1.這是一個系列,有興趣的朋友可以持續關註
2.如果你有HikariCP使用上的問題,可以給我留言,我們一起溝通討論
3.希望大家可以提供我一些案例,我也希望可以支援你們做一些調優
業務方關註哪些資料庫指標?
首先分享一下自己之前的一段筆記(找不到取用出處了)
-
系統中多少個執行緒在進行與資料庫有關的工作?其中,而多少個執行緒正在執行 SQL 陳述句?這可以讓我們評估資料庫是不是系統瓶頸。
-
多少個執行緒在等待獲取資料庫連線?獲取資料庫連線需要的平均時長是多少?資料庫連線池是否已經不能滿足業務模組需求?如果存在獲取資料庫連線較慢,如大於 100ms,則可能說明配置的資料庫連線數不足,或存在連線洩漏問題。
-
哪些執行緒正在執行 SQL 陳述句?執行了的 SQL 陳述句是什麼?資料庫中是否存在系統瓶頸或已經產生鎖?如果個別 SQL 陳述句執行速度明顯比其它陳述句慢,則可能是資料庫查詢邏輯問題,或者已經存在了鎖表的情況,這些都應當在系統最佳化時解決。
-
最經常被執行的 SQL 陳述句是在哪段原始碼中被呼叫的?最耗時的 SQL 陳述句是在哪段原始碼中被呼叫的?在浩如煙海的原始碼中找到某條 SQL 並不是一件很容易的事。而當存在問題的 SQL 是在底層程式碼中,我們就很難知道是哪段程式碼呼叫了這個 SQL,並產生了這些系統問題。
在研究HikariCP的過程中,這些業務關註點我發現在連線池這層逐漸找到了答案。
友情提示:歡迎關註公眾號【芋道原始碼】。?關註後,拉你進【原始碼圈】微信群討論技術和原始碼。
友情提示:歡迎關註公眾號【芋道原始碼】。?關註後,拉你進【原始碼圈】微信群討論技術和原始碼。
友情提示:歡迎關註公眾號【芋道原始碼】。?關註後,拉你進【原始碼圈】微信群討論技術和原始碼。
監控指標
| HikariCP指標 | 說明 | 型別 | 備註 |
|---|---|---|---|
| hikaricp_connection_timeout_total | 每分鐘超時連線數 | Counter | |
| hikaricp_pending_threads | 當前排隊獲取連線的執行緒數 | GAUGE | 關鍵指標,大於10則 報警 |
| hikaricp_connection_acquired_nanos | 連線獲取的等待時間 | Summary | pool.Wait 關註99極值 |
| hikaricp_active_connections | 當前正在使用的連線數 | GAUGE | |
| hikaricp_connection_creation_millis | 建立連線成功的耗時 | Summary | 關註99極值 |
| hikaricp_idle_connections | 當前空閑連線數 | GAUGE | 關鍵指標,預設10,因為降低為0會大大增加連線池建立開銷 |
| hikaricp_connection_usage_millis | 連線被覆用的間隔時長 | Summary | pool.Usage 關註99極值 |
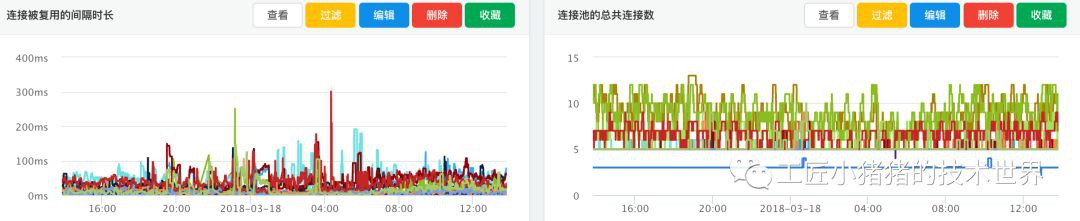
| hikaricp_connections | 連線池的總共連線數 | GAUGE |


重點關註
hikaricp_pending_threads
該指標持續飆高,說明DB連線池中基本已無空閑連線。
拿之前業務方應用pisces不可用的例子來說(如下圖所示),當時所有執行緒都在排隊等待,該指標已達172,此時呼叫方已經產生了大量超時及熔斷,雖然業務方沒有馬上找到拿不到連線的根本原因,但是這個告警出來之後及時進行了重啟,避免產生更大的影響。

hikaricp_connection_acquired_nanos(取99位數)
下圖是Hikari原始碼com.zaxxer.hikari.pool.HikariPool#getConnection部分,
public Connection getConnection(final long hardTimeout) throws SQLException
{
suspendResumeLock.acquire();
final long startTime = currentTime();
try {
long timeout = hardTimeout;
do {
PoolEntry poolEntry = connectionBag.borrow(timeout, MILLISECONDS);
if (poolEntry == null) {
break; // We timed out... break and throw exception
}
final long now = currentTime();
if (poolEntry.isMarkedEvicted() || (elapsedMillis(poolEntry.lastAccessed, now) > ALIVE_BYPASS_WINDOW_MS && !isConnectionAlive(poolEntry.connection))) {
closeConnection(poolEntry, poolEntry.isMarkedEvicted() ? EVICTED_CONNECTION_MESSAGE : DEAD_CONNECTION_MESSAGE);
timeout = hardTimeout - elapsedMillis(startTime);
}
else {
metricsTracker.recordBorrowStats(poolEntry, startTime);
return poolEntry.createProxyConnection(leakTaskFactory.schedule(poolEntry), now);
}
} while (timeout > 0L);
metricsTracker.recordBorrowTimeoutStats(startTime);
throw createTimeoutException(startTime);
}
catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new SQLException(poolName + " - Interrupted during connection acquisition", e);
}
finally {
suspendResumeLock.release();
}
}
從上述程式碼可以看到,suspendResumeLock.acquire()走到poolEntry == null時已經超時了,拿到一個poolEntry後先判斷是否已經被標記為待清理或已經超過了設定的最大存活時間(應用配置的最大存活時間不應超過DBA在DB端配置的最大連線存活時間),若是直接關閉繼續呼叫borrow,否則才會傳回該連線,metricsTracker.recordBorrowTimeoutStats(startTime);該段程式碼的意義就是此指標的記錄處。
Vesta模版中該指標單位配為了毫秒,此指標和排隊執行緒數結合,可以初步提出 增大連線數 或 最佳化慢查詢/慢事務 的最佳化方案等。
-
當 排隊執行緒數多 而 獲取連線的耗時較短 時,可以考慮增大連線數
-
當 排隊執行緒數少 而 獲取連線的耗時較長 時,此種場景不常見,舉例來說,可能是某個介面QPS較低,連線數配的小於這個QPS,而這個連線中有較慢的查詢或事務,這個需要具體問題具體分析
-
當 排隊執行緒數多 且 獲取連線的耗時較長時,這種場景比較危險,有可能是某個時間點DB壓力大或者網路抖動造成的,排除這些場景,若長時間出現這種情況則可認為 連線配置不合理/程式是沒有達到上線標準 ,如果可以從業務邏輯上最佳化慢查詢/慢事務是最好的,否則可以嘗試 增大連線數 或 應用擴容 。
hikaricp_idle_connections
Hikari是可以配置最小空閑連線數的,當此指標長期比較高(等於最大連線數)時,可以適當減小配置項中最小連線數。
hikaricp_active_connections
此指標長期在設定的最大連線數上下波動時,或者長期保持在最大執行緒數時,可以考慮增大最大連線數。
hikaricp_connection_usage_millis(取99位數)
該配置的意義在於表明 連線池中的一個連線從 被傳回連線池 到 再被覆用 的時間間隔,對於使用較少的資料源,此指標可能會達到秒級,可以結合流量高峰期的此項指標與啟用連線數指標來確定是否需要減小最小連線數,若高峰也是秒級,說明對比資料源使用不頻繁,可考慮減小連線數。
hikaricp_connection_timeout_total
該配置的意義在於表明 連線池中總共超時的連線數量,此處的超時指的是連線建立超時。經常連線建立超時,一個排查方向是和運維配合檢查下網路是否正常。
hikaricp_connection_creation_millis(取99位數)
該配置的意義在於表明 建立一個連線的耗時。主要反映當前機器到資料庫的網路情況,在IDC意義不大,除非是網路抖動或者機房間通訊中斷才會有異常波動。
監控指標部分實戰案例
以下連線風暴和慢SQL兩種場景是可以採用HikariCP連線池監控的。
連線風暴
連線風暴,也可稱為網路風暴,當應用啟動的時候,經常會碰到各應用伺服器的連線數異常飆升,這是大規模應用叢集很容易碰到的問題。先來描述一個場景
在專案釋出的過程中,我們需要重啟應用,當應用啟動的時候,經常會碰到各應用伺服器的連線數異常飆升。假設連線數的設定為:min值3,max值10。正常的業務使用連線數在5個左右,當重啟應用時,各應用連線數可能會飆升到10個,瞬間甚至還有可能部分應用會報取不到連線。啟動完成後接下來的時間內,連線開始慢慢傳回到業務的正常值。這種場景,就是碰到了所謂的連線風暴。
連線風暴可能帶來的危害主要有:
-
在多個應用系統同時啟動時,系統大量佔用資料庫連線資源,可能導致資料庫連線數耗盡
-
資料庫建立連線的能力是有限的,並且是非常耗時和消耗CPU等資源的,突然大量請求落到資料庫上,極端情況下可能導致資料庫異常crash。
-
對於應用系統來說,多一個連線也就多佔用一點資源。在啟動的時候,連線會填充到max值,並有可能導致瞬間業務請求失敗。
與連線風暴類似的還有:
-
啟動時的preparedstatement風暴
-
快取穿透。在快取使用的場景中,快取KEY值失效的風暴(單個KEY值失效,PUT時間較長,導致穿透快取落到DB上,對DB造成壓力)。可以採用 布隆過濾器 、單獨設定個快取區域儲存空值,對要查詢的key進行預先校驗 、快取降級等方法。
-
快取雪崩。上條的惡化,所有原本應該訪問快取的請求都去查詢資料庫了,而對資料庫CPU和記憶體造成巨大壓力,嚴重的會造成資料庫宕機。從而形成一系列連鎖反應,造成整個系統崩潰。可以採用 加鎖排隊、 設定過期標誌更新快取 、 設定過期標誌更新快取 、二級快取(引入一致性問題)、 預熱、 快取與服務降級等解決方法。
案例一 某公司訂單業務(劉龘劉同學提供):
我們那時候採用彈性伸縮,資料庫連線池是預設的,有點業務出了點異常,導致某個不重要的業務彈出N臺機器,導致整個資料庫連線不可用,影響訂單主業務。
該案例就可以理解為是一次連線風暴,當時剛好那個服務跟訂單合用一個資料庫了,訂單服務只能申請到預設連線數,訪問訂單TPS上不去,老劉同學說“損失慘重才能刻骨銘心呀”。
案例二 切庫(DBA提供):
我司在切庫的時候產生過連線風暴,瞬間所有業務全部斷開重連,造成連線風暴,暫時透過加大連線數解決此問題。當然,單個應用重啟的時候可以忽略不計,因為,一個庫的依賴服務不可能同時重啟。
案例三 機房出故障(DBA提供):
以前機房出故障的時候,應用全部湧進來,有過一次連線炸掉的情況。
慢SQL
我司的瓶頸其實不在連線風暴,我們的併發並不是很高,和電商不太一樣。複雜 SQL 很多,清算、對賬的複雜SQL都不少,部分業務的SQL比較複雜。比如之前有過一次催收線上故障,就是由於慢SQL導致Hikari連線池佔滿,排隊執行緒指標飆升,當時是無法看到整個連線池的歷史趨勢的,也很難看到連線池實時指標,有了本監控大盤工具之後,業務方可以更方便得排查類似問題。
如何調優
經驗配置連線池引數及監控告警
首先分享一個小故事《扁鵲三兄弟》
春秋戰國時期,有位神醫被尊為“醫祖”,他就是“扁鵲”。一次,魏文王問扁鵲說:“你們家兄弟三人,都精於醫術,到底哪一位最好呢?”扁鵲答:“長兄最好,中兄次之,我最差。”文王又問:“那麼為什麼你最出名呢?”扁鵲答:“長兄治病,是治病於病情發作之前,由於一般人不知道他事先能鏟除病因,所以他的名氣無法傳出去;中兄治病,是治病於病情初起時,一般人以為他只能治輕微的小病,所以他的名氣只及本鄉裡;而我是治病於病情嚴重之時,一般人都看到我在經脈上穿針管放血,在面板上敷藥等大手術,所以以為我的醫術高明,名氣因此響遍全國。”
正文羅列的幾種監控項可以配上告警,這樣,能夠在業務方發現問題之前第一時間發現問題,這就是扁鵲三兄弟大哥、二哥的做法,我們正是要努力成為扁鵲的大哥、二哥那樣的人。
根據日常的運維經驗,大多數線上應用可以使用如下的Hikari的配置:
maximumPoolSize: 20
minimumIdle: 10
connectionTimeout: 30000
idleTimeout: 600000
maxLifetime: 1800000
連線池連線數有動態和靜態兩種策略。動態即每隔一定時間就對連線池進行檢測,如果發現連線數量小於最小連線數,則補充相應數量的新連線以保證連線池的正常運轉。靜態是發現空閑連線不夠時再去檢查。這裡提一下minimumIdle,hikari實際上是不推薦使用者去更改Hikari預設連線數的。
This property controls the minimum number of idle connections that HikariCP tries to maintain in the pool. If the idle connections dip below this value and total connections in the pool are less than maximumPoolSize, HikariCP will make a best effort to add additional connections quickly and efficiently. However, for maximum performance and responsiveness to spike demands, we recommend not setting this value and instead allowing HikariCP to act as a fixed size connection pool. Default: same as maximumPoolSize
該屬性的預設值為10,Hikari為了追求最佳效能和相應尖峰需求,hikari不希望使用者使用動態連線數,因為動態連線數會在空閑的時候減少連線、有大量請求過來會建立連線,但是但是建立連線耗時較長會影響RT。還有一個考慮就是隱藏風險,比如平時都是空載的 10個機器就是100個連線,其實資料庫最大連線數比如是150個,等滿載的時候就會報錯了,這其實就是關閉動態調節的能力,跟 jvm 線上 xmx和xms 配一樣是一個道理。動態調節不是完全沒用,比如不同服務連一個db然後,業務高峰是錯開的,這樣的情況其實比較少。
更多配置解析請參見本系列第二篇《【追光者系列】HikariCP連線池配置項》
壓測
連線池的分配與釋放,對系統的效能有很大的影響。合理的分配與釋放,可以提高連線的復用度,從而降低建立新連線的開銷,同時還可以加快使用者的訪問速度。
連線池的大小設定多少合適呢?再分配多了效果也不大,一個是應用伺服器維持這個連線數需要記憶體支援,並且維護大量的連線進行分配使用對cpu也是一個不小的負荷,因此不宜太大,雖然sleep執行緒增多對DBA來說目前線上已經可以忽略,但是能處理一下當然最好。如果太小,那麼在上述規模專案的併發量以及資料量上來以後會造成排隊現象,系統會變慢,資料庫連線會經常開啟和關閉,效能上有壓力,使用者體驗也不好。
如何評估資料庫連線池的效能是有專門的演演算法公式的,【追光者系列】後續會更新,不過經驗值一般沒有壓測準,連線池太大、太小都會存在問題。具體設定多少,要看系統的訪問量,可透過反覆測試,找到最佳點。
連線風暴問題的另一種探索
對於連線風暴,如果採用傳統的proxy樣式可以處理好這種問題,主要還是mysql的bio模型不支援大量連線。負載均衡 、故障轉移、服務自動擴容 都可以在這一層實現。
預告
-
《【追光者系列】HikariCP連線池配置項》
-
《【追光者系列】HikariCP連線池設定多大合適》
感謝
感謝監控組、DBA、業務方的同學提供的相關案例。

