
-
在可能的情況下,系統應當能夠自愈。
-
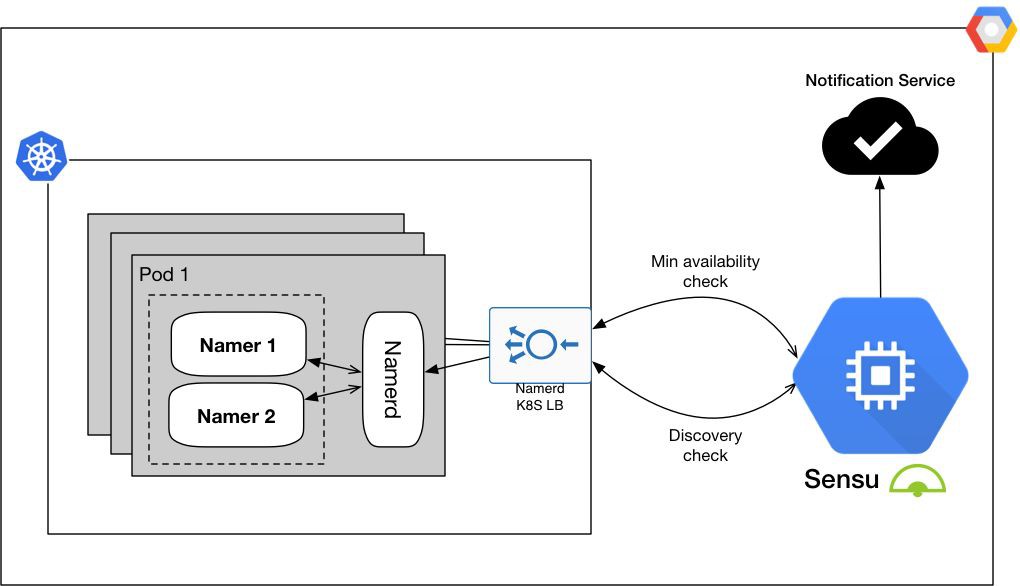
監控系統必須能夠上報系統中每個模組內部和外部的健康狀態。
-
盡可能地提高系統的自愈能力,併在未能自愈或無法修複時發出告警。
GET /api/1/dtabs/<namespace> HTTP/1.1HTTP/1.1 200 OK{{"prefix":"/srv/default","dst":"/#/io.l5d.k8s/prefix/portName"},{"prefix":"/svc","dst":"/srv"}
POST /dtab/delegator.json HTTP/1.1{"dtab":<dtab_configuration>,"namespace":<namespace_name>,"path":"/prefix/service"}HTTP/1.1 200 OK{"type":"delegate","path":"/prefix/service","delegate":{"type":"alt","path":"/srv/prefix/service","dentry":{"prefix":"/svc","dst":"/srv"},"alt":[{"type":"neg",...},{"type":"leaf","path":"/#/io.l5d.k8s/prefix/portName/service","dentry":{"prefix":"/srv/default","dst":"/#/io.l5d.k8s/prefix/portName"},"bound":{"addr":{"type":"bound",...},"id":"/%/io.l5d.k8s.daemonset/mesh/...","path":"/"}},...]}}
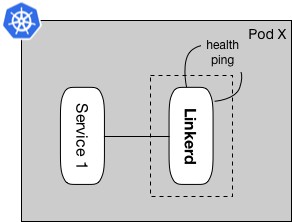
GET /admin/ping HTTP/1.1HTTP/1.1 200 OKpong
-
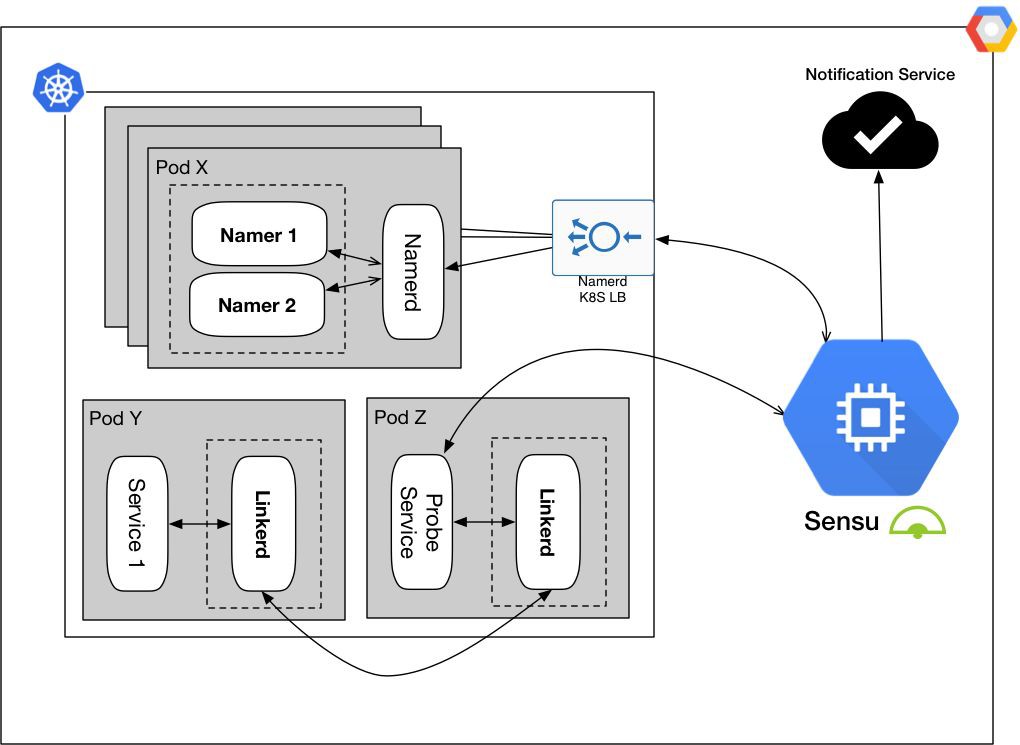
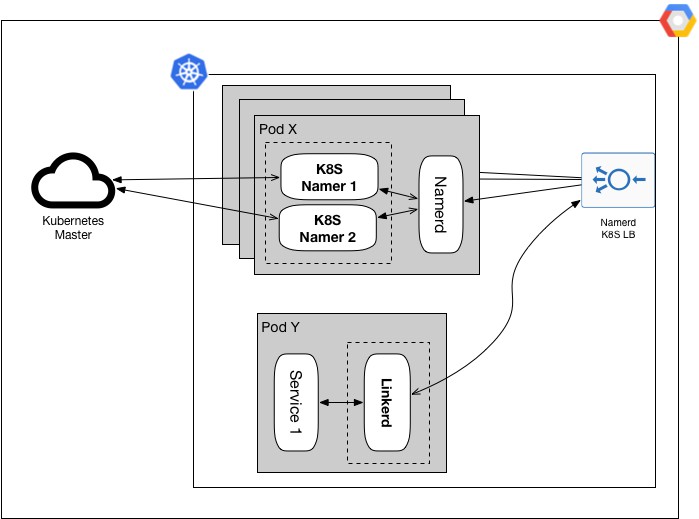
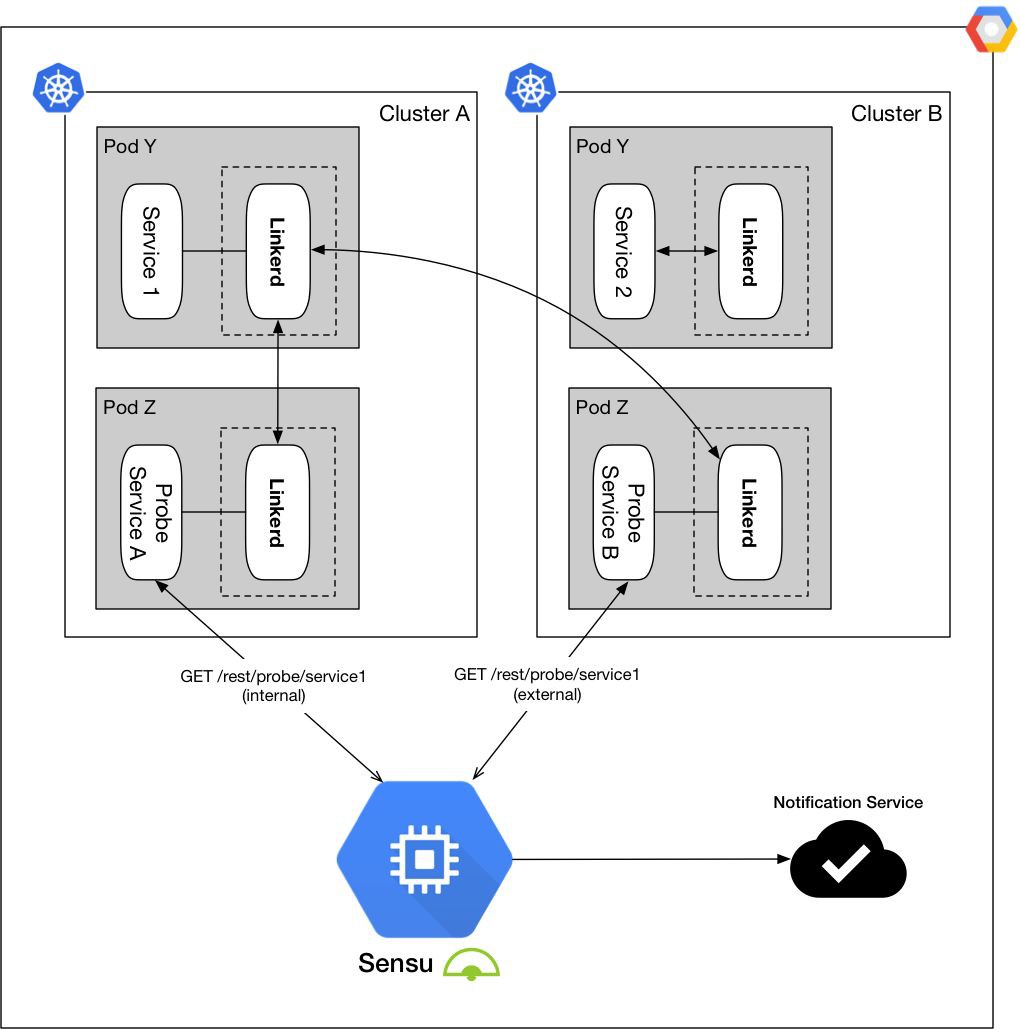
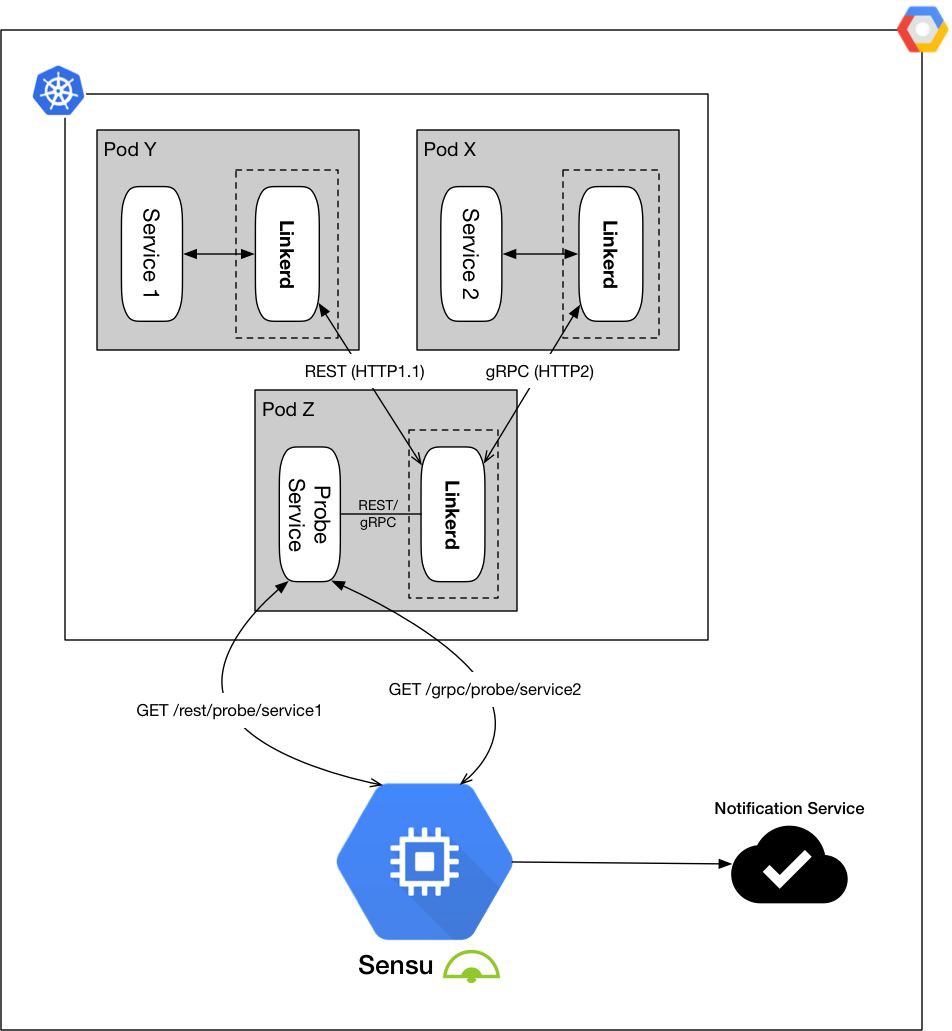
將控制面板和資料平面單獨分開,從而最小化我們的監控範圍,而且對於監控棧來說監控物件也變得更加具象。
-
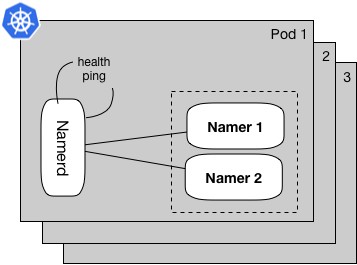
從不同的維度實施健康檢查,並確保容器操作和功能檢查是分別單獨監控的。
-
……並且,使用這些監控設定時,我們讓可操作的監控事件變得更加清晰而且可以告警出來。
