小編邀請您,先思考:
1 有哪些演演算法可以聚類?各自有什麼特點?
2 聚類演演算法的效果如何評價?
1 定義
聚類是資料挖掘中的概念,就是按照某個特定標準(如距離)把一個資料集分割成不同的類或簇,使得同一個簇內的資料物件的相似性盡可能大,同時不在同一個簇中的資料物件的差異性也盡可能地大。也即聚類後同一類的資料盡可能聚集到一起,不同類資料儘量分離。
2 聚類過程
-
資料準備:包括特徵標準化和降維;
-
特徵選擇:從最初的特徵中選擇最有效的特徵,並將其儲存於向量中;
-
特徵提取:透過對所選擇的特徵進行轉換形成新的突出特徵;
-
聚類(或分組):首先選擇合適特徵型別的某種距離函式(或構造新的距離函式)進行接近程度的度量,而後執行聚類或分組;
-
聚類結果評估:是指對聚類結果進行評估,評估主要有3種:外部有效性評估、內部有效性評估和相關性測試評估。
3. 聚類方法的分類
主要分為層次化聚類演演算法,劃分式聚類演演算法,基於密度的聚類演演算法,基於網格的聚類演演算法,基於模型的聚類演演算法等。
3.1 層次化聚類演演算法
又稱樹聚類演演算法,透過一種層次架構方式,反覆將資料進行分裂或聚合。典型的有BIRCH演演算法,CURE演演算法,CHAMELEON演演算法,Sequence data rough clustering演演算法,Between groups average演演算法,Furthest neighbor演演算法,Neares neighbor演演算法等。
典型凝聚型層次聚類:
先將每個物件作為一個簇,然後合併這些原子簇為越來越大的簇,直到所有物件都在一個簇中,或者某個終結條件被滿足。
演演算法流程:
-
將每個物件看作一類,計算兩兩之間的最小距離;
-
將距離最小的兩個類合併成一個新類;
-
重新計算新類與所有類之間的距離;
-
重覆1、2,直到所有類最後合併成一類。
3.2 劃分式聚類演演算法
預先指定聚類數目或聚類中心,反覆迭代逐步降低標的函式誤差值直至收斂,得到最終結果。K-means,K-modes-Huang,K-means-CP,MDS_CLUSTER, Feature weighted fuzzy clustering,CLARANS等
經典K-means演演算法流程:
-
隨機地選擇k個物件,每個物件初始地代表了一個簇的中心;
-
對剩餘的每個物件,根據其與各簇中心的距離,將它賦給最近的簇;
-
重新計算每個簇的平均值,更新為新的簇中心;
-
不斷重覆2、3,直到準則函式收斂。
3.3 基於模型的聚類演演算法
為每簇假定了一個模型,尋找資料對給定模型的最佳擬合,同一”類“的資料屬於同一種機率分佈,即假設資料是根據潛在的機率分佈生成的。主要有基於統計學模型的方法和基於神經網路模型的方法,尤其以基於機率模型的方法居多。一個基於模型的演演算法可能透過構建反應資料點空間分佈的密度函式來定位聚類。基於模型的聚類試圖最佳化給定的資料和某些資料模型之間的適應性。
SOM神經網路演演算法:
該演演算法假設在輸入物件中存在一些拓撲結構或順序,可以實現從輸入空間(n維)到輸出平面(2維)的降維對映,其對映具有拓撲特徵保持性質,與實際的大腦處理有很強的理論聯絡。
SOM網路包含輸入層和輸出層。輸入層對應一個高維的輸入向量,輸出層由一系列組織在2維網格上的有序節點構成,輸入節點與輸出節點透過權重向量連線。學習過程中,找到與之距離最短的輸出層單元,即獲勝單元,對其更新。同時,將鄰近區域的權值更新,使輸出節點保持輸入向量的拓撲特徵。
演演算法流程:
-
網路初始化,對輸出層每個節點權重賦初值;
-
將輸入樣本中隨機選取輸入向量,找到與輸入向量距離最小的權重向量;
-
定義獲勝單元,在獲勝單元的鄰近區域調整權重使其向輸入向量靠攏;
-
提供新樣本、進行訓練;
-
收縮鄰域半徑、減小學習率、重覆,直到小於允許值,輸出聚類結果。
3.4 基於密度聚類演演算法
主要思想:
只要鄰近區域的密度(物件或資料點的數目)超過某個閾值,就繼續聚類
擅於解決不規則形狀的聚類問題,廣泛應用於空間資訊處理,SGC,GCHL,DBSCAN演演算法、OPTICS演演算法、DENCLUE演演算法。
DBSCAN:
對於集中區域效果較好,為了發現任意形狀的簇,這類方法將簇看做是資料空間中被低密度區域分割開的稠密物件區域;一種基於高密度連通區域的基於密度的聚類方法,該演演算法將具有足夠高密度的區域劃分為簇,併在具有噪聲的空間資料中發現任意形狀的簇。
3.5 基於網格的聚類演演算法
基於網格的方法把物件空間量化為有限數目的單元,形成一個網格結構。所有的聚類操作都在這個網格結構(即量化空間)上進行。這種方法的主要優點是它的處理 速度很快,其處理速度獨立於資料物件的數目,只與量化空間中每一維的單元數目有關。但這種演演算法效率的提高是以聚類結果的精確性為代價的。經常與基於密度的演演算法結合使用。
代表演演算法有STING演演算法、CLIQUE演演算法、WAVE-CLUSTER演演算法等。
3.6 新發展的方法
基於約束的方法:
真實世界中的聚類問題往往是具備多種約束條件的 , 然而由於在處理過程中不能準確表達相應的約束條件、不能很好地利用約束知識進行推理以及不能有效利用動態的約束條件 , 使得這一方法無法得到廣泛的推廣和應用。這裡的約束可以是對個體物件的約束 , 也可以是對聚類引數的約束 , 它們均來自相關領域的經驗知識。該方法的一個重要應用在於對存在障礙資料的二維空間資料進行聚類。 COD (Clustering with Ob2structed Distance) 就是處理這類問題的典型演演算法 , 其主要思想是用兩點之間的障礙距離取代了一般的歐氏距離來計算其間的最小距離。
基於模糊的聚類方法:
基於模糊集理論的聚類方法,樣本以一定的機率屬於某個類。比較典型的有基於標的函式的模糊聚類方法、基於相似性關係和模糊關係的方法、基於模糊等價關係的傳遞閉包方法、基於模 糊圖論的最小支撐樹方法,以及基於資料集的凸分解、動態規劃和難以辨別關係等方法。
FCM模糊聚類演演算法流程:
-
標準化資料矩陣;
-
建立模糊相似矩陣,初始化隸屬矩陣;
-
演演算法開始迭代,直到標的函式收斂到極小值;
-
根據迭代結果,由最後的隸屬矩陣確定資料所屬的類,顯示最後的聚類結果。
基於粒度的聚類方法:
基於粒度原理,研究還不完善。
量子聚類:
受物理學中量子機理和特性啟發,可以用量子理論解決聚類記過依賴於初值和需要指定類別數的問題。一個很好的例子就是基於相關點的 Pott 自旋和統計機理提出的量子聚類模型。它把聚類問題看做一個物理系統。並且許多算例表明,對於傳統聚類演演算法無能為力的幾種聚類問題,該演演算法都得到了比較滿意的結果。
核聚類:
核聚類方法增加了對樣本特徵的最佳化過程,利用 Mercer 核 把輸入空間的樣本對映到高維特徵空間,併在特徵空間中進行聚類。核聚類方法是普適的,併在效能上優於經典的聚類演演算法,它透過非線性對映能夠較好地分辨、提 取並放大有用的特徵,從而實現更為準確的聚類;同時,演演算法的收斂速度也較快。在經典聚類演演算法失效的情況下,核聚類演演算法仍能夠得到正確的聚類。代表演演算法有SVDD演演算法,SVC演演算法。
譜聚類:
首先根據給定的樣本資料集定義一個描述成對資料點相似度的親合矩陣,並計算矩陣的特徵值和特徵向量,然後選擇合適的特徵向量聚類不同的資料點。譜聚類演演算法最初用於計算機視覺、VLSI設計等領域,最近才開始用於機器學習中,並迅速成為國際上機器學習領域的研究熱點。
譜聚類演演算法建立在圖論中的譜圖理論基礎上,其本質是將聚類問題轉化為圖的最優劃分問題,是一種點對聚類演演算法。
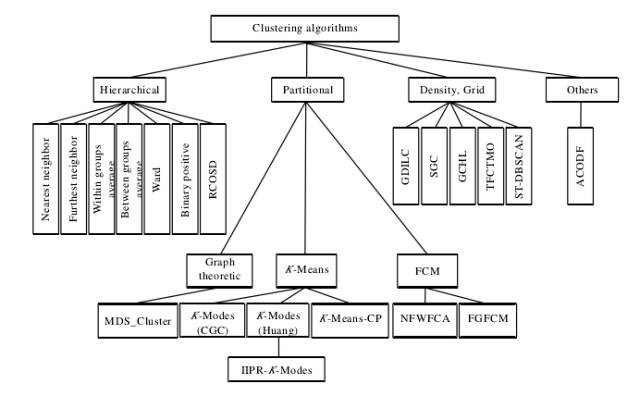
聚類演演算法簡要分類架構圖
常用演演算法特點對比表
▼

親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

好又樂書屋,專註分享有思想的人物,身心健康,自我教育,閱讀寫作和有趣味的生活等內容,傳播正能量。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
