作者:王振耀
連結:http://www.cnblogs.com/wangzhenyao1994/p/10386907.html
在本章中我們將展示兩個獨立的例子,一個用於人臉檢測,另一個用於動態檢測,以及如何快速地將這些功能新增到應用程式中。
面部檢測
人臉檢測,是人臉識別的第一部分。如果你不能從螢幕上的所有東西中識別出一個或多個人臉,那麼你將永遠無法識別那是誰的臉。
首先讓我們看一張我們的應用程式截圖:

上圖中,透過攝像頭我們已經捕獲到一張影象,接下來啟用面部跟蹤,看看會發生什麼:
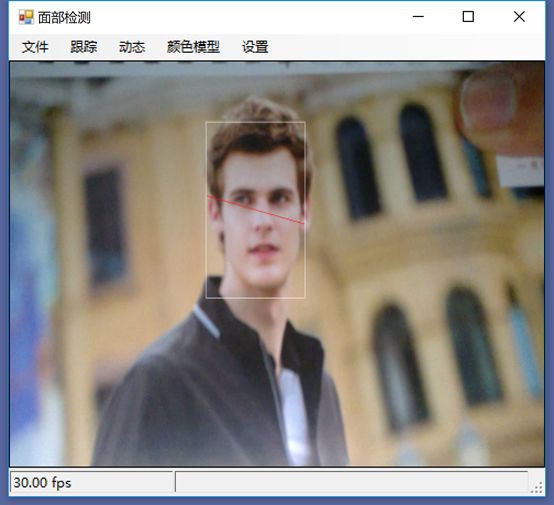
物體面部特徵正在被追蹤。我們在物體周圍看到的是面部追蹤器(白色線框),它告訴我們我們這裡有一張臉;以及我們的角度探測器(紅線),它提供了一些關於我們臉所處水平方向的參考。
當我們移動物體時,面部追蹤器和角度探測器會追蹤他。這一切都很好,但是如果我們在真實的人臉上啟用面部跟蹤會發生什麼呢?
如下圖,面部追蹤器和角度探測器正在追蹤人的面部。

當我們把頭從一邊移到另一邊時,面部追蹤器會跟蹤這個動作,可以看到角度探測器會根據它所識別的面部水平角度進行調整。
可以看到,在這裡我們的顏色是黑白的,而不是彩色的。因為這是一個直方圖的反向投影,而且它是一個可以更改的選項。
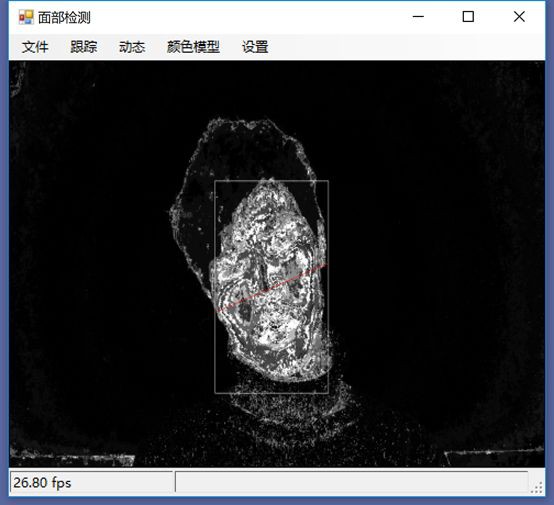
即使我們遠離攝像機,讓其他物體也進入視野中,面部追蹤器也能在諸多噪音中跟蹤我們的臉,如下圖所示。這正是我們在電影中看到的面部識別系統的工作原理,儘管它更為先進。

現在讓我們深入程式內部,看看它到底是如何工作的。
首先,我們需要問自己一個問題,我們想要解決的問題到底是什麼。到底是人臉識別還是人臉檢測。這裡不得不提到Viola-Jones演演算法,因為,首先它有很高的檢出率和很低的誤報率,然後它非常擅長對資料的實時處理,最終要的一點是,它非常善於從非人臉中分別出人臉。
要永遠記住,人臉檢測只是人臉識別的第一步!
這個演演算法要求輸入一個完整的正面,垂直的臉。臉部需要直接指向採集裝置,頭部儘量不要歪,不要昂頭或低頭。
這裡有必要在強調一次,我們要做的只是在影象中檢測出人臉即可。
我們的演演算法需要經過四個步驟來完成這件事:
1、Haar 特徵選擇
2、建立一個完整的影象
3、AdaBoost演演算法(透過迭代弱分類器而產生最終的強分類器的演演算法) 訓練分類器
4、級聯分類器
在正式開始之前,讓我們先捋一捋面部檢測到底是如果工作的。所有的臉,無論是人的,動物的還是其他的,都有一些相似的特徵。
例如,都有一個鼻子,兩個鼻孔,一張嘴巴,兩個眼睛,兩個耳朵等等。我們的演演算法透過Haar特徵來匹配這些內容,我們可以透過其中任一項找到其他的特徵。
但是,我們這裡會遇到一個問題。在一個24×24畫素的視窗中,一共有162336個可能的特徵。如果這個計算結果是正確的,那麼計算他們的時間和成本將非常之高。因此,我們將會使用一種被稱為adaptive boosting(自適應提升法)的演演算法,或者更為常見的AdaBoost演演算法。
如果你研究過機器學習,我相信你聽說過一種叫做boosting(提升)的技術。我們的學習演演算法將使用AdaBoost來選擇最好的特徵並訓練分類器來使用它們。
AdaBoost可以與許多型別的學習演演算法一起使用,並且被業界認為是許多需要增強的任務的最佳開箱即用演演算法。通常在切換到另一種演演算法並對其進行基準測試之前,您不會註意到它有多好和多快。實際上這種區別是非常明顯的。
在繼續之前,我們先來瞭解一下什麼是boosting(提升)技術。
Boosting從其他弱學習演演算法中獲取輸出,並將其與weighted sum(加權和)結合,加權和是boost分類器的最終輸出。AdaBoost的自適應部分來自於這樣一個事實,即後續的學習者被調整,以支援那些被以前的分類器錯誤分類的實體。
與其他演演算法相比,該演演算法更傾向於對資料進行過擬合,所以AdaBoost對噪聲資料和異常值很敏感。因此我們在準備資料的時候,需要格外註意這一點。
現在,讓我們來看看示例中的程式到底是如何工作的。對於這個示例,我們將再次使用Accord框架。
首先建立一個FaceHaarCascade物件。該物件包含一系列 Haarlike 的特徵的弱分類階段的集合。每個階段都包含一組分類器樹, 這些分類器樹將在決策過程中使用。FaceHaarCascade自動為我們建立了所有這些階段和樹,而不需要我們去關心具體實現的細節。
首先,需要在底層構建一個決策樹,它將為每個階段提供節點,併為每個特性提供數值。以下是Accord的部分原始碼。
List stages = new List();
List nodes;
HaarCascadeStage stage;
stage = new HaarCascadeStage(0.822689414024353);
nodes = new List();
nodes.Add(
new[] {
new HaarFeatureNode(
0.004014195874333382,0.0337941907346249,
0.8378106951713562,
new int[] { 3, 7, 14, 4, -1 },
new int[] { 3, 9, 14, 2, 2 }
)
}
);
nodes.Add(
new[] {
new HaarFeatureNode(
0.0151513395830989,
0.1514132022857666,
0.7488812208175659,
new int[] { 1, 2, 18, 4, -1 },
new int[] { 7, 2, 6, 4, 3 }
)
}
);
nodes.Add(
new[] {
new HaarFeatureNode(
0.004210993181914091,
0.0900492817163467,
0.6374819874763489,
new int[] { 1, 7, 15, 9, -1 },
new int[] { 1, 10, 15, 3, 3 }
)
}
);
一旦構建完成,我們就可以使用cascade物件來建立HaarObjectDetector,這就是我們將用於檢測的物件。
接下來我們需要提供:
1、我們的面部級聯物件
2、搜尋物件時使用的最小視窗大小
3、我們的搜尋樣式,假設我們只搜尋一個物件
4、在搜尋期間重新縮放搜尋視窗時要使用的重新縮放因子
HaarCascade cascade = new FaceHaarCascade();
detector = new HaarObjectDetector(
cascade,
25,
ObjectDetectorSearchMode.Single,
1.2f,
ObjectDetectorScalingMode.GreaterToSmaller
);
現在,我們需要準備資料,在本示例中,我們將使用膝上型電腦上的攝像頭捕獲所有影象。然而,Accord.NET framework 使得使用其他源進行資料採集變得很容易。例如 avi檔案,jpg檔案等等。
接下來,連線攝像頭,選擇解析度:
// 建立影片源
VideoCaptureDevice videoSource = new VideoCaptureDevice(form.VideoDevice);
// 設定幀的大小
videoSource.VideoResolution = selectResolution(videoSource);
///
///獲取幀的大小
/// /// 影片源
/// 幀的大小
private VideoCapabilities selectResolution(VideoCaptureDevice videoSource)
{
foreach (var cap in videoSource?.VideoCapabilities)
{
if (cap.FrameSize.Height == 240)
return cap;
if (cap.FrameSize.Width == 320)
return cap;
}
return videoSource?.VideoCapabilities.Last();
}
在這個演示中,你會註意到檢測物體正對著攝像機,在背景中,還有一些其他的東西,那就是所謂的隨機噪聲。這樣做是為了展示人臉檢測演演算法是如何區分出臉的。
如果我們的探測器不能處理這些,它就會在噪聲中消失,從而無法檢測到臉。
隨著影片源的加入,我們需要在接收到新的影片幀時得到通知,以便處理它、應用標記,等等。我們透過頻源播放器的NewFrameReceived事件來實現這一點。
在我們已經有了一個影片源和一個影片,讓我們看看每當我們被通知有一個新的影片幀可用時發生了什麼。
我們需要做的第一件事是對影象進行取樣,以使它更容易工作:
ResizeNearestNeighbor resize =
new ResizeNearestNeighbor(160, 120);
UnmanagedImage downsample = resize.Apply(im);
如果我們沒有找到一張臉,我們將保持跟蹤樣式,等待一個具有可檢測面部的幀。一旦我們找到了面部區域,我們需要重置跟蹤器,定位臉部,減小它的大小,以盡可能的剔除背景噪聲,然後初始化跟蹤器,並將在影象上進行標記。程式碼如下:
Rectangle[] regions = detector?.ProcessFrame(downsample);
if (regions != null && regions.Length > 0)
{
tracker?.Reset();
// 跟蹤第一張臉
Rectangle face = regions[0];
// 減小人臉檢測的大小,避免跟蹤背景上的其他內容
Rectangle window = new Rectangle(
(int)((regions[0].X + regions[0].Width / 2f) * xscale),
(int)((regions[0].Y + regions[0].Height / 2f) * yscale),
1,
1
);
window.Inflate((int)(0.2f * regions[0].Width * xscale), (int)(0.4f * regions[0].Height * yscale));
if (tracker != null)
{
tracker.SearchWindow = window;
tracker.ProcessFrame(im);
}
marker = new RectanglesMarker(window);
marker.ApplyInPlace(im);
eventArgs.Frame = im.ToManagedImage();
tracking = true;
}
else
{
detecting = true;
}
一旦檢測到臉,我們的影象幀是這樣的:

如果把頭偏向一邊,我們現在的形象應該是這樣的:

動態檢測
可以看到,在上一個例子中,我們不僅實現了面部檢測,還實現了動態檢測。現在,讓我們把目光轉向更大的範圍,檢測任何物體的運動,而不僅僅是面部。我們將繼續使用Accord.NET來實現。
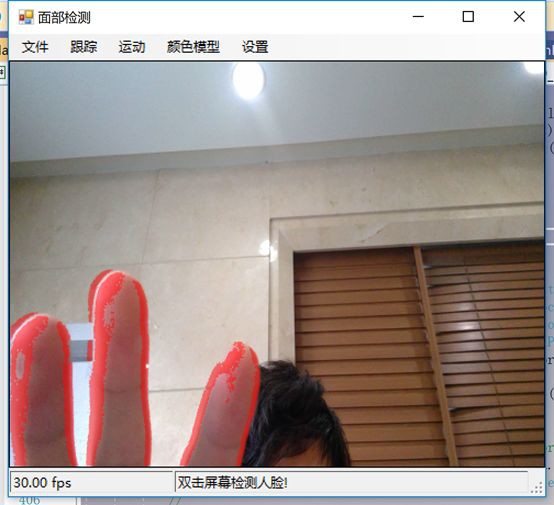
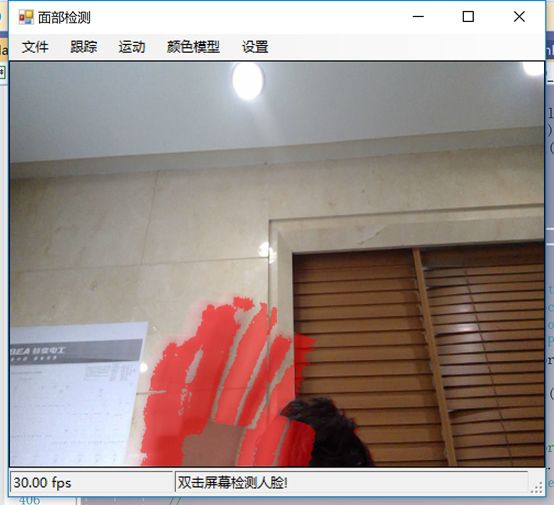
在動態檢測中,我們會用紅色高亮顯示螢幕上的任何運動。移動的數量由任何一個區域的紅色濃度表示。所以,如下圖所示,我們可以看到手指在移動但是其他的都是靜止的。
如下圖所示,可以看到整個手的移動範圍在增加。
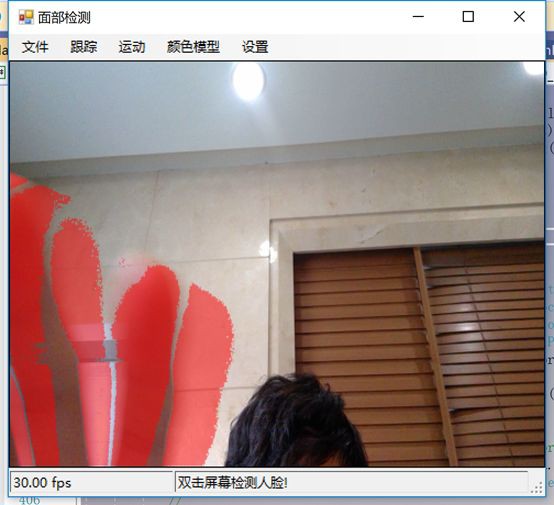
如下圖所示,一旦整隻手開始移動,你不僅可以看到更多的紅色,而且紅色的總量是在增加的:
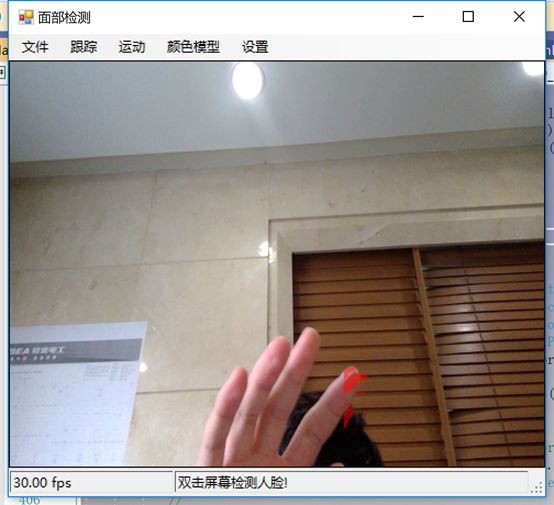
如果不希望對整個螢幕區域進行運動處理,可以自定義運動區域;運動檢測只會發生在這些區域。如下圖,可以看到我們已經定義了一個運動區域,這是唯一的一個區域。

現在,如果我們在攝像頭前面做一些運動,可以看到程式只檢測到了來自我們定義區域發生的運動。
現在,我們來做這樣一個測試,在我們自定義的檢測區域範圍內,放置一個物體,然後我們把手放在這個物體後面進行運動,當然手也是在這個自定義的檢測區域範圍內進行運動的。如下圖,可以看到,手的運動被檢測出來了。

現在我們使用另一個選項,網格運動突出顯示。它會使得檢測到的運動區域基於定義的網格在紅色方塊中突出顯示,如下圖所示。

將檢測新增到應用程式中
以下是處理接收到新的幀的程式碼:
private void videoSourcePlayer_NewFrame(object sender, NewFrameEventArgs args)
{
lock (this)
{
if (motionDetector != null)
{
float motionLevel = motionDetector.ProcessFrame(args.Frame);
if (motionLevel > motionAlarmLevel)
{
//快門速度2秒
flash = (int)(2 * (1000 / timer.Interval));
}
//檢查物件的數
if (motionDetector.MotionProcessingAlgorithm is BlobCountingObjectsProcessing)
{
BlobCountingObjectsProcessing countingDetector = (BlobCountingObjectsProcessing)motionDetector.MotionProcessingAlgorithm;
detectedObjectsCount = countingDetector.ObjectsCount;
}
else
{
detectedObjectsCount = -1;
}
// 積累的歷史
motionHistory.Add(motionLevel);
if (motionHistory.Count > 300)
{
motionHistory.RemoveAt(0);
}
if (顯示運動歷史ToolStripMenuItem.Checked)
DrawMotionHistory(args.Frame);
}
}
}
這裡的關鍵是檢測影片幀中發生的動量,這是透過以下程式碼完成的。對於本例,我們使用的是兩級的運動報警級別,但是你也可以使用任何你喜歡的級別定義。一旦超過這個閾值,就可以實現所需的邏輯,例如傳送電子郵件、開始影片捕獲等等。
float motionLevel = motionDetector.ProcessFrame(args.Frame);
if (motionLevel > motionAlarmLevel)
{
//快門速度2秒
flash = (int)(2 * (1000 / timer.Interval));
}總結
在這一章中,我們學習了面部和動態檢測,還展示了一些簡單易用的程式碼。我們可以輕鬆的將這些功能新增到自己的程式中。
●編號246,輸入編號直達本文
●輸入m獲取文章目錄

資料庫開發
更多推薦《25個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
