(點選上方公眾號,可快速關註)
來源:程式設計迷思
www.cnblogs.com/kismetv/p/8654978.html
前言
Redis是目前最火爆的記憶體資料庫之一,透過在記憶體中讀寫資料,大大提高了讀寫速度,可以說Redis是實現網站高併發不可或缺的一部分。
我們使用Redis時,會接觸Redis的5種物件型別(字串、雜湊、串列、集合、有序集合),豐富的型別是Redis相對於Memcached等的一大優勢。在瞭解Redis的5種物件型別的用法和特點的基礎上,進一步瞭解Redis的記憶體模型,對Redis的使用有很大幫助,例如:
1、估算Redis記憶體使用量。目前為止,記憶體的使用成本仍然相對較高,使用記憶體不能無所顧忌;根據需求合理的評估Redis的記憶體使用量,選擇合適的機器配置,可以在滿足需求的情況下節約成本。
2、最佳化記憶體佔用。瞭解Redis記憶體模型可以選擇更合適的資料型別和編碼,更好的利用Redis記憶體。
3、分析解決問題。當Redis出現阻塞、記憶體佔用等問題時,儘快發現導致問題的原因,便於分析解決問題。
這篇文章主要介紹Redis的記憶體模型(以3.0為例),包括Redis佔用記憶體的情況及如何查詢、不同的物件型別在記憶體中的編碼方式、記憶體分配器(jemalloc)、簡單動態字串(SDS)、RedisObject等;然後在此基礎上介紹幾個Redis記憶體模型的應用。
在後面的文章中,會陸續介紹關於Redis高可用的內容,包括主從複製、哨兵、叢集等等,歡迎關註。
一、Redis記憶體統計
工欲善其事必先利其器,在說明Redis記憶體之前首先說明如何統計Redis使用記憶體的情況。
在客戶端透過redis-cli連線伺服器後(後面如無特殊說明,客戶端一律使用redis-cli),透過info命令可以檢視記憶體使用情況:
info memory

其中,info命令可以顯示redis伺服器的許多資訊,包括伺服器基本資訊、CPU、記憶體、持久化、客戶端連線資訊等等;memory是引數,表示只顯示記憶體相關的資訊。
傳回結果中比較重要的幾個說明如下:
(1)used_memory:Redis分配器分配的記憶體總量(單位是位元組),包括使用的虛擬記憶體(即swap);Redis分配器後面會介紹。used_memory_human只是顯示更友好。
(2)used_memory_rss:Redis行程佔據作業系統的記憶體(單位是位元組),與top及ps命令看到的值是一致的;除了分配器分配的記憶體之外,used_memory_rss還包括行程執行本身需要的記憶體、記憶體碎片等,但是不包括虛擬記憶體。
因此,used_memory和used_memory_rss,前者是從Redis角度得到的量,後者是從作業系統角度得到的量。二者之所以有所不同,一方面是因為記憶體碎片和Redis行程執行需要佔用記憶體,使得前者可能比後者小,另一方面虛擬記憶體的存在,使得前者可能比後者大。
由於在實際應用中,Redis的資料量會比較大,此時行程執行佔用的記憶體與Redis資料量和記憶體碎片相比,都會小得多;因此used_memory_rss和used_memory的比例,便成了衡量Redis記憶體碎片率的引數;這個引數就是mem_fragmentation_ratio。
(3)mem_fragmentation_ratio:記憶體碎片比率,該值是used_memory_rss / used_memory的比值。
mem_fragmentation_ratio一般大於1,且該值越大,記憶體碎片比例越大。mem_fragmentation_ratio<1,說明Redis使用了虛擬記憶體,由於虛擬記憶體的媒介是磁碟,比記憶體速度要慢很多,當這種情況出現時,應該及時排查,如果記憶體不足應該及時處理,如增加Redis節點、增加Redis伺服器的記憶體、最佳化應用等。
一般來說,mem_fragmentation_ratio在1.03左右是比較健康的狀態(對於jemalloc來說);上面截圖中的mem_fragmentation_ratio值很大,是因為還沒有向Redis中存入資料,Redis行程本身執行的記憶體使得used_memory_rss 比used_memory大得多。
(4)mem_allocator:Redis使用的記憶體分配器,在編譯時指定;可以是 libc 、jemalloc或者tcmalloc,預設是jemalloc;截圖中使用的便是預設的jemalloc。
二、Redis記憶體劃分
Redis作為記憶體資料庫,在記憶體中儲存的內容主要是資料(鍵值對);透過前面的敘述可以知道,除了資料以外,Redis的其他部分也會佔用記憶體。
Redis的記憶體佔用主要可以劃分為以下幾個部分:
1、資料
作為資料庫,資料是最主要的部分;這部分佔用的記憶體會統計在used_memory中。
Redis使用鍵值對儲存資料,其中的值(物件)包括5種型別,即字串、雜湊、串列、集合、有序集合。這5種型別是Redis對外提供的,實際上,在Redis內部,每種型別可能有2種或更多的內部編碼實現;此外,Redis在儲存物件時,並不是直接將資料扔進記憶體,而是會對物件進行各種包裝:如redisObject、SDS等;這篇文章後面將重點介紹Redis中資料儲存的細節。
2、行程本身執行需要的記憶體
Redis主行程本身執行肯定需要佔用記憶體,如程式碼、常量池等等;這部分記憶體大約幾兆,在大多數生產環境中與Redis資料佔用的記憶體相比可以忽略。這部分記憶體不是由jemalloc分配,因此不會統計在used_memory中。
補充說明:除了主行程外,Redis建立的子行程執行也會佔用記憶體,如Redis執行AOF、RDB重寫時建立的子行程。當然,這部分記憶體不屬於Redis行程,也不會統計在used_memory和used_memory_rss中。
3、緩衝記憶體
緩衝記憶體包括客戶端緩衝區、複製積壓緩衝區、AOF緩衝區等;其中,客戶端緩衝儲存客戶端連線的輸入輸出緩衝;複製積壓緩衝用於部分複製功能;AOF緩衝區用於在進行AOF重寫時,儲存最近的寫入命令。在瞭解相應功能之前,不需要知道這些緩衝的細節;這部分記憶體由jemalloc分配,因此會統計在used_memory中。
4、記憶體碎片
記憶體碎片是Redis在分配、回收物理記憶體過程中產生的。例如,如果對資料的更改頻繁,而且資料之間的大小相差很大,可能導致redis釋放的空間在物理記憶體中並沒有釋放,但redis又無法有效利用,這就形成了記憶體碎片。記憶體碎片不會統計在used_memory中。
記憶體碎片的產生與對資料進行的操作、資料的特點等都有關;此外,與使用的記憶體分配器也有關係:如果記憶體分配器設計合理,可以盡可能的減少記憶體碎片的產生。後面將要說到的jemalloc便在控制記憶體碎片方面做的很好。
如果Redis伺服器中的記憶體碎片已經很大,可以透過安全重啟的方式減小記憶體碎片:因為重啟之後,Redis重新從備份檔案中讀取資料,在記憶體中進行重排,為每個資料重新選擇合適的記憶體單元,減小記憶體碎片。
三、Redis資料儲存的細節
1、概述
關於Redis資料儲存的細節,涉及到記憶體分配器(如jemalloc)、簡單動態字串(SDS)、5種物件型別及內部編碼、redisObject。在講述具體內容之前,先說明一下這幾個概念之間的關係。
下圖是執行set hello world時,所涉及到的資料模型。

圖片來源:https://searchdatabase.techtarget.com.cn/7-20218/
(1)dictEntry:Redis是Key-Value資料庫,因此對每個鍵值對都會有一個dictEntry,裡面儲存了指向Key和Value的指標;next指向下一個dictEntry,與本Key-Value無關。
(2)Key:圖中右上角可見,Key(”hello”)並不是直接以字串儲存,而是儲存在SDS結構中。
(3)redisObject:Value(“world”)既不是直接以字串儲存,也不是像Key一樣直接儲存在SDS中,而是儲存在redisObject中。實際上,不論Value是5種型別的哪一種,都是透過redisObject來儲存的;而redisObject中的type欄位指明瞭Value物件的型別,ptr欄位則指向物件所在的地址。不過可以看出,字串物件雖然經過了redisObject的包裝,但仍然需要透過SDS儲存。
實際上,redisObject除了type和ptr欄位以外,還有其他欄點陣圖中沒有給出,如用於指定物件內部編碼的欄位;後面會詳細介紹。
(4)jemalloc:無論是DictEntry物件,還是redisObject、SDS物件,都需要記憶體分配器(如jemalloc)分配記憶體進行儲存。以DictEntry物件為例,有3個指標組成,在64位機器下佔24個位元組,jemalloc會為它分配32位元組大小的記憶體單元。
下麵來分別介紹jemalloc、redisObject、SDS、物件型別及內部編碼。
2、jemalloc
Redis在編譯時便會指定記憶體分配器;記憶體分配器可以是 libc 、jemalloc或者tcmalloc,預設是jemalloc。
jemalloc作為Redis的預設記憶體分配器,在減小記憶體碎片方面做的相對比較好。jemalloc在64位系統中,將記憶體空間劃分為小、大、巨大三個範圍;每個範圍內又劃分了許多小的記憶體塊單位;當Redis儲存資料時,會選擇大小最合適的記憶體塊進行儲存。
jemalloc劃分的記憶體單元如下圖所示:
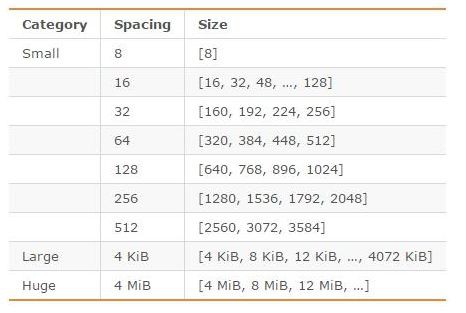
圖片來源:http://blog.csdn.net/zhengpeitao/article/details/76573053
例如,如果需要儲存大小為130位元組的物件,jemalloc會將其放入160位元組的記憶體單元中。
3、redisObject
前面說到,Redis物件有5種型別;無論是哪種型別,Redis都不會直接儲存,而是透過redisObject物件進行儲存。
redisObject物件非常重要,Redis物件的型別、內部編碼、記憶體回收、共享物件等功能,都需要redisObject支援,下麵將透過redisObject的結構來說明它是如何起作用的。
redisObject的定義如下(不同版本的Redis可能稍稍有所不同):
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;
redisObject的每個欄位的含義和作用如下:
(1)type
type欄位表示物件的型別,佔4個位元;目前包括REDIS_STRING(字串)、REDIS_LIST (串列)、REDIS_HASH(雜湊)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
當我們執行type命令時,便是透過讀取RedisObject的type欄位獲得物件的型別;如下圖所示:

(2)encoding
encoding表示物件的內部編碼,佔4個位元。
對於Redis支援的每種型別,都有至少兩種內部編碼,例如對於字串,有int、embstr、raw三種編碼。透過encoding屬性,Redis可以根據不同的使用場景來為物件設定不同的編碼,大大提高了Redis的靈活性和效率。以串列物件為例,有壓縮串列和雙端連結串列兩種編碼方式;如果串列中的元素較少,Redis傾向於使用壓縮串列進行儲存,因為壓縮串列佔用記憶體更少,而且比雙端連結串列可以更快載入;當串列物件元素較多時,壓縮串列就會轉化為更適合儲存大量元素的雙端連結串列。
透過object encoding命令,可以檢視物件採用的編碼方式,如下圖所示:

5種物件型別對應的編碼方式以及使用條件,將在後面介紹。
(3)lru
lru記錄的是物件最後一次被命令程式訪問的時間,佔據的位元數不同的版本有所不同(如4.0版本佔24位元,2.6版本佔22位元)。
透過對比lru時間與當前時間,可以計算某個物件的空轉時間;object idletime命令可以顯示該空轉時間(單位是秒)。object idletime命令的一個特殊之處在於它不改變物件的lru值。

lru值除了透過object idletime命令列印之外,還與Redis的記憶體回收有關係:如果Redis開啟了maxmemory選項,且記憶體回收演演算法選擇的是volatile-lru或allkeys—lru,那麼當Redis記憶體佔用超過maxmemory指定的值時,Redis會優先選擇空轉時間最長的物件進行釋放。
(4)refcount
– refcount與共享物件
refcount記錄的是該物件被取用的次數,型別為整型。refcount的作用,主要在於物件的取用計數和記憶體回收。當建立新物件時,refcount初始化為1;當有新程式使用該物件時,refcount加1;當物件不再被一個新程式使用時,refcount減1;當refcount變為0時,物件佔用的記憶體會被釋放。
Redis中被多次使用的物件(refcount>1),稱為共享物件。Redis為了節省記憶體,當有一些物件重覆出現時,新的程式不會建立新的物件,而是仍然使用原來的物件。這個被重覆使用的物件,就是共享物件。目前共享物件僅支援整數值的字串物件。
– 共享物件的具體實現
Redis的共享物件目前只支援整數值的字串物件。之所以如此,實際上是對記憶體和CPU(時間)的平衡:共享物件雖然會降低記憶體消耗,但是判斷兩個物件是否相等卻需要消耗額外的時間。對於整數值,判斷操作複雜度為O(1);對於普通字串,判斷複雜度為O(n);而對於雜湊、串列、集合和有序集合,判斷的複雜度為O(n^2)。
雖然共享物件只能是整數值的字串物件,但是5種型別都可能使用共享物件(如雜湊、串列等的元素可以使用)。
就目前的實現來說,Redis伺服器在初始化時,會建立10000個字串物件,值分別是0~9999的整數值;當Redis需要使用值為0~9999的字串物件時,可以直接使用這些共享物件。10000這個數字可以透過調整引數REDIS_SHARED_INTEGERS(4.0中是OBJ_SHARED_INTEGERS)的值進行改變。
共享物件的取用次數可以透過object refcount命令檢視,如下圖所示。命令執行的結果頁佐證了只有0~9999之間的整數會作為共享物件。

(5)ptr
ptr指標指向具體的資料,如前面的例子中,set hello world,ptr指向包含字串world的SDS。
(6)總結
綜上所述,redisObject的結構與物件型別、編碼、記憶體回收、共享物件都有關係;一個redisObject物件的大小為16位元組:
4bit+4bit+24bit+4Byte+8Byte=16Byte。
4、SDS
Redis沒有直接使用C字串(即以空字元’\0’結尾的字元陣列)作為預設的字串表示,而是使用了SDS。SDS是簡單動態字串(Simple Dynamic String)的縮寫。
(1)SDS結構
sds的結構如下:
struct sdshdr {
int len;
int free;
char buf[];
};
其中,buf表示位元組陣列,用來儲存字串;len表示buf已使用的長度,free表示buf未使用的長度。下麵是兩個例子。


圖片來源:《Redis設計與實現》
透過SDS的結構可以看出,buf陣列的長度=free+len+1(其中1表示字串結尾的空字元);所以,一個SDS結構佔據的空間為:free所佔長度+len所佔長度+ buf陣列的長度=4+4+free+len+1=free+len+9。
(2)SDS與C字串的比較
SDS在C字串的基礎上加入了free和len欄位,帶來了很多好處:
-
獲取字串長度:SDS是O(1),C字串是O(n)
-
緩衝區上限溢位:使用C字串的API時,如果字串長度增加(如strcat操作)而忘記重新分配記憶體,很容易造成緩衝區的上限溢位;而SDS由於記錄了長度,相應的API在可能造成緩衝區上限溢位時會自動重新分配記憶體,杜絕了緩衝區上限溢位。
-
修改字串時記憶體的重分配:對於C字串,如果要修改字串,必須要重新分配記憶體(先釋放再申請),因為如果沒有重新分配,字串長度增大時會造成記憶體緩衝區上限溢位,字串長度減小時會造成記憶體洩露。而對於SDS,由於可以記錄len和free,因此解除了字串長度和空間陣列長度之間的關聯,可以在此基礎上進行最佳化:空間預分配策略(即分配記憶體時比實際需要的多)使得字串長度增大時重新分配記憶體的機率大大減小;惰性空間釋放策略使得字串長度減小時重新分配記憶體的機率大大減小。
-
存取二進位制資料:SDS可以,C字串不可以。因為C字串以空字元作為字串結束的標識,而對於一些二進位制檔案(如圖片等),內容可能包括空字串,因此C字串無法正確存取;而SDS以字串長度len來作為字串結束標識,因此沒有這個問題。
此外,由於SDS中的buf仍然使用了C字串(即以’\0’結尾),因此SDS可以使用C字串庫中的部分函式;但是需要註意的是,只有當SDS用來儲存文字資料時才可以這樣使用,在儲存二進位制資料時則不行(’\0’不一定是結尾)。
(3)SDS與C字串的應用
Redis在儲存物件時,一律使用SDS代替C字串。例如set hello world命令,hello和world都是以SDS的形式儲存的。而sadd myset member1 member2 member3命令,不論是鍵(”myset”),還是集合中的元素(”member1”、 ”member2”和”member3”),都是以SDS的形式儲存。除了儲存物件,SDS還用於儲存各種緩衝區。
只有在字串不會改變的情況下,如列印日誌時,才會使用C字串。
四、Redis的物件型別與內部編碼
前面已經說過,Redis支援5種物件型別,而每種結構都有至少兩種編碼;這樣做的好處在於:一方面介面與實現分離,當需要增加或改變內部編碼時,使用者使用不受影響,另一方面可以根據不同的應用場景切換內部編碼,提高效率。
Redis各種物件型別支援的內部編碼如下圖所示(圖中版本是Redis3.0,Redis後面版本中又增加了內部編碼,略過不提;本章所介紹的內部編碼都是基於3.0的):

圖片來源:《Redis設計與實現》
關於Redis內部編碼的轉換,都符合以下規律:編碼轉換在Redis寫入資料時完成,且轉換過程不可逆,只能從小記憶體編碼向大記憶體編碼轉換。
1、字串
(1)概況
字串是最基礎的型別,因為所有的鍵都是字串型別,且字串之外的其他幾種複雜型別的元素也是字串。
字串長度不能超過512MB。
(2)內部編碼
字串型別的內部編碼有3種,它們的應用場景如下:
-
int:8個位元組的長整型。字串值是整型時,這個值使用long整型表示。
-
embstr:<=39位元組的字串。embstr與raw都使用redisObject和sds儲存資料,區別在於,embstr的使用只分配一次記憶體空間(因此redisObject和sds是連續的),而raw需要分配兩次記憶體空間(分別為redisObject和sds分配空間)。因此與raw相比,embstr的好處在於建立時少分配一次空間,刪除時少釋放一次空間,以及物件的所有資料連在一起,尋找方便。而embstr的壞處也很明顯,如果字串的長度增加需要重新分配記憶體時,整個redisObject和sds都需要重新分配空間,因此redis中的embstr實現為只讀。
-
raw:大於39個位元組的字串
示例如下圖所示:

embstr和raw進行區分的長度,是39;是因為redisObject的長度是16位元組,sds的長度是9+字串長度;因此當字串長度是39時,embstr的長度正好是16+9+39=64,jemalloc正好可以分配64位元組的記憶體單元。
(3)編碼轉換
當int資料不再是整數,或大小超過了long的範圍時,自動轉化為raw。
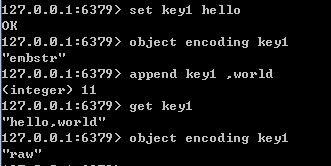
而對於embstr,由於其實現是隻讀的,因此在對embstr物件進行修改時,都會先轉化為raw再進行修改,因此,只要是修改embstr物件,修改後的物件一定是raw的,無論是否達到了39個位元組。示例如下圖所示:
2、串列
(1)概況
串列(list)用來儲存多個有序的字串,每個字串稱為元素;一個串列可以儲存2^32-1個元素。Redis中的串列支援兩端插入和彈出,並可以獲得指定位置(或範圍)的元素,可以充當陣列、佇列、棧等。
(2)內部編碼
串列的內部編碼可以是壓縮串列(ziplist)或雙端連結串列(linkedlist)。
雙端連結串列:由一個list結構和多個listNode結構組成;典型結構如下圖所示:

圖片來源:《Redis設計與實現》
透過圖中可以看出,雙端連結串列同時儲存了表頭指標和表尾指標,並且每個節點都有指向前和指向後的指標;連結串列中儲存了串列的長度;dup、free和match為節點值設定型別特定函式,所以連結串列可以用於儲存各種不同型別的值。而連結串列中每個節點指向的是type為字串的redisObject。
壓縮串列:壓縮串列是Redis為了節約記憶體而開發的,是由一系列特殊編碼的連續記憶體塊(而不是像雙端連結串列一樣每個節點是指標)組成的順序型資料結構;具體結構相對比較複雜,略。與雙端鏈表相比,壓縮串列可以節省記憶體空間,但是進行修改或增刪操作時,複雜度較高;因此當節點數量較少時,可以使用壓縮串列;但是節點數量多時,還是使用雙端連結串列划算。
壓縮串列不僅用於實現串列,也用於實現雜湊、有序串列;使用非常廣泛。
(3)編碼轉換
只有同時滿足下麵兩個條件時,才會使用壓縮串列:串列中元素數量小於512個;串列中所有字串物件都不足64位元組。如果有一個條件不滿足,則使用雙端串列;且編碼只可能由壓縮串列轉化為雙端連結串列,反方向則不可能。
下圖展示了串列編碼轉換的特點:

其中,單個字串不能超過64位元組,是為了便於統一分配每個節點的長度;這裡的64位元組是指字串的長度,不包括SDS結構,因為壓縮串列使用連續、定長記憶體塊儲存字串,不需要SDS結構指明長度。後面提到壓縮串列,也會強調長度不超過64位元組,原理與這裡類似。
3、雜湊
(1)概況
雜湊(作為一種資料結構),不僅是redis對外提供的5種物件型別的一種(與字串、串列、集合、有序結合併列),也是Redis作為Key-Value資料庫所使用的資料結構。為了說明的方便,在本文後面當使用“內層的雜湊”時,代表的是redis對外提供的5種物件型別的一種;使用“外層的雜湊”代指Redis作為Key-Value資料庫所使用的資料結構。
(2)內部編碼
內層的雜湊使用的內部編碼可以是壓縮串列(ziplist)和雜湊表(hashtable)兩種;Redis的外層的雜湊則只使用了hashtable。
壓縮串列前面已介紹。與雜湊表相比,壓縮串列用於元素個數少、元素長度小的場景;其優勢在於集中儲存,節省空間;同時,雖然對於元素的操作複雜度也由O(n)變為了O(1),但由於雜湊中元素數量較少,因此操作的時間並沒有明顯劣勢。
hashtable:一個hashtable由1個dict結構、2個dictht結構、1個dictEntry指標陣列(稱為bucket)和多個dictEntry結構組成。
正常情況下(即hashtable沒有進行rehash時)各部分關係如下圖所示:

圖片改編自:《Redis設計與實現》
下麵從底層向上依次介紹各個部分:
– dictEntry
dictEntry結構用於儲存鍵值對,結構定義如下:
typedef struct dictEntry{
void *key;
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
struct dictEntry *next;
}dictEntry;
其中,各個屬性的功能如下:
-
key:鍵值對中的鍵;
-
val:鍵值對中的值,使用union(即共用體)實現,儲存的內容既可能是一個指向值的指標,也可能是64位整型,或無符號64位整型;
-
next:指向下一個dictEntry,用於解決雜湊衝突問題
在64位系統中,一個dictEntry物件佔24位元組(key/val/next各佔8位元組)。
– bucket
bucket是一個陣列,陣列的每個元素都是指向dictEntry結構的指標。redis中bucket陣列的大小計算規則如下:大於dictEntry的、最小的2^n;例如,如果有1000個dictEntry,那麼bucket大小為1024;如果有1500個dictEntry,則bucket大小為2048。
– dictht
dictht結構如下:
typedef struct dictht{
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
}dictht;
其中,各個屬性的功能說明如下:
-
table屬性是一個指標,指向bucket;
-
size屬性記錄了雜湊表的大小,即bucket的大小;
-
used記錄了已使用的dictEntry的數量;
-
sizemask屬性的值總是為size-1,這個屬性和雜湊值一起決定一個鍵在table中儲存的位置。
– dict
一般來說,透過使用dictht和dictEntry結構,便可以實現普通雜湊表的功能;但是Redis的實現中,在dictht結構的上層,還有一個dict結構。下麵說明dict結構的定義及作用。
dict結構如下:
typedef struct dict{
dictType *type;
void *privdata;
dictht ht[2];
int trehashidx;
} dict;
其中,type屬性和privdata屬性是為了適應不同型別的鍵值對,用於建立多型字典。
ht屬性和trehashidx屬性則用於rehash,即當雜湊表需要擴充套件或收縮時使用。ht是一個包含兩個項的陣列,每項都指向一個dictht結構,這也是Redis的雜湊會有1個dict、2個dictht結構的原因。通常情況下,所有的資料都是存在放dict的ht[0]中,ht[1]只在rehash的時候使用。dict進行rehash操作的時候,將ht[0]中的所有資料rehash到ht[1]中。然後將ht[1]賦值給ht[0],並清空ht[1]。
因此,Redis中的雜湊之所以在dictht和dictEntry結構之外還有一個dict結構,一方面是為了適應不同型別的鍵值對,另一方面是為了rehash。
(3)編碼轉換
如前所述,Redis中內層的雜湊既可能使用雜湊表,也可能使用壓縮串列。
只有同時滿足下麵兩個條件時,才會使用壓縮串列:雜湊中元素數量小於512個;雜湊中所有鍵值對的鍵和值字串長度都小於64位元組。如果有一個條件不滿足,則使用雜湊表;且編碼只可能由壓縮串列轉化為雜湊表,反方向則不可能。
下圖展示了Redis內層的雜湊編碼轉換的特點:

4、集合
(1)概況
集合(set)與串列類似,都是用來儲存多個字串,但集合與串列有兩點不同:集合中的元素是無序的,因此不能透過索引來操作元素;集合中的元素不能有重覆。
一個集合中最多可以儲存2^32-1個元素;除了支援常規的增刪改查,Redis還支援多個集合取交集、並集、差集。
(2)內部編碼
集合的內部編碼可以是整數集合(intset)或雜湊表(hashtable)。
雜湊表前面已經講過,這裡略過不提;需要註意的是,集合在使用雜湊表時,值全部被置為null。
整數集合的結構定義如下:
typedef struct intset{
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
其中,encoding代表contents中儲存內容的型別,雖然contents(儲存集合中的元素)是int8_t型別,但實際上其儲存的值是int16_t、int32_t或int64_t,具體的型別便是由encoding決定的;length表示元素個數。
整數集合適用於集合所有元素都是整數且集合元素數量較小的時候,與雜湊表相比,整數集合的優勢在於集中儲存,節省空間;同時,雖然對於元素的操作複雜度也由O(n)變為了O(1),但由於集合數量較少,因此操作的時間並沒有明顯劣勢。
(3)編碼轉換
只有同時滿足下麵兩個條件時,集合才會使用整數集合:集合中元素數量小於512個;集合中所有元素都是整數值。如果有一個條件不滿足,則使用雜湊表;且編碼只可能由整數集合轉化為雜湊表,反方向則不可能。
下圖展示了集合編碼轉換的特點:

5、有序集合
(1)概況
有序集合與集合一樣,元素都不能重覆;但與集合不同的是,有序集合中的元素是有順序的。與串列使用索引下標作為排序依據不同,有序集合為每個元素設定一個分數(score)作為排序依據。
(2)內部編碼
有序集合的內部編碼可以是壓縮串列(ziplist)或跳躍表(skiplist)。ziplist在串列和雜湊中都有使用,前面已經講過,這裡略過不提。
跳躍表是一種有序資料結構,透過在每個節點中維持多個指向其他節點的指標,從而達到快速訪問節點的目的。除了跳躍表,實現有序資料結構的另一種典型實現是平衡樹;大多數情況下,跳躍表的效率可以和平衡樹媲美,且跳躍表實現比平衡樹簡單很多,因此redis中選用跳躍表代替平衡樹。跳躍表支援平均O(logN)、最壞O(N)的複雜點進行節點查詢,並支援順序操作。Redis的跳躍表實現由zskiplist和zskiplistNode兩個結構組成:前者用於儲存跳躍表資訊(如頭結點、尾節點、長度等),後者用於表示跳躍表節點。具體結構相對比較複雜,略。
(3)編碼轉換
只有同時滿足下麵兩個條件時,才會使用壓縮串列:有序集合中元素數量小於128個;有序集合中所有成員長度都不足64位元組。如果有一個條件不滿足,則使用跳躍表;且編碼只可能由壓縮串列轉化為跳躍表,反方向則不可能。
下圖展示了有序集合編碼轉換的特點:

五、應用舉例
瞭解Redis的記憶體模型之後,下麵透過幾個例子說明其應用。
1、估算Redis記憶體使用量
要估算redis中的資料佔據的記憶體大小,需要對redis的記憶體模型有比較全面的瞭解,包括前面介紹的hashtable、sds、redisobject、各種物件型別的編碼方式等。
下麵以最簡單的字串型別來進行說明。
假設有90000個鍵值對,每個key的長度是7個位元組,每個value的長度也是7個位元組(且key和value都不是整數);下麵來估算這90000個鍵值對所佔用的空間。在估算佔據空間之前,首先可以判定字串型別使用的編碼方式:embstr。
90000個鍵值對佔據的記憶體空間主要可以分為兩部分:一部分是90000個dictEntry佔據的空間;一部分是鍵值對所需要的bucket空間。
每個dictEntry佔據的空間包括:
1) 一個dictEntry,24位元組,jemalloc會分配32位元組的記憶體塊
2) 一個key,7位元組,所以SDS(key)需要7+9=16個位元組,jemalloc會分配16位元組的記憶體塊
3) 一個redisObject,16位元組,jemalloc會分配16位元組的記憶體塊
4) 一個value,7位元組,所以SDS(value)需要7+9=16個位元組,jemalloc會分配16位元組的記憶體塊
5) 綜上,一個dictEntry需要32+16+16+16=80個位元組。
bucket空間:bucket陣列的大小為大於90000的最小的2^n,是131072;每個bucket元素為8位元組(因為64位系統中指標大小為8位元組)。
因此,可以估算出這90000個鍵值對佔據的記憶體大小為:90000*80 + 131072*8 = 8248576。
下麵寫個程式在redis中驗證一下:
public class RedisTest {
public static Jedis jedis = new Jedis(“localhost”, 6379);
public static void main(String[] args) throws Exception{
Long m1 = Long.valueOf(getMemory());
insertData();
Long m2 = Long.valueOf(getMemory());
System.out.println(m2 – m1);
}
public static void insertData(){
for(int i = 10000; i < 100000; i++){
jedis.set(“aa” + i, “aa” + i); //key和value長度都是7位元組,且不是整數
}
}
public static String getMemory(){
String memoryAllLine = jedis.info(“memory”);
String usedMemoryLine = memoryAllLine.split(“\r\n”)[1];
String memory = usedMemoryLine.substring(usedMemoryLine.indexOf(‘:’) + 1);
return memory;
}
}
執行結果:8247552
理論值與結果值誤差在萬分之1.2,對於計算需要多少記憶體來說,這個精度已經足夠了。之所以會存在誤差,是因為在我們插入90000條資料之前redis已分配了一定的bucket空間,而這些bucket空間尚未使用。
作為對比將key和value的長度由7位元組增加到8位元組,則對應的SDS變為17個位元組,jemalloc會分配32個位元組,因此每個dictEntry佔用的位元組數也由80位元組變為112位元組。此時估算這90000個鍵值對佔據記憶體大小為:90000*112 + 131072*8 = 11128576。
在redis中驗證程式碼如下(只修改插入資料的程式碼):
public static void insertData(){
for(int i = 10000; i < 100000; i++){
jedis.set(“aaa” + i, “aaa” + i); //key和value長度都是8位元組,且不是整數
}
}
執行結果:11128576;估算準確。
對於字串型別之外的其他型別,對記憶體佔用的估算方法是類似的,需要結合具體型別的編碼方式來確定。
2、最佳化記憶體佔用
瞭解redis的記憶體模型,對最佳化redis記憶體佔用有很大幫助。下麵介紹幾種最佳化場景。
(1)利用jemalloc特性進行最佳化
上一小節所講述的90000個鍵值便是一個例子。由於jemalloc分配記憶體時數值是不連續的,因此key/value字串變化一個位元組,可能會引起佔用記憶體很大的變動;在設計時可以利用這一點。
例如,如果key的長度如果是8個位元組,則SDS為17位元組,jemalloc分配32位元組;此時將key長度縮減為7個位元組,則SDS為16位元組,jemalloc分配16位元組;則每個key所佔用的空間都可以縮小一半。
(2)使用整型/長整型
如果是整型/長整型,Redis會使用int型別(8位元組)儲存來代替字串,可以節省更多空間。因此在可以使用長整型/整型代替字串的場景下,儘量使用長整型/整型。
(3)共享物件
利用共享物件,可以減少物件的建立(同時減少了redisObject的建立),節省記憶體空間。目前redis中的共享物件只包括10000個整數(0-9999);可以透過調整REDIS_SHARED_INTEGERS引數提高共享物件的個數;例如將REDIS_SHARED_INTEGERS調整到20000,則0-19999之間的物件都可以共享。
考慮這樣一種場景:論壇網站在redis中儲存了每個帖子的瀏覽數,而這些瀏覽數絕大多數分佈在0-20000之間,這時候透過適當增大REDIS_SHARED_INTEGERS引數,便可以利用共享物件節省記憶體空間。
(4)避免過度設計
然而需要註意的是,不論是哪種最佳化場景,都要考慮記憶體空間與設計複雜度的權衡;而設計複雜度會影響到程式碼的複雜度、可維護性。
如果資料量較小,那麼為了節省記憶體而使得程式碼的開發、維護變得更加困難並不划算;還是以前面講到的90000個鍵值對為例,實際上節省的記憶體空間只有幾MB。但是如果資料量有幾千萬甚至上億,考慮記憶體的最佳化就比較必要了。
3、關註記憶體碎片率
記憶體碎片率是一個重要的引數,對redis 記憶體的最佳化有重要意義。
如果記憶體碎片率過高(jemalloc在1.03左右比較正常),說明記憶體碎片多,記憶體浪費嚴重;這時便可以考慮重啟redis服務,在記憶體中對資料進行重排,減少記憶體碎片。
如果記憶體碎片率小於1,說明redis記憶體不足,部分資料使用了虛擬記憶體(即swap);由於虛擬記憶體的存取速度比物理記憶體差很多(2-3個數量級),此時redis的訪問速度可能會變得很慢。因此必須設法增大物理記憶體(可以增加伺服器節點數量,或提高單機記憶體),或減少redis中的資料。
要減少redis中的資料,除了選用合適的資料型別、利用共享物件等,還有一點是要設定合理的資料回收策略(maxmemory-policy),當記憶體達到一定量後,根據不同的優先順序對記憶體進行回收。
六、參考文獻
-
《Redis開發與運維》
-
《Redis設計與實現》
-
https://redis.io/documentation
-
http://redisdoc.com/server/info.html
-
https://www.cnblogs.com/lhcpig/p/4769397.html
-
https://searchdatabase.techtarget.com.cn/7-20218/
-
http://www.cnblogs.com/mushroom/p/4738170.html
-
http://www.imooc.com/article/3645
-
http://blog.csdn.net/zhengpeitao/article/details/76573053
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能

