作為這個系列的第一篇,我先來描述一下slab系統。因為近些天有和同事,朋友討論過這個主題,而且覺得這個主題還算比較典型,所以就作為第一篇了。其實按照作業系統理論來講,行程管理應該更加重要些,按照我自己的興趣來講,IO管理以及TCP/IP協議棧會更加有分量,關於這些內容,我會陸續給出。
Linux內核的slab來自一種很簡單的思想,即事先準備好一些會頻繁分配,釋放的資料結構。然而標準的slab實現太複雜且維護開銷巨大,因此便分化出了更加小巧的slub,因此本文討論的就是slub,後面所有提到slab的地方,指的都是slub。另外又由於本文主要描述核心最佳化方面的內容,並不是基本原理介紹,因此想瞭解slab細節以及程式碼實現的請自行百度或者看原始碼。
單CPU上單純的slab
下圖給出了單CPU上slab在分配和釋放物件時的情景序列:
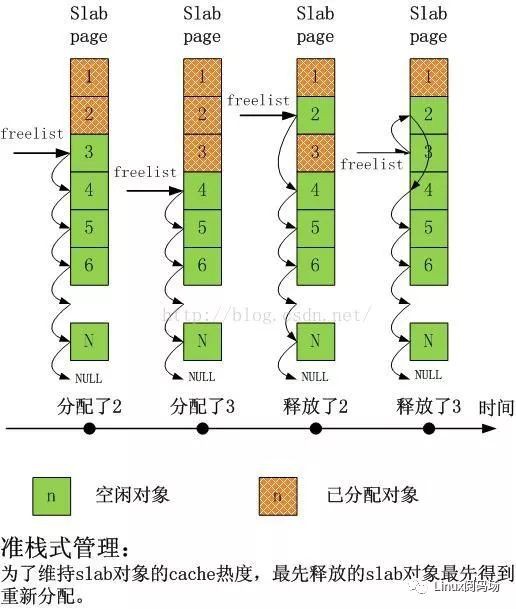
可以看出,非常之簡單,而且完全達到了slab設計之初的標的。
擴充套件到多核心CPU
現在我們簡單的將上面的模型擴充套件到多核心CPU,同樣差不多的分配序列如下圖所示:
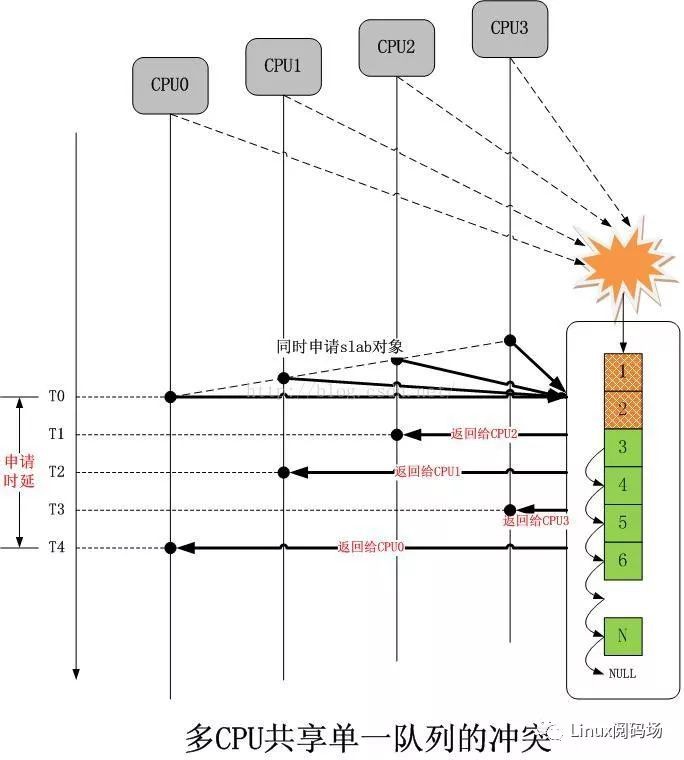
我們看到,在只有單一slab的時候,如果多個CPU同時分配物件,衝突是不可避免的,解決衝突的幾乎是唯一的辦法就是加鎖排隊,然而這將大大增加延遲,我們看到,申請單一物件的整個時延從T0開始,到T4結束,這太久了。
多CPU無鎖化並行化操作的直接思路-複製給每個CPU一套相同的資料結構。
不二法門就是增加“每CPU變數”。對於slab而言,可以擴充套件成下麵的樣子:
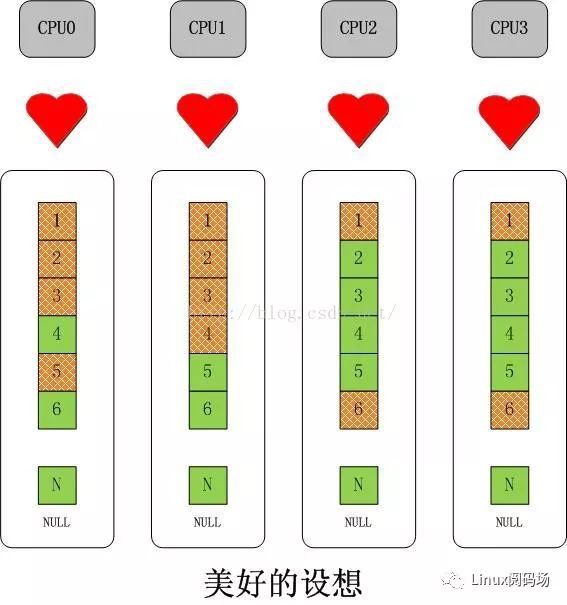
如果以為這麼簡單就結束了,那這就太沒有意義了。
問題
首先,我們來看一個簡單的問題,如果單獨的某個CPU的slab快取沒有物件可分配了,但是其它CPU的slab快取仍有大量空閑物件的情況,如下圖所示:
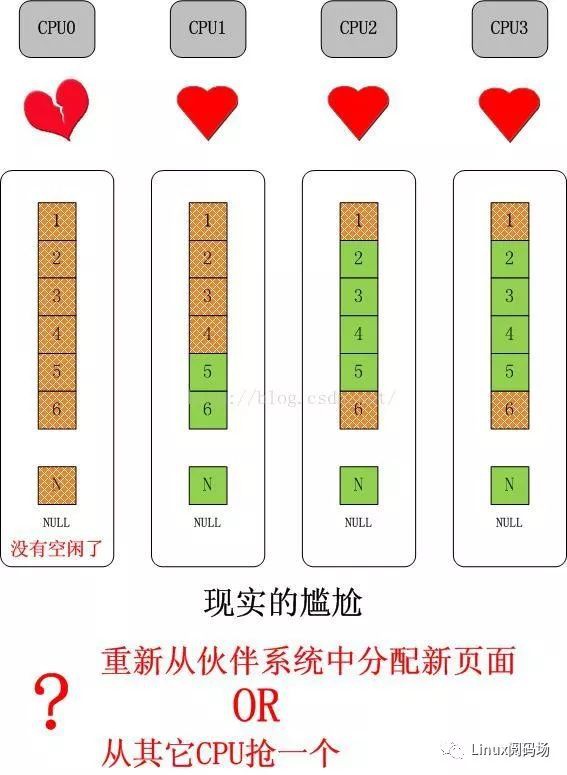
這是可能的,因為對單獨一種slab的需求是和該CPU上執行的行程/執行緒緊密相關的,比如如果CPU0只處理網路,那麼它就會對skb等資料結構有大量的需求,對於上圖最後引出的問題,如果我們選擇從夥伴系統中分配一個新的page(或者pages,取決於物件大小以及slab cache的order),那麼久而久之就會造成slab在CPU間分佈的不均衡,更可能會因此吃掉大量的物理記憶體,這都是不希望看到的。
在繼續之前,首先要明確的是,我們需要在CPU間均衡slab,並且這些必須靠slab內部的機制自行完成,這個和行程在CPU間負載均衡是完全不同的,對行程而言,擁有一個核心排程機制,比如基於時間片,或者虛擬時鐘的步進速率等,但是對於slab,完全取決於使用者自身,只要物件仍然在使用,就不能剝奪使用者繼續使用的權利,除非使用者自己釋放。因此slab的負載均衡必須設計成合作型的,而不是搶佔式的。
好了。現在我們知道,從夥伴系統重新分配一個page(s)並不是一個好主意,它應該是最終的決定,在執行它之前,首先要試一下別的路線。
現在,我們引出第二個問題,如下圖所示:
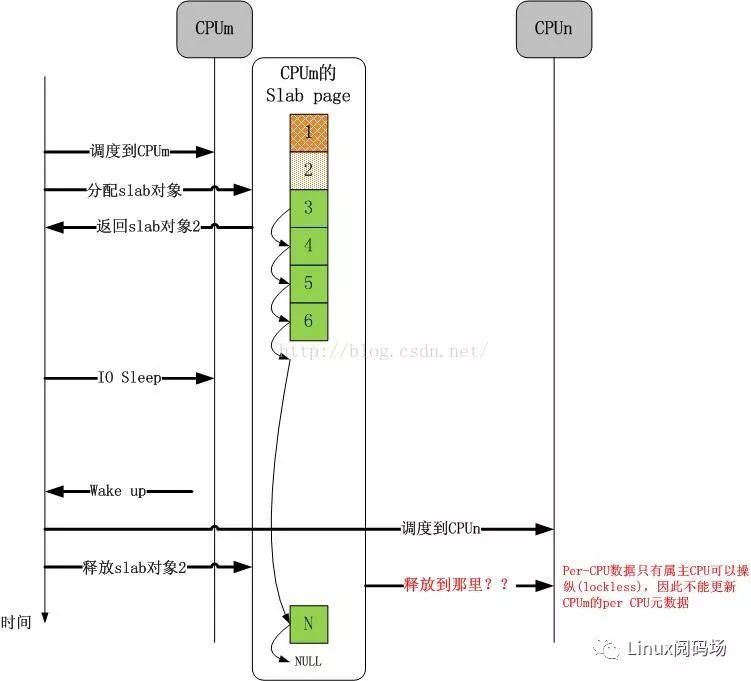
誰也不能保證分配slab物件的CPU和釋放slab物件的CPU是同一個CPU,誰也不能保證一個CPU在一個slab物件的生命週期內沒有分配新的page(s),這期間的複雜操作誰也沒有規定。這些問題該怎麼解決呢?事實上,理解了這些問題是怎麼解決的,一個slab框架就徹底理解了。
問題的解決-分層slab cache
無級變速總是讓人嚮往。
如果一個CPU的slab快取滿了,直接去搶同級別的別的CPU的slab快取被認為是一種魯莽且不道義的做法。那麼為何不設定另外一個slab快取,獲取它裡面的物件不像直接獲取CPU的slab快取那麼簡單且直接,但是難度卻又不大,只是稍微增加一點消耗,這不是很好嗎?事實上,CPU的L1,L2,L3 cache不就是這個方案設計的嗎?這事實上已經成為cache設計的不二法門。這個設計思想同樣作用於slab,就是Linux內核的slub實現。
現在可以給出概念和解釋了。
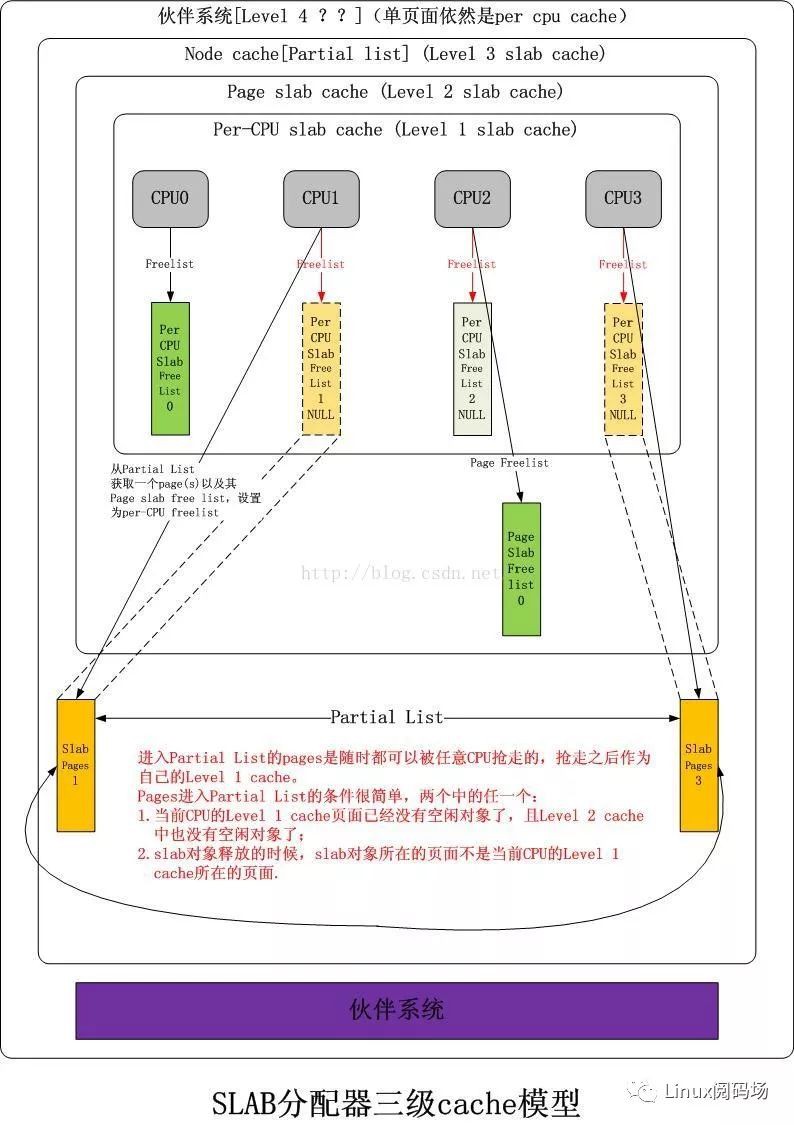
Linux kernel slab cache:一個分為3層的物件cache模型。
Level 1 slab cache:一個空閑物件連結串列,每個CPU一個的獨享cache,分配釋放物件無需加鎖。
Level 2 slab cache:一個空閑物件連結串列,每個CPU一個的共享page(s) cache,分配釋放物件時僅需要鎖住該page(s),與Level 1 slab cache互斥,不互相包容。
Level 3 slab cache:一個page(s)連結串列,每個NUMA NODE的所有CPU共享的cache,單位為page(s),獲取後被提升到對應CPU的Level 1 slab cache,同時該page(s)作為Level 2的共享page(s)存在。
共享page(s):該page(s)被一個或者多個CPU佔有,每一個CPU在該page(s)上都可以擁有互相不充圖的空閑物件連結串列,該page(s)擁有一個唯一的Level 2 slab cache空閑連結串列,該連結串列與上述一個或多個Level 1 slab cache空閑連結串列亦不衝突,多個CPU獲取該Level 2 slab cache時必須爭搶,獲取後可以將該連結串列提升成自己的Level 1 slab cache。
該slab cache的圖示如下:
其行為如下圖所示:

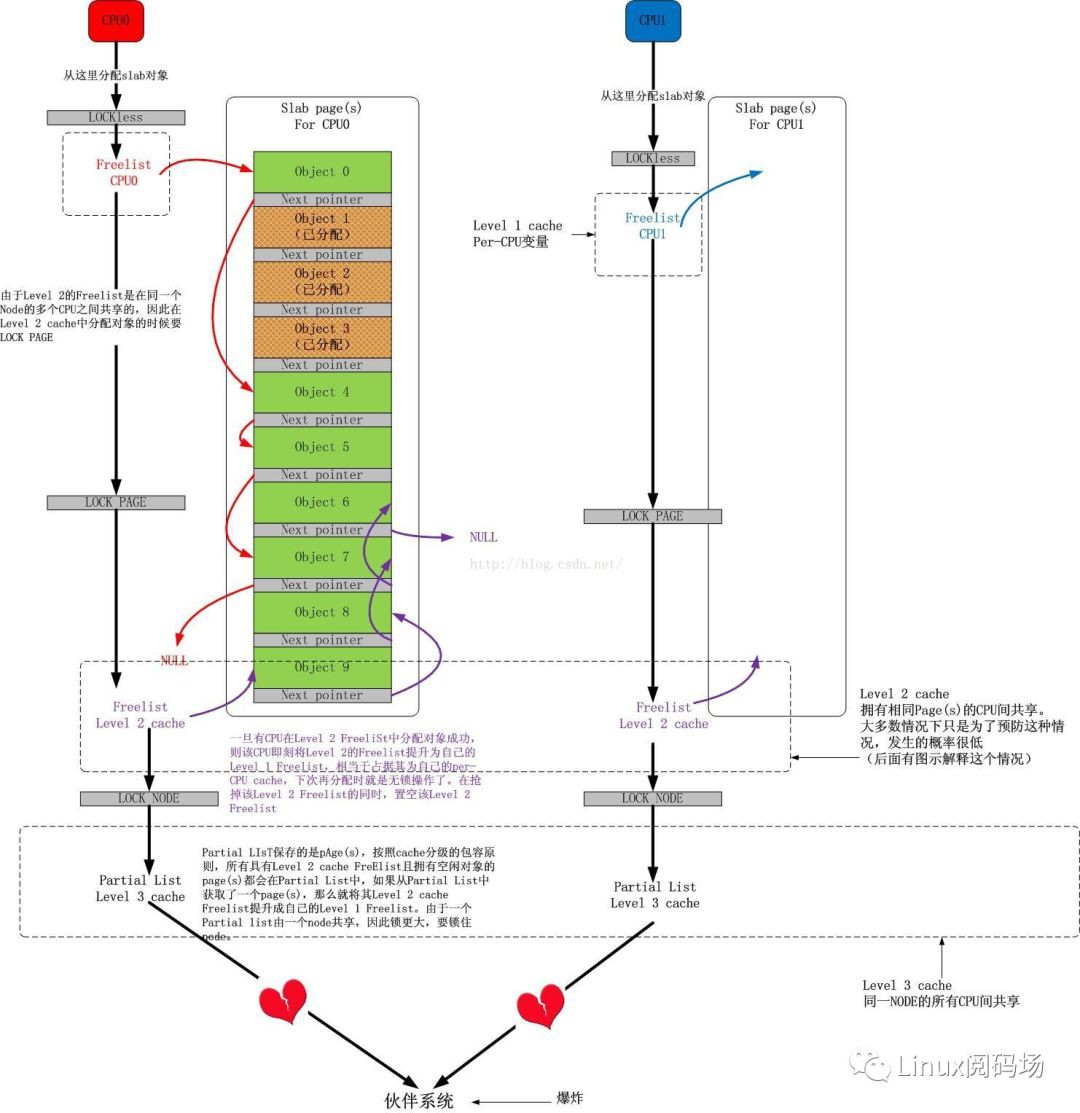
2個場景
對於常規的物件分配過程,下圖展示了其細節:
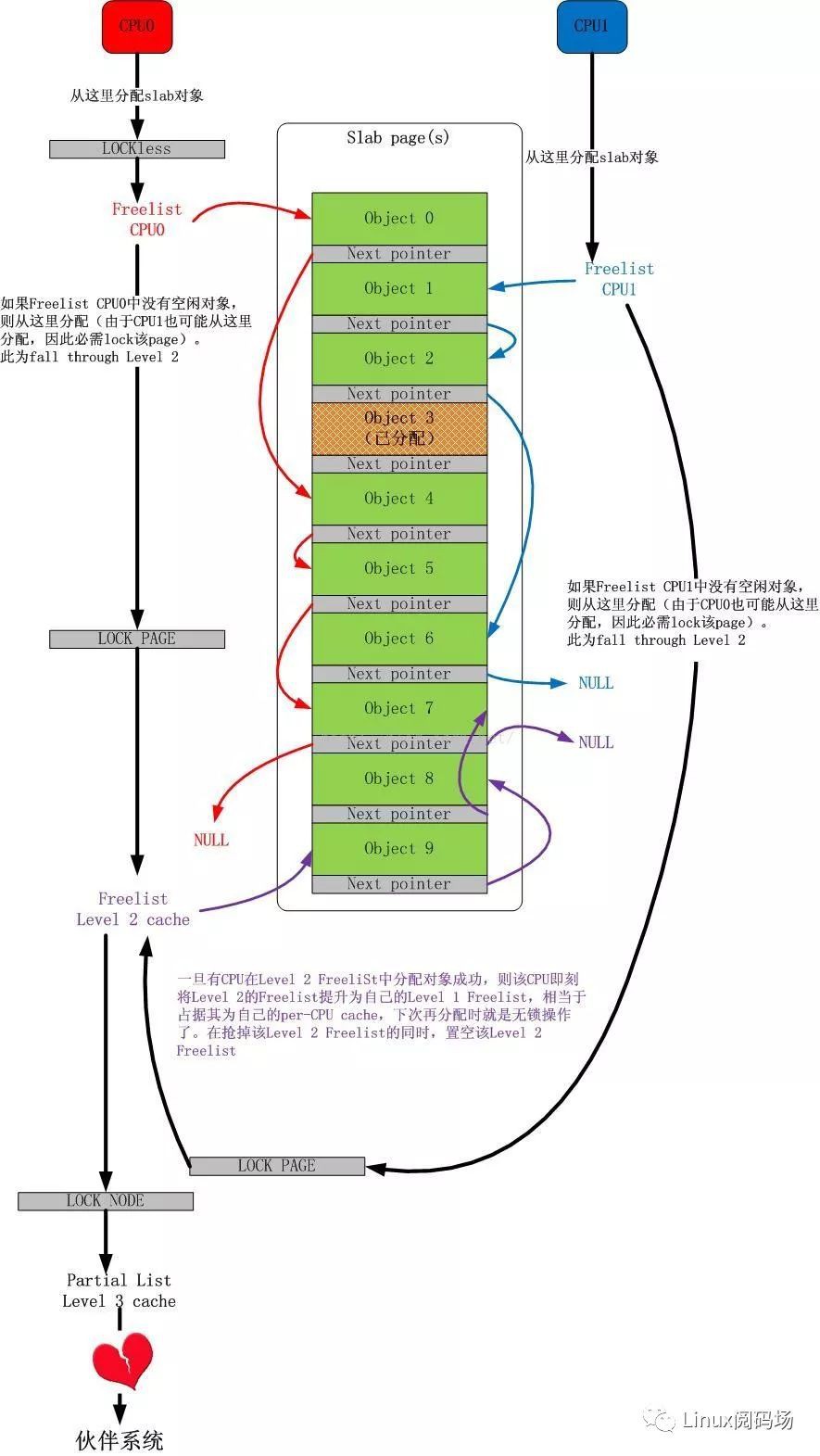
事實上,對於多個CPU共享一個page(s)的情況,還可以有另一種玩法,如下圖所示:
夥伴系統
前面我們簡短的體會了Linux內核的slab設計,不宜過長,太長了不易理解.但是最後,如果Level 3也沒有獲取page(s),那麼最終會落到終極的夥伴系統。
夥伴系統是為了防記憶體分配碎片化的,所以它盡可能地做兩件事:
1).儘量分配盡可能大的記憶體
2).儘量合併連續的小塊記憶體成一塊大記憶體
我們可以透過下麵的圖解來理解上面的原則:
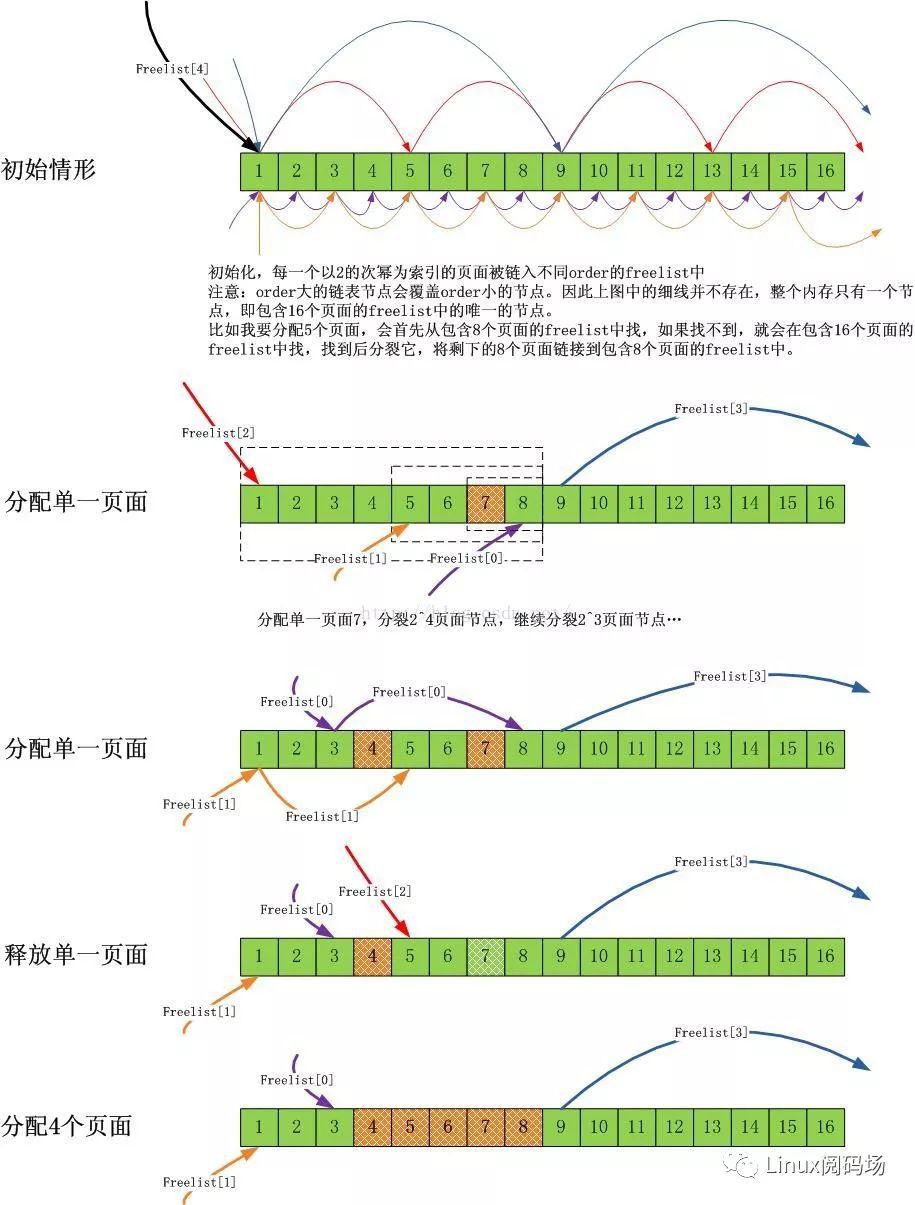
註意,本文是關於最佳化的,不是夥伴系統的科普,所以我假設大家已經理解了夥伴系統。
鑒於slab快取物件大多數都是不超過1個頁面的小結構(不僅僅slab系統,超過1個頁面的記憶體需求相比1個頁面的記憶體需求,很少),因此會有大量的針對1個頁面的記憶體分配需求。從夥伴系統的分配原理可知,如果持續大量分配單一頁面,會有大量的order大於0的頁面分裂成單一頁面,在單核心CPU上,這不是問題,但是在多核心CPU上,由於每一個CPU都會進行此類分配,而夥伴系統的分裂,合併操作會涉及大量的連結串列操作,這個鎖開銷是巨大的,因此需要最佳化!
Linux核心對夥伴系統針對單一頁面的分配需求採取的批次分配“每CPU單一頁面快取”的方式!
每一個CPU擁有一個單一頁面快取池,需要單一頁面的時候,可以無需加鎖從當前CPU對應的頁面池中獲取頁面。而當池中頁面不足時,系統會批次從夥伴系統中拉取一堆頁面到池中,反過來,在單一頁面釋放的時候,會擇優將其釋放到每CPU的單一頁面快取中。
為了維持“每CPU單一頁面快取”中頁面的數量不會太多或太少(太多會影響夥伴系統,太少會影響CPU的需求),系統保持了兩個值,當快取頁面數量低於low值的時候,便從夥伴系統中批次獲取頁面到池中,而當快取頁面數量大於high的時候,便會釋放一些頁面到夥伴系統中。
小結
多CPU作業系統核心中,關鍵的開銷就是鎖的開銷。我認為這是一開始的設計導致的,因為一開始,多核CPU並沒有出現,單核CPU上的共享保護幾乎都是可以用“禁中斷”,“禁搶佔”來簡單實現的,到了多核時代,作業系統同樣簡單平移到了新的平臺,因此同步操作是在單核的基礎上後來新增的。簡單來講,目前的主流作業系統都是在單核年代創造出來的,因此它們都是順應單核環境的,對於多核環境,可能它們一開始的設計就有問題。
不管怎麼說,最佳化操作的不二法門就是禁止或者儘量減少鎖的操作。隨之而來的思路就是為共享的關鍵資料結構建立”每CPU的快取“,而這類快取分為兩種型別:
1).資料通路快取。
比如路由表之類的資料結構,你可以用RCU鎖來保護,當然如果為每一個CPU都建立一個本地路由錶快取,也是不錯的,現在的問題是何時更新它們,因為所有的快取都是平級的,因此一種批次同步的機制是必須的。
2).管理機制快取。
比如slab物件快取這類,其生命週期完全取決於使用者,因此不存在同步問題,然而卻存在管理問題。採用分級cache的思想是好的,這個非常類似於CPU的L1/L2/L3快取,採用這種平滑的開銷逐漸增大,容量逐漸增大的機制,並配合以設計良好的換入/換出等演演算法,效果是非常明顯的。

