小編邀請您,先思考:
1 如何計算TF-IDF?
2 TF-IDF有什麼應用?
3 如何提取文字的關鍵詞和摘要?
有一篇很長的文章,我要用計算機提取它的關鍵詞(Automatic Keyphrase extraction),完全不加以人工幹預,請問怎樣才能正確做到?
這個問題涉及到資料挖掘、文字處理、資訊檢索等很多計算機前沿領域,但是出乎意料的是,有一個非常簡單的經典演演算法,可以給出令人相當滿意的結果。它簡單到都不需要高等數學,普通人只用10分鐘就可以理解,這就是我今天想要介紹的TF-IDF(https://en.wikipedia.org/wiki/Tf%E2%80%93idf )演演算法。
讓我們從一個實體開始講起。假定現在有一篇長文《中國的蜜蜂養殖》,我們準備用計算機提取它的關鍵詞。
一個容易想到的思路,就是找到出現次數最多的詞。如果某個詞很重要,它應該在這篇文章中多次出現。於是,我們進行”詞頻”(Term Frequency,縮寫為TF)統計。
結果你肯定猜到了,出現次數最多的詞是—-“的”、”是”、”在”—-這一類最常用的詞。它們叫做”停用詞”( http://baike.baidu.com/view/3784680.htm )(stop words),表示對找到結果毫無幫助、必須過濾掉的詞。
假設我們把它們都過濾掉了,只考慮剩下的有實際意義的詞。這樣又會遇到了另一個問題,我們可能發現”中國”、”蜜蜂”、”養殖”這三個詞的出現次數一樣多。這是不是意味著,作為關鍵詞,它們的重要性是一樣的?
顯然不是這樣。因為”中國”是很常見的詞,相對而言,”蜜蜂”和”養殖”不那麼常見。如果這三個詞在一篇文章的出現次數一樣多,有理由認為,”蜜蜂”和”養殖”的重要程度要大於”中國”,也就是說,在關鍵詞排序上面,”蜜蜂”和”養殖”應該排在”中國”的前面。
所以,我們需要一個重要性調整繫數,衡量一個詞是不是常見詞。如果某個詞比較少見,但是它在這篇文章中多次出現,那麼它很可能就反映了這篇文章的特性,正是我們所需要的關鍵詞。
用統計學語言表達,就是在詞頻的基礎上,要對每個詞分配一個”重要性”權重。最常見的詞(”的”、”是”、”在”)給予最小的權重,較常見的詞(”中國”)給予較小的權重,較少見的詞(”蜜蜂”、”養殖”)給予較大的權重。這個權重叫做”逆檔案頻率”(Inverse Document Frequency,縮寫為IDF),它的大小與一個詞的常見程度成反比。
知道了”詞頻”(TF)和”逆檔案頻率”(IDF)以後,將這兩個值相乘,就得到了一個詞的TF-IDF值。某個詞對文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的幾個詞,就是這篇文章的關鍵詞。
下麵就是這個演演算法的細節。
第一步,計算詞頻。

考慮到文章有長短之分,為了便於不同文章的比較,進行”詞頻”標準化。

或者

第二步,計算逆檔案頻率。
這時,需要一個語料庫(corpus),用來模擬語言的使用環境。
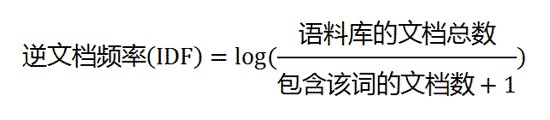
如果一個詞越常見,那麼分母就越大,逆檔案頻率就越小越接近0。分母之所以要加1,是為了避免分母為0(即所有檔案都不包含該詞)。log表示對得到的值取對數。
第三步,計算TF-IDF。

可以看到,TF-IDF與一個詞在檔案中的出現次數成正比,與該詞在整個語言中的出現次數成反比。所以,自動提取關鍵詞的演演算法就很清楚了,就是計算出檔案的每個詞的TF-IDF值,然後按降序排列,取排在最前面的幾個詞。
還是以《中國的蜜蜂養殖》為例,假定該文長度為1000個詞,”中國”、”蜜蜂”、”養殖”各出現20次,則這三個詞的”詞頻”(TF)都為0.02。然後,搜尋Google發現,包含”的”字的網頁共有250億張,假定這就是中文網頁總數。包含”中國”的網頁共有62.3億張,包含”蜜蜂”的網頁為0.484億張,包含”養殖”的網頁為0.973億張。則它們的逆檔案頻率(IDF)和TF-IDF如下:
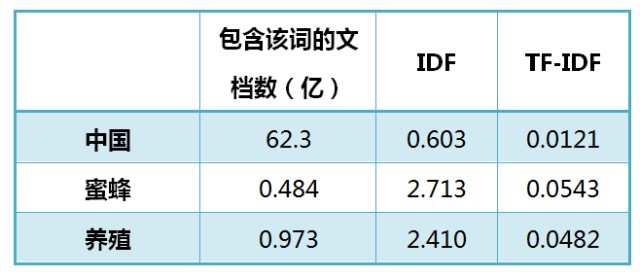
從上表可見,”蜜蜂”的TF-IDF值最高,”養殖”其次,”中國”最低。(如果還計算”的”字的TF-IDF,那將是一個極其接近0的值。)所以,如果只選擇一個詞,”蜜蜂”就是這篇文章的關鍵詞。
除了自動提取關鍵詞,TF-IDF演演算法還可以用於許多別的地方。比如,資訊檢索時,對於每個檔案,都可以分別計算一組搜尋詞(”中國”、”蜜蜂”、”養殖”)的TF-IDF,將它們相加,就可以得到整個檔案的TF-IDF。這個值最高的檔案就是與搜尋詞最相關的檔案。
TF-IDF演演算法的優點是簡單快速,結果比較符合實際情況。缺點是,單純以”詞頻”衡量一個詞的重要性,不夠全面,有時重要的詞可能出現次數並不多。而且,這種演演算法無法體現詞的位置資訊,出現位置靠前的詞與出現位置靠後的詞,都被視為重要性相同,這是不正確的。(一種解決方法是,對全文的第一段和每一段的第一句話,給予較大的權重。)
找出相似文章
我們再來研究另一個相關的問題。有些時候,除了找到關鍵詞,我們還希望找到與原文章相似的其他文章。比如,”Google新聞”在主新聞下方,還提供多條相似的新聞。

為了找出相似的文章,需要用到”餘弦相似性” ( https://en.wikipedia.org/wiki/Cosine_similarity )(cosine similiarity)。下麵,我舉一個例子來說明,什麼是”餘弦相似性”。
為了簡單起見,我們先從句子著手。
句子A:我喜歡看電視,不喜歡看電影。
句子B:我不喜歡看電視,也不喜歡看電影。
請問怎樣才能計算上面兩句話的相似程度?
基本思路是:如果這兩句話的用詞越相似,它們的內容就應該越相似。因此,可以從詞頻入手,計算它們的相似程度。
第一步,分詞。
句子A:我/喜歡/看/電視,不/喜歡/看/電影。
句子B:我/不/喜歡/看/電視,也/不/喜歡/看/電影。
第二步,列出所有的詞。
我,喜歡,看,電視,電影,不,也。
第三步,計算詞頻。
句子A:我 1,喜歡 2,看 2,電視 1,電影 1,不 1,也 0。
句子B:我 1,喜歡 2,看 2,電視 1,電影 1,不 2,也 1。
第四步,寫出詞頻向量。
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
到這裡,問題就變成瞭如何計算這兩個向量的相似程度。
我們可以把它們想象成空間中的兩條線段,都是從原點([0, 0, …])出發,指向不同的方向。兩條線段之間形成一個夾角,如果夾角為0度,意味著方向相同、線段重合;如果夾角為90度,意味著形成直角,方向完全不相似;如果夾角為180度,意味著方向正好相反。因此,我們可以透過夾角的大小,來判斷向量的相似程度。夾角越小,就代表越相似。
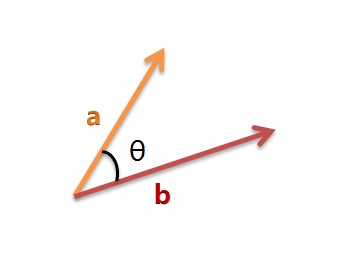
以二維空間為例,上圖的a和b是兩個向量,我們要計算它們的夾角θ。餘弦定理告訴我們,可以用下麵的公式求得:


假定a向量是[x1, y1],b向量是[x2, y2],那麼可以將餘弦定理改寫成下麵的形式:


數學家已經證明,餘弦的這種計算方法對n維向量也成立。假定A和B是兩個n維向量,A是 [A1, A2, …, An] ,B是 [B1, B2, …, Bn] ,則A與B的夾角θ的餘弦等於:
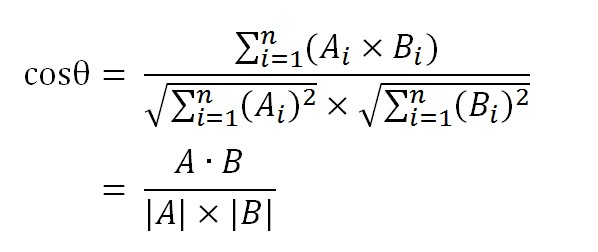
使用這個公式,我們就可以得到,句子A與句子B的夾角的餘弦。

餘弦值越接近1,就表明夾角越接近0度,也就是兩個向量越相似,這就叫”餘弦相似性”。所以,上面的句子A和句子B是很相似的,事實上它們的夾角大約為20.3度。
由此,我們就得到了”找出相似文章”的一種演演算法:
(1)使用TF-IDF演演算法,找出兩篇文章的關鍵詞;
(2)每篇文章各取出若干個關鍵詞(比如20個),合併成一個集合,計算每篇文章對於這個集合中的詞的詞頻(為了避免文章長度的差異,可以使用相對詞頻);
(3)生成兩篇文章各自的詞頻向量;
(4)計算兩個向量的餘弦相似度,值越大就表示越相似。
“餘弦相似度”是一種非常有用的演演算法,只要是計算兩個向量的相似程度,都可以採用它。
自動摘要
有時候,很簡單的數學方法,就可以完成很複雜的任務。
前兩部分就是很好的例子。僅僅依靠統計詞頻,就能找出關鍵詞和相似文章。雖然它們算不上效果最好的方法,但肯定是最簡便易行的方法。
接下來討論如何透過詞頻,對文章進行自動摘要(Automatic summarization)。
如果能從3000字的文章,提煉出150字的摘要,就可以為讀者節省大量閱讀時間。由人完成的摘要叫”人工摘要”,由機器完成的就叫”自動摘要”。許多網站都需要它,比如論文網站、新聞網站、搜尋引擎等等。2007年,美國學者的論文《A Survey on Automatic Text Summarization》(Dipanjan Das, Andre F.T. Martins, 2007)總結了目前的自動摘要演演算法。其中,很重要的一種就是詞頻統計。
這種方法最早出自1958年的IBM公司科學家H.P. Luhn的論文《The Automatic Creation of Literature Abstracts》。
Luhn博士認為,文章的資訊都包含在句子中,有些句子包含的資訊多,有些句子包含的資訊少。”自動摘要”就是要找出那些包含資訊最多的句子。
句子的資訊量用”關鍵詞”來衡量。如果包含的關鍵詞越多,就說明這個句子越重要。Luhn提出用”簇”(cluster)表示關鍵詞的聚集。所謂”簇”就是包含多個關鍵詞的句子片段。
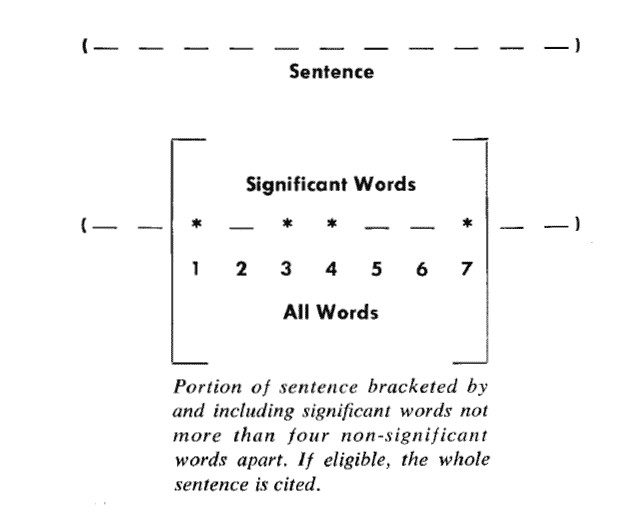
上圖就是Luhn原始論文的插圖,被框起來的部分就是一個”簇”。只要關鍵詞之間的距離小於”門檻值”,它們就被認為處於同一個簇之中。Luhn建議的門檻值是4或5。也就是說,如果兩個關鍵詞之間有5個以上的其他詞,就可以把這兩個關鍵詞分在兩個簇。
下一步,對於每個簇,都計算它的重要性分值。

以前圖為例,其中的簇一共有7個詞,其中4個是關鍵詞。因此,它的重要性分值等於 ( 4 x 4 ) / 7 = 2.3。
然後,找出包含分值最高的簇的句子(比如5句),把它們合在一起,就構成了這篇文章的自動摘要。具體實現可以參見《Mining the Social Web: Analyzing Data from Facebook, Twitter, LinkedIn, and Other Social Media Sites》(O’Reilly, 2011)一書的第8章,python程式碼見github。
Luhn的這種演演算法後來被簡化,不再區分”簇”,只考慮句子包含的關鍵詞。下麵就是一個例子(採用偽碼表示),只考慮關鍵詞首先出現的句子。
Summarizer(originalText, maxSummarySize):
// 計算原始文字的詞頻,生成一個陣列,比如[(10,’the’), (3,’language’), (8,’code’)…]
wordFrequences = getWordCounts(originalText)// 過濾掉停用詞,陣列變成[(3, ‘language’), (8, ‘code’)…]
contentWordFrequences = filtStopWords(wordFrequences)// 按照詞頻進行排序,陣列變成[‘code’, ‘language’…]
contentWordsSortbyFreq = sortByFreqThenDropFreq(contentWordFrequences)// 將文章分成句子
sentences = getSentences(originalText)// 選擇關鍵詞首先出現的句子
setSummarySentences = {}
foreach word in contentWordsSortbyFreq:
firstMatchingSentence = search(sentences, word)
setSummarySentences.add(firstMatchingSentence)
if setSummarySentences.size() = maxSummarySize:
break// 將選中的句子按照出現順序,組成摘要
summary = “”
foreach sentence in sentences:
if sentence in setSummarySentences:
summary = summary + ” ” + sentencereturn summary
類似的演演算法已經被寫成了工具,比如基於Java的Classifier4J庫的SimpleSummariser模組、基於C語言的OTS庫、以及基於classifier4J的C#實現和python實現。
親愛的讀者朋友們,您們有什麼想法,請點選【寫留言】按鈕,寫下您的留言。
資料人網(http://shujuren.org)誠邀各位資料人來平臺分享和傳播優質資料知識。
公眾號推薦:
360區塊鏈,專註於360度分享區塊鏈內容。

腳印英語,專註於分享實用口語內容。

閱讀原文,更多精彩!
分享是收穫,傳播是價值!
