小編邀請您,先思考:
1 word2vec演演算法原理是什麼?
2 word2vec與doc2vec有什麼差異?
3 如何做word2vec和doc2vec?
深度學習掀開了機器學習的新篇章,目前深度學習應用於影象和語音已經產生了突破性的研究進展。深度學習一直被人們推崇為一種類似於人腦結構的人工智慧演演算法,那為什麼深度學習在語意分析領域仍然沒有實質性的進展呢?
取用三年前一位網友的話來講:
“Steve Renals算了一下icassp錄取文章題目中包含deep learning的數量,發現有44篇,而naacl則有0篇。有一種說法是,語言(詞、句子、篇章等)屬於人類認知過程中產生的高層認知抽象物體,而語音和影象屬於較為底層的原始輸入訊號,所以後兩者更適合做deep learning來學習特徵。”
實際上,就目前而言,Deep Learning 在 NLP 領域中的研究已經將高深莫測的人類語言撕開了一層神秘的面紗。其中最有趣也是最基本的,就是“詞向量”了。
1. 詞向量
自然語言理解的問題要轉化為機器學習的問題,第一步肯定是要找一種方法把這些符號數學化。
NLP 中最直觀,也是到目前為止最常用的詞表示方法是 One-hot Representation,這種方法把每個詞表示為一個很長的向量。這個向量的維度是詞表大小,其中絕大多數元素為 0,只有一個維度的值為 1,這個維度就代表了當前的詞。
舉個慄子,
“話筒”表示為 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麥克”表示為 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
每個詞都是茫茫 0 海中的一個 1。
這種 One-hot Representation 如果採用稀疏方式儲存,會是非常的簡潔:也就是給每個詞分配一個數字 ID。比如剛才的例子中,話筒記為 3,麥克記為 8(假設從 0 開始記)。如果要程式設計實現的話,用 Hash 表給每個詞分配一個編號就可以了。這麼簡潔的表示方法配合上最大熵、SVM、CRF 等等演演算法已經很好地完成了 NLP 領域的各種主流任務。
當然這種表示方法也存在一個重要的問題就是“詞彙鴻溝”現象:任意兩個詞之間都是孤立的。光從這兩個向量中看不出兩個詞是否有關係,哪怕是話筒和麥克這樣的同義詞也不能倖免於難。
2.Distributed representation詞向量表示
既然上述這種易於理解的One-hot Representation詞向量表示方式具有這樣的重要缺陷,那麼就需要一種既能表示詞本身又可以考慮語意距離的詞向量表示方法,這就是我們接下來要介紹的Distributed representation詞向量表示方法。
Distributed representation 最早由 Hinton在 1986 年提出。它是一種低維實數向量,這種向量一般長成這個樣子:
[0.792, −0.177, −0.107, 0.109, −0.542, …]
維度以 50 維和 100 維比較常見,當然了,這種向量的表示不是唯一的。
Distributed representation 最大的貢獻就是讓相關或者相似的詞,在距離上更接近了(看到這裡大家有沒有想到普通hash以及simhash的區別呢?有興趣的同學請見部落格《[Algorithm] 使用SimHash進行海量文字去重》)。向量的距離可以用最傳統的歐氏距離來衡量,也可以用 cos 夾角來衡量。用這種方式表示的向量,“麥克”和“話筒”的距離會遠遠小於“麥克”和“天氣”。可能理想情況下“麥克”和“話筒”的表示應該是完全一樣的,但是由於有些人會把英文名“邁克”也寫成“麥克”,導致“麥克”一詞帶上了一些人名的語意,因此不會和“話筒”完全一致。
將 word對映到一個新的空間中,並以多維的連續實數向量進行表示叫做“Word Represention” 或 “Word Embedding”。自從21世紀以來,人們逐漸從原始的詞向量稀疏表示法過渡到現在的低維空間中的密集表示。用稀疏表示法在解決實際問題時經常會遇到維數災難,並且語意資訊無法表示,無法揭示word之間的潛在聯絡。而採用低維空間表示法,不但解決了維數災難問題,並且挖掘了word之間的關聯屬性,從而提高了向量語意上的準確度。
3.詞向量模型
a) LSA矩陣分解模型
採用線性代數中的奇異值分解方法,選取前幾個比較大的奇異值所對應的特徵向量將原矩陣對映到低維空間中,從而達到詞向量的目的。
b) PLSA 潛在語意分析機率模型
從機率學的角度重新審視了矩陣分解模型,並得到一個從統計,機率角度上推匯出來的和LSA相當的詞向量模型。
c) LDA 檔案生成模型
按照檔案生成的過程,使用貝葉斯估計統計學方法,將檔案用多個主題來表示。LDA不只解決了同義詞的問題,還解決了一次多義的問題。目前訓練LDA模型的方法有原始論文中的基於EM和 差分貝葉斯方法以及後來出現的Gibbs Samplings 取樣演演算法。
d) Word2Vector 模型
最近幾年剛剛火起來的演演算法,透過神經網路機器學習演演算法來訓練N-gram 語言模型,併在訓練過程中求出word所對應的vector的方法。本文將詳細闡述此方法的原理。
4.word2vec演演算法思想
什麼是word2vec?你可以理解為word2vec就是將詞表徵為實數值向量的一種高效的演演算法模型,其利用深度學習的思想,可以透過訓練,把對文字內容的處理簡化為 K 維向量空間中的向量運算,而向量空間上的相似度可以用來表示文字語意上的相似。
Word2vec輸出的詞向量可以被用來做很多 NLP 相關的工作,比如聚類、找同義詞、詞性分析等等。如果換個思路, 把詞當做特徵,那麼Word2vec就可以把特徵對映到 K 維向量空間,可以為文字資料尋求更加深層次的特徵表示 。
Word2vec 使用的詞向量不是我們上述提到的One-hot Representation那種詞向量,而是 Distributed representation 的詞向量表示方式。其基本思想是 透過訓練將每個詞對映成 K 維實數向量(K 一般為模型中的超引數),透過詞之間的距離(比如 cosine 相似度、歐氏距離等)來判斷它們之間的語意相似度.其採用一個 三層的神經網路 ,輸入層-隱層-輸出層。有個核心的技術是 根據詞頻用Huffman編碼 ,使得所有詞頻相似的詞隱藏層啟用的內容基本一致,出現頻率越高的詞語,他們啟用的隱藏層數目越少,這樣有效的降低了計算的複雜度。而Word2vec大受歡迎的一個原因正是其高效性,Mikolov 在論文中指出,一個最佳化的單機版本一天可訓練上千億詞。
這個三層神經網路本身是 對語言模型進行建模 ,但也同時 獲得一種單詞在向量空間上的表示 ,而這個副作用才是Word2vec的真正標的。
與潛在語意分析(Latent Semantic Index, LSI)、潛在狄立克雷分配(Latent Dirichlet Allocation,LDA)的經典過程相比,Word2vec利用了詞的背景關係,語意資訊更加地豐富。
Word2Vec實際上是兩種不同的方法:Continuous Bag of Words (CBOW) 和 Skip-gram。CBOW的標的是根據背景關係來預測當前詞語的機率。Skip-gram剛好相反:根據當前詞語來預測背景關係的機率(如下圖所示)。這兩種方法都利用人工神經網路作為它們的分類演演算法。起初,每個單詞都是一個隨機 N 維向量。經過訓練之後,該演演算法利用 CBOW 或者 Skip-gram 的方法獲得了每個單詞的最優向量。

取一個適當大小的視窗當做語境,輸入層讀入視窗內的詞,將它們的向量(K維,初始隨機)加和在一起,形成隱藏層K個節點。輸出層是一個巨大的二叉 樹,葉節點代表語料裡所有的詞(語料含有V個獨立的詞,則二叉樹有|V|個葉節點)。而這整顆二叉樹構建的演演算法就是Huffman樹。這樣,對於葉節點的 每一個詞,就會有一個全域性唯一的編碼,形如”010011″,不妨記左子樹為1,右子樹為0。接下來,隱層的每一個節點都會跟二叉樹的內節點有連邊,於是 對於二叉樹的每一個內節點都會有K條連邊,每條邊上也會有權值。
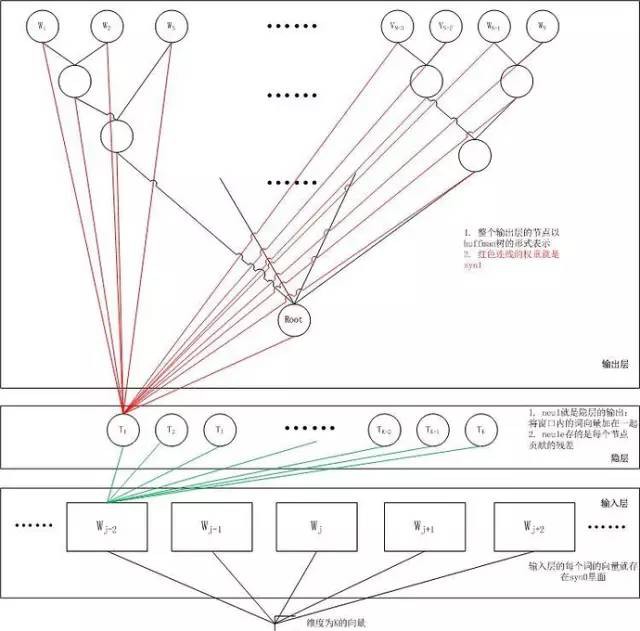
對於語料庫中的某個詞w_t,對應著二叉樹的某個葉子節點,因此它必然有一個二進位制編碼,如”010011″。在訓練階段,當給定背景關係,要預測後 面的詞w_t的時候,我們就從二叉樹的根節點開始遍歷,這裡的標的就是預測這個詞的二進位制編號的每一位。即對於給定的背景關係,我們的標的是使得預測詞的二 進位制編碼機率最大。形象地說,我們希望在根節點,詞向量和與根節點相連經過 logistic 計算得到 bit=1 的機率儘量接近 0,在第二層,希望其 bit=1 的機率儘量接近1,這麼一直下去,我們把一路上計算得到的機率相乘,即得到標的詞w_t在當前網路下的機率P(w_t),那麼對於當前這個 sample的殘差就是1-P(w_t),於是就可以使用梯度下降法訓練這個網路得到所有的引數值了。顯而易見,按照標的詞的二進位制編碼計算到最後的機率 值就是歸一化的。
Hierarchical Softmax用Huffman編碼構造二叉樹,其實藉助了分類問題中,使用一連串二分類近似多分類的思想。例如我們是把所有的詞都作為輸出,那麼“桔 子”、“汽車”都是混在一起。給定w_t的背景關係,先讓模型判斷w_t是不是名詞,再判斷是不是食物名,再判斷是不是水果,再判斷是不是“桔子”。
但是在訓練過程中,模型會賦予這些抽象的中間結點一個合適的向量,這個向量代表了它對應的所有子結點。因為真正的單詞公用了這些抽象結點的向量,所 以Hierarchical Softmax方法和原始問題並不是等價的,但是這種近似並不會顯著帶來效能上的損失同時又使得模型的求解規模顯著上升。
沒有使用這種二叉樹,而是直接從隱層直接計算每一個輸出的機率——即傳統的Softmax,就需要對|V|中的每一個詞都算一遍,這個過程時間複雜 度是O(|V|)的。而使用了二叉樹(如Word2vec中的Huffman樹),其時間複雜度就降到了O(log2(|V|)),速度大大地加快了。
現在這些詞向量已經捕捉到背景關係的資訊。我們可以利用基本代數公式來發現單詞之間的關係(比如,“國王”-“男人”+“女人”=“王后”)。這些詞向量可 以代替詞袋用來預測未知資料的情感狀況。該模型的優點在於不僅考慮了語境資訊還壓縮了資料規模(通常情況下,詞彙量規模大約在300個單詞左右而不是之前 模型的100000個單詞)。因為神經網路可以替我們提取出這些特徵的資訊,所以我們僅需要做很少的手動工作。但是由於文字的長度各異,我們可能需要利用 所有詞向量的平均值作為分類演演算法的輸入值,從而對整個文字檔案進行分類處理。
5.doc2vec演演算法思想
然而,即使上述模型對詞向量進行平均處理,我們仍然忽略了單詞之間的排列順序對情感分析的影響。即上述的word2vec只是基於詞的維度進行”語意分析”的,而並不具有背景關係的”語意分析”能力。
作為一個處理可變長度文字的總結性方法,Quoc Le 和 Tomas Mikolov 提出了 Doc2Vec方法。除了增加一個段落向量以外,這個方法幾乎等同於 Word2Vec。和 Word2Vec 一樣,該模型也存在兩種方法:Distributed Memory(DM) 和 Distributed Bag of Words(DBOW)。DM 試圖在給定背景關係和段落向量的情況下預測單詞的機率。在一個句子或者檔案的訓練過程中,段落 ID 保持不變,共享著同一個段落向量。DBOW 則在僅給定段落向量的情況下預測段落中一組隨機單詞的機率。
以下內容摘自語意分析的一些方法(中篇)
先看c-bow方法,相比於word2vec的c-bow模型,區別點有:
-
訓練過程中新增了paragraph id,即訓練語料中每個句子都有一個唯一的id。paragraph id和普通的word一樣,也是先對映成一個向量,即paragraph vector。paragraph vector與word vector的維數雖一樣,但是來自於兩個不同的向量空間。在之後的計算裡,paragraph vector和word vector累加或者連線起來,作為輸出層softmax的輸入。在一個句子或者檔案的訓練過程中,paragraph id保持不變,共享著同一個paragraph vector,相當於每次在預測單詞的機率時,都利用了整個句子的語意。
-
在預測階段,給待預測的句子新分配一個paragraph id,詞向量和輸出層softmax的引數保持訓練階段得到的引數不變,重新利用梯度下降訓練待預測的句子。待收斂後,即得到待預測句子的paragraph vector。

sentence2vec相比於word2vec的skip-gram模型,區別點為:在sentence2vec裡,輸入都是paragraph vector,輸出是該paragraph中隨機抽樣的詞。

下麵是sentence2vec的結果示例。先利用中文sentence語料訓練句向量,然後透過計算句向量之間的cosine值,得到最相似的句子。可以看到句向量在對句子的語意表徵上還是相當驚嘆的。

6.參考內容
1. word2vec官方地址:Word2Vec Homepage
2. python版本word2vec實現:gensim word2vec
3. python版本doc2vec實現:gensim doc2vec
4. 情感分析的新方法——基於Word2Vec/Doc2Vec/Python
5. 練數成金:語意分析的一些方法(中篇)
6. 王琳 Word2vec原理介紹
連結:http://www.cnblogs.com/maybe2030/p/5427148.html
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
好又樂書屋,專註分享有思想的人物,身心健康,自我教育,閱讀寫作和有趣味的生活等內容,傳播正能量。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
