的anon_vma物件,每一個行程的page都指向自己特有的anon_vma物件。在舊的機制中,每次unmap一個page都需要掃描1000個VMA,而在新的機制中,只有頂層的父行程A的AV中有1000個VMA,其他的子行程的VMA的數目都只有1個,這大大降低了臨界區的長度。
七、後記
本文帶領大家一起簡略的瞭解了逆向對映的發展過程。當然,時間的車輪永不停息,逆向對映機制還在不斷的修正,如果你願意,也可以瞭解其演進過程的基礎上,提出自己的最佳化方案,在其歷史上留下自己的印記。
