剛開始動手寫爬蟲,你只需要關註最核心的部分,也就是先成功抓到資料,其他的諸如:下載速度、儲存方式、程式碼條理性等先不管,這樣的程式碼簡短易懂、容易上手,能夠增強信心。
作者:蘇克
源自:
https://www.makcyun.top/web_scraping_withpython18.html
基本環境配置
-
版本:Python3
-
系統:Windows
-
相關模組:pandas、csv
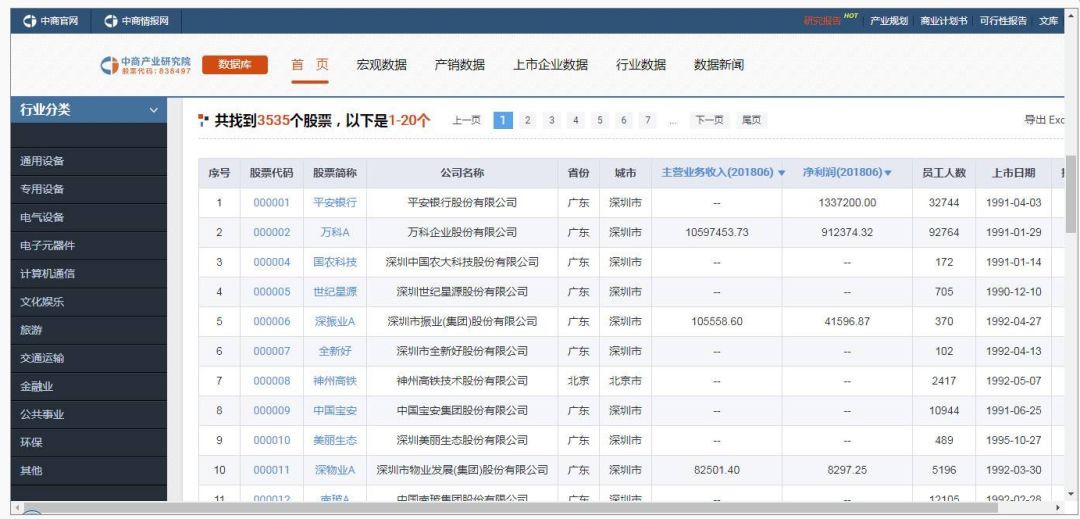
爬取標的網站
實現程式碼
import pandas as pd
import csv
for i in range(1,178): # 爬取全部頁
tb = pd.read_html('http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum;=%s' % (str(i)))[3]
tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', essay-header=1, index=0)
(左右滑動可檢視完整程式碼)
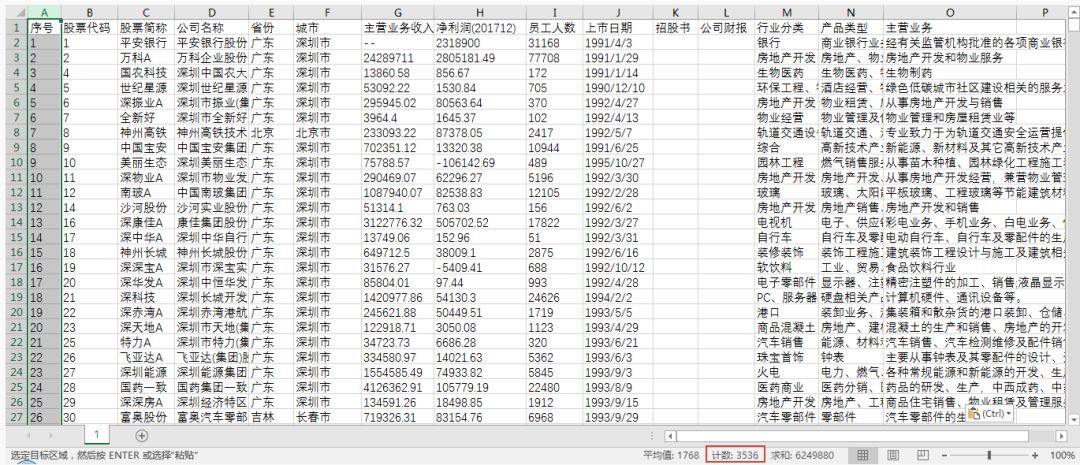
3000+ 上市公司的資訊,安安靜靜地躺在 Excel 中:
有了上面的信心後,我開始繼續完善程式碼,因為 5 行程式碼太單薄,功能也太簡單,大致從以下幾個方面進行了完善:
- 增加異常處理
由於爬取上百頁的網頁,中途很可能由於各種問題導致爬取失敗,所以增加了 try except 、if 等陳述句,來處理可能出現的異常,讓程式碼更健壯。
- 增加程式碼靈活性
初版程式碼由於固定了 URL 引數,所以只能爬取固定的內容,但是人的想法是多變的,一會兒想爬這個一會兒可能又需要那個,所以可以透過修改 URL 請求引數,來增加程式碼靈活性,從而爬取更靈活的資料。
- 修改儲存方式
初版程式碼我選擇了儲存到 Excel 這種最為熟悉簡單的方式,人是一種惰性動物,很難離開自己的舒適區。但是為了學習新知識,所以我選擇將資料儲存到 MySQL 中,以便練習 MySQL 的使用。
-
加快爬取速度
初版程式碼使用了最簡單的單行程爬取方式,爬取速度比較慢,考慮到網頁數量比較大,所以修改為了多行程的爬取方式。
經過以上這幾點的完善,程式碼量從原先的 5 行增加到了下麵的幾十行:
import requests
import pandas as pd
from bs4 import BeautifulSoup
from lxml import etree
import time
import pymysql
from sqlalchemy import create_engine
from urllib.parse import urlencode # 編碼 URL 字串
start_time = time.time() #計算程式執行時間
def get_one_page(i):
try:
essay-headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36’
}
paras = {
‘reportTime’: ‘2017-12-31’,
#可以改報告日期,比如2018-6-30獲得的就是該季度的資訊
‘pageNum’: i #頁碼
}
url = ‘http://s.askci.com/stock/a/?’ + urlencode(paras)
response = requests.get(url,essay-headers = essay-headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print(‘爬取失敗’)
def parse_one_page(html):
soup = BeautifulSoup(html,‘lxml’)
content = soup.select(‘#myTable04’)[0] #[0]將傳回的list改為bs4型別
tbl = pd.read_html(content.prettify(),essay-header = 0)[0]
# prettify()最佳化程式碼,[0]從pd.read_html傳回的list中提取出DataFrame
tbl.rename(columns = {‘序號’:‘serial_number’, ‘股票程式碼’:‘stock_code’, ‘股票簡稱’:‘stock_abbre’, ‘公司名稱’:‘company_name’, ‘省份’:‘province’, ‘城市’:‘city’, ‘主營業務收入(201712)’:‘main_bussiness_income’, ‘凈利潤(201712)’:‘net_profit’, ‘員工人數’:’employees’, ‘上市日期’:‘listing_date’, ‘招股書’:‘zhaogushu’, ‘公司財報’:‘financial_report’, ‘行業分類’:‘industry_classification’, ‘產品型別’:‘industry_type’, ‘主營業務’:‘main_business’},inplace = True)
return tbl
def generate_mysql():
conn = pymysql.connect(
host=‘localhost’,
user=‘root’,
password=‘******’,
port=3306,
charset = ‘utf8’,
db = ‘wade’)
cursor = conn.cursor()
sql = ‘CREATE TABLE IF NOT EXISTS listed_company (serial_number INT(20) NOT NULL,stock_code INT(20) ,stock_abbre VARCHAR(20) ,company_name VARCHAR(20) ,province VARCHAR(20) ,city VARCHAR(20) ,main_bussiness_income VARCHAR(20) ,net_profit VARCHAR(20) ,employees INT(20) ,listing_date DATETIME(0) ,zhaogushu VARCHAR(20) ,financial_report VARCHAR(20) , industry_classification VARCHAR(20) ,industry_type VARCHAR(100) ,main_business VARCHAR(200) ,PRIMARY KEY (serial_number))’
cursor.execute(sql)
conn.close()
def write_to_sql(tbl, db = ‘wade’):
engine = create_engine(‘mysql+pymysql://root:******@localhost:3306/{0}?charset=utf8’.format(db))
try:
tbl.to_sql(‘listed_company2’,con = engine,if_exists=‘append’,index=False)
# append表示在原有表基礎上增加,但該表要有表頭
except Exception as e:
print(e)def main(page):
generate_mysql()
for i in range(1,page):
html = get_one_page(i)
tbl = parse_one_page(html)
write_to_sql(tbl)# # 單行程if __name__ == ‘__main__’:
main(178)
endtime = time.time()-start_time
print(‘程式運行了%.2f秒’ %endtime)
# 多行程
from multiprocessing import Pool
if __name__ == '__main__':
pool = Pool(4)
pool.map(main, [i for i in range(1,178)]) #共有178頁
endtime = time.time()-start_time
print('程式運行了%.2f秒' %(time.time()-start_time))
(左右滑動可檢視完整程式碼)
結語
這個過程覺得很自然,因為每次修改都是針對一個小點,一點點去學,搞懂後新增進來,而如果讓你上來就直接寫出這幾十行的程式碼,你很可能就放棄了。
所以,你可以看到,入門爬蟲是有套路的,最重要的是給自己信心。
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,謝謝大家對小編的支援。


已傳送
朋友將在看一看看到
分享你的想法…
分享想法到看一看