
導語
這週末就分享個小爬蟲吧。利用Python爬取並簡單地視覺化分析噹噹網的圖書資料。
讓我們愉快地開始吧~本文相關原始碼加群:696541369獲取,還可獲取更多python學習資料!

開發工具
Python版本:3.6.4
相關模組:
requests模組;
bs4模組;
wordcloud模組;
jieba模組;
pillow模組;
pyecharts模組;
以及一些Python自帶的模組。
環境搭建
安裝Python並新增到環境變數,pip安裝需要的相關模組即可。
資料爬取
任務:
根據給定的關鍵字,爬取與該關鍵字相關的所有圖書資料。
實現:
以關鍵字為python為例,我們要爬取的圖書資料的網頁頁面是這樣子的:

其中,網頁的連結格式為:
http://search.dangdang.com/?key={keyword}&act;=input&page;_index={page_index}’
因此請求所有與關鍵詞相關的連結:

然後利用BeautifulSoup分別解析傳回的網頁資料,提取我們自己需要的資料即可:

執行效果:
在cmd視窗執行”ddSpider.py”檔案即可。
效果如下:

資料分析
好的,現在就簡單地視覺化分析一波我們爬取到的61頁python相關的圖書資料吧~
讓我們先看看圖書的價格分佈吧:

有沒有人想知道最貴的一本python相關的書的單價是多少呀?答案是:28390RMB
書名是:
Python in Computers Programming
QAQ買不起買不起。
再來看看圖書的評分分佈唄:

看來大多數python相關的圖書都沒人買過誒~大概是買不起吧T_T。
再來評論數量?
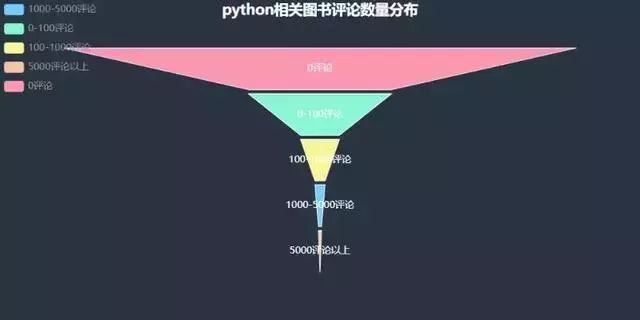
那麼評論數量TOP6的圖書有哪些呢?

老規矩,畫兩個詞雲作結吧,把所有python相關的圖書的簡介做成詞雲如何?

番外篇
這篇文章真的結束了嗎?
這篇文章真的結束了嗎?
這篇文章真的結束了嗎?
難道沒有人好奇我文章的封面怎麼做的嗎?
好吧,我寫文章的時候沒人看到,所以即使真的有人好奇也沒法說?
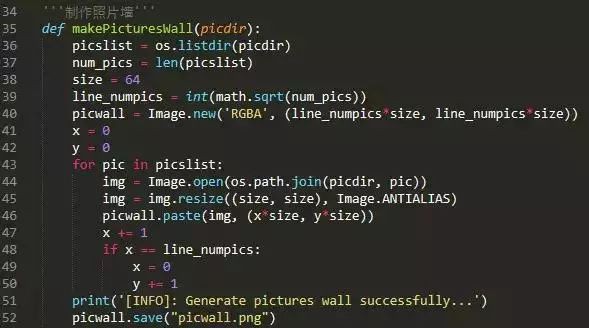
其實很簡單,就是下了961張python相關圖書的圖書封面,然後拼在一起了。
原始碼如下:
效果如下:


