小編邀請您,先思考:
1 資料預處理包括哪些內容?
2 如何有效完成資料預處理?
資料的質量和包含的有用資訊量是決定一個機器學習演演算法能夠學多好的關鍵因素。因此,我們在訓練模型前評估和預處理資料就顯得至關重要了。
資料預處理沒有統一的標準,只能說是根據不同型別的分析資料和業務需求,在對資料特性做了充分的理解之後,再選擇相關的資料預處理技術,一般會用到多種預處理技術,而且對每種處理之後的效果做些分析對比,這裡面經驗的成分比較大。
一. 為什麼要預處理資料
現實世界的資料總是或多或少存在各種各樣的問題,比如:
1)不完整的:有些感興趣的屬性缺少屬性值,或僅包含聚集資料
2)含噪聲的:包含錯誤或者“孤立點”
3)不一致的:在編碼或者命名上存在差異
沒有高質量的資料,就沒有高質量的挖掘結果。高質量的決策必須依賴高質量的資料,資料倉庫需要對高質量的資料進行一致的整合。
二. 資料預處理的主要任務
1)資料清理
填寫空缺的值,平滑噪聲資料,識別、刪除孤立點,解決不一致性
2)資料整合
整合多個資料庫、資料立方體或檔案
3)資料變換
規範化和聚集
4)資料歸約
得到資料集的壓縮表示,它小得多,但可以得到相同或相近的結果
5)資料離散化
資料歸約的一部分,透過概念分層和資料的離散化來規約資料,對數字型資料特別重要
三. 資料清洗
現實資料並不總是完整的,往往由於裝置異常,與原有資料不一致而被刪除,因誤解而沒有錄入的資料,對資料的改變沒有進行日誌記載等原因,導致資料存在空缺值。因此我們需要對缺失值進行處理,一般可以有以下方法:
a.忽略元組,即消除帶有確實值得特徵和樣本,當類標號缺少時通常這麼做
b.人工填寫缺失值:工作量太大,可行性太低
c.使用全域性變數填充空缺值,比如NaN、unknown等等
d.使用屬性的平均值填充空缺值
e.使用與給定元組屬於同一類的所有樣本的平均值
f.使用最可能的值填充,比如像貝葉斯,決策樹等這樣基於推斷的方法
四. 資料整合和變換
我們需要將多個資料源中的資料整合到一個一致的儲存中,因為對現實世界中的同一物體,來自不同資料源的屬性值,因不同的度量等原因可能是不同的。
有兩種方法能使不同的特徵有相同的取值範圍:歸一化和標準化
1)歸一化(normalization)
歸一化指的是將資料按比例縮放到[0,1],是最小-最大縮放的特例。當然我們也可以按照一定比例縮放使資料落入特定區間。
為了得到歸一化結果,我們對每一個特徵應用最小-最大縮放,如下:
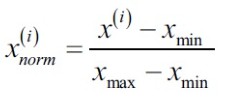
2)標準化(standardization)
相對來說,標準化對於大部分機器學習演演算法更實用。原因是大部分線性模型比如Logistic回歸和線性SVM在初始化權重引數時,要麼選擇0要麼選擇一個接近0的隨機數。使用標準化,我們能將特徵值縮放到以0為中心,標準差為1,即服從正態分佈,這樣更容易學習權重引數。
標準化公式如下:

五. 資料歸約和離散化
資料倉庫中往往存有海量資料,在其上進行複雜的資料分析與挖掘需要很長的時間。資料歸約可以用來得到資料集的歸約表示,它小得多,但可以產生相同的(或幾乎相同的)分析結果。而且用於資料歸約的時間不應當超過或“抵消”在歸約後的資料上挖掘節省的時間。
資料歸約策略
1)資料立方體聚集
最底層的方體對應於基本方體,基本方體對應於感興趣的物體。並且在資料立方體中存在著不同級別的彙總,每個較高層次的抽象將進一步減少結果資料。資料立方體提供了對預計算的彙總資料的快速訪問,在可能的情況下,對於彙總資料的查詢應當使用資料立方體。
2)維歸約
刪除不相干的屬性或維減少資料量。找出最小屬性集,使得資料類的機率分佈盡可能的接近使用所有屬性的原分佈,減少出現在發現樣式上的屬性的數目,使得樣式更易於理解。並且可以使用啟髮式方法來選擇或刪除相關的維。
3)資料壓縮
其中包含有失真壓縮和無失真壓縮。主要有字串壓縮和音影片壓縮。
4)數值歸約
透過選擇替代的、較小的資料表示形式來減少資料量。包含有參方法和無參方法。
有參方法代表:線性回歸,多元回歸,對數線性模型等
無參方法代表:直方圖,聚類,選樣等
5)離散化和概念分層
離散化:透過將屬性域劃分為區間,減少給定連續屬性值的個數。區間的標號可以代替實際的資料值。
概念分層:透過使用高層的概念(比如:少年、青年、中年、老年)來替代底層的屬性值(比如:實際的年齡資料值)來規約資料。
資料數值的離散化和概念分層生成一般存在以下方法:
a.分箱(binning)
分箱技術遞迴地用於結果劃分,可以產生概念分層。
b.直方圖分析(histogram)
直方圖分析方法遞迴地應用於每一部分,可以自動產生多級概念分層。
c.聚類分析
將資料劃分成簇,每個簇形成同一個概念層上的一個節點,每個簇可再分成多個子簇,形成子節點。
d.基於熵的離散化
e.透過自然劃分分段
六. 小結
本文我們簡單介紹了資料挖掘中資料預處理的相關內容,只能說是淺嘗輒止吧,期待更深入的研究。
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
好又樂書屋,專註分享有思想的人物,身心健康,自我教育,閱讀寫作和有趣味的生活等內容,傳播正能量。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
