
轉載宣告:本文轉載自「資料派THU」,搜尋「DatapiTHU」即可關註。
作者:韋瑋
來源:Python愛好者社群
本文共7800字,建議閱讀10+分鐘。
本文結合程式碼實體待你上手python資料挖掘和機器學習技術。
本文包含了五個知識點:
1. 資料挖掘與機器學習技術簡介
2. Python資料預處理實戰
3. 常見分類演演算法介紹
4. 對鳶尾花進行分類案例實戰
5. 分類演演算法的選擇思路與技巧
一、資料挖掘與機器學習技術簡介
什麼是資料挖掘?資料挖掘指的是對現有的一些資料進行相應的處理和分析,最終得到資料與資料之間深層次關係的一種技術。例如在對超市貨品進行擺放時,牛奶到底是和麵包擺放在一起銷量更高,還是和其他商品擺在一起銷量更高。資料挖掘技術就可以用於解決這類問題。具體來說,超市的貨品擺放問題可以劃分為關聯分析類場景。
在日常生活中,資料挖掘技術應用的非常廣泛。例如對於商戶而言,常常需要對其客戶的等級(svip、vip、普通客戶等)進行劃分,這時候可以將一部分客戶資料作為訓練資料,另一部分客戶資料作為測試資料。然後將訓練資料輸入到模型中進行訓練,在訓練完成後,輸入另一部分資料進行測試,最終實現客戶等級的自動劃分。其他類似的應用例子還有驗證碼識別、水果品質自動篩選等。
那麼機器學習技術又是什麼呢?一言以蔽之,凡是讓機器透過我們所建立的模型和演演算法對資料之間的關係或者規則進行學習,最後供我們利用的技術都是機器學習技術。其實機器學習技術是一個交叉的學科,它可以大致分為兩類:傳統的機器學習技術與深度學習技術,其中深度學習技術包含了神經網路相關技術。在本次課程中,著重講解的是傳統的機器學習技術及各種演演算法。
由於機器學習技術和資料挖掘技術都是對資料之間的規律進行探索,所以人們通常將兩者放在一起提及。而這兩種技術在現實生活中也有著非常廣闊的應用場景,其中經典的幾類應用場景如下圖所示:

1、分類:對客戶等級進行劃分、驗證碼識別、水果品質自動篩選等
機器學習和資料挖掘技術可以用於解決分類問題,如對客戶等級進行劃分、驗證碼識別、水果品質自動篩選等。
以驗證碼識別為例,現需要設計一種方案,用以識別由0到9的手寫體數字組成的驗證碼。有一種解決思路是,先將一些出現的0到9的手寫體數字劃分為訓練集,然後人工的對這個訓練集進行劃分,即將各個手寫體對映到其對應的數字類別下麵,在建立了這些對映關係之後,就可以透過分類演演算法建立相應的模型。這時候如果出現了一個新的數字手寫體,該模型可以對該手寫體代表的數字進行預測,即它到底屬於哪個數字類別。例如該模型預測某手寫體屬於數字1的這個類別,就可以將該手寫體自動識別為數字1。所以驗證碼識別問題實質上就是一個分類問題。
水果品質的自動篩選問題也是一個分類問題。水果的大小、顏色等特徵也可以對映到對應的甜度類別下麵,例如1這個類別可以代表甜,0這個類別代表不甜。在獲得一些訓練集的資料之後,同樣可以透過分類演演算法建立模型,這時候如果出現一個新的水果,就可以透過它的大小、顏色等特徵來自動的判斷它到底是甜的還是不甜的。這樣就實現了水果品質的自動篩選。
2、回歸:對連續型資料進行預測、趨勢預測等
除了分類之外,資料挖掘技術和機器學習技術還有一個非常經典的場景——回歸。在前文提到的分類的場景,其類別的數量都有一定的限制。比如數字驗證碼識別場景中,包含了0到9的數字類別;再比如字母驗證碼識別場景中,包含了a到z的有限的類別。無論是數字類別還是字母類別,其類別數量都是有限的。
現在假設存在一些資料,在對其進行對映後,最好的結果沒有落在某個0、1或者2的點上,而是連續的落在1.2、1.3、1.4…上面。而分類演演算法就無法解決這類問題,這時候就可以採用回歸分析演演算法進行解決。在實際的應用中,回歸分析演演算法可以實現對連續型資料進行預測和趨勢預測等。
3、聚類:客戶價值預測、商圈預測等
什麼是聚類?在上文中提過,要想解決分類問題,必須要有歷史資料(即人為建立的正確的訓練資料)。倘若沒有歷史資料,而需要直接將某物件的特徵劃分到其對應的類別,分類演演算法和回歸演演算法無法解決這個問題。這種時候有一種解決辦法——聚類,聚類方法直接根據物件特徵劃分出對應的類別,它是不需要經過訓練的,所以它是一種非監督的學習方法。
在什麼時候能用到聚類?假如資料庫中有一群客戶的特徵資料,現在需要根據這些客戶的特徵直接劃分出客戶的級別(如SVIP客戶、VIP客戶),這時候就可以使用聚類的模型去解決。另外在預測商圈的時候,也可以使用聚類的演演算法。
4、關聯分析:超市貨品擺放、個性化推薦等
關聯分析是指對物品之間的關聯性進行分析。例如,某超市記憶體放有大量的貨品,現在需要分析出這些貨品之間的關聯性,如麵包商品與牛奶商品之間的關聯性的強弱程度,這時候可以採用關聯分析演演算法,藉助於使用者的購買記錄等資訊,直接分析出這些商品之間的關聯性。在瞭解了這些商品的關聯性之後,就可以將之應用於超市的商品擺放,透過將關聯性強的商品放在相近的位置上,可以有效提升該超市的商品銷量。
此外,關聯分析還可以用於個性化推薦技術。比如,藉助於使用者的瀏覽記錄,分析各個網頁之間存在的關聯性,在使用者瀏覽網頁時,可以向其推送強關聯的網頁。例如,在分析了瀏覽記錄資料後,發現網頁A與網頁C之間有很強的關聯關係,那麼在某個使用者瀏覽網頁A時,可以向他推送網頁C,這樣就實現了個性化推薦。
5、自然語言處理:文字相似度技術、聊天機器人等
除了上述的應用場景之外,資料挖掘和機器學習技術也可以用於自然語言處理和語音處理等等。例如對文字相似度的計算和聊天機器人。
二、Python資料預處理實戰
在進行資料挖掘與機器學習之前,首先要做的一步是對已有資料進行預處理。倘若連初始資料都是不正確的,那麼就無法保證最後的結果的正確性。只有對資料進行預處理,保證其準確性,才能保證最後結果的正確性。
資料預處理指的是對資料進行初步處理,把臟資料(即影響結果準確率的資料)處理掉,否則很容易影響最終的結果。常見的資料預處理方法如下圖所示:

1、缺失值處理
缺失值是指在一組資料中,某行資料缺失的某個特徵值。解決缺失值有兩種方法,一是將該缺失值所在的這行資料刪除掉,二是將這個缺失值補充一個正確的值。
2、異常值處理
異常值產生的原因往往是資料在採集時發生了錯誤,如在採集數字68時發生了錯誤,誤將其採整合680。在處理異常值之前,自然需要先發現這些異常值資料,往往可以藉助畫圖的方法來發現這些異常值資料。在對異常值資料處理完成之後,原始資料才會趨於正確,才能保證最終結果的準確性。
3、資料整合
相較於上文的缺失值處理和異常值處理,資料整合是一種較為簡單的資料預處理方式。那麼資料整合是什麼?假設存在兩組結構一樣的資料A和資料B,且兩組資料都已載入進入記憶體,這時候如果使用者想將這兩組資料合併為一組資料,可以直接使用Pandas對其進行合併,而這個合併的過程實際上就是資料的整合。
接下來以淘寶商品資料為例,介紹一下上文預處理的實戰。
在進行資料預處理之前,首先需要從MySQL資料庫中匯入淘寶商品資料。在開啟MySQL資料庫之後,對其中的taob表進行查詢,得到瞭如下的輸出:

可以看到,taob表中有四個欄位。其中title欄位用於儲存淘寶商品的名稱;link欄位儲存淘寶商品的連結;price儲存淘寶商品的價格;comment儲存淘寶商品的評論數(一定程度上代表商品的銷量)。
那麼接下來如何將這些資料匯入進來?首先透過pymysql連線資料庫(如果出現亂碼,則對pymysql的原始碼進行修改),連線成功後,將taob中的資料全部檢索出來,然後藉助pandas中的read_sql()方法便可以將資料匯入到記憶體中。
read_sql()方法有兩個引數,第一個引數是sql陳述句,第二個引數是MySQL資料庫的連線資訊。具體程式碼如下圖:

1、缺失值處理實戰
對缺失值進行處理可以採用資料清洗的方式。以上面的淘寶商品資料為例,某件商品的評論數可能為0,但是它的價格卻不可能為0。然而實際上在資料庫記憶體在一些price值為0的資料,之所以會出現這種情況,是因為對部分資料的價格屬性沒有爬到。
那麼如何才能判斷出這些資料出現了缺失值呢?可以透過以下的方法來進行判別:
首先對於之前的taob表呼叫data.describe()方法,會出現如下圖所示的結果:

如何看懂這個統計結果?第一步要註意觀察price和comment欄位的count資料,如果兩者不相等,說明一定有資訊缺失;如果兩者相等,則暫時無法看出是否有缺失情況。例如price的count為9616.0000,而comment的count為9615.0000,說明評論資料至少缺失了一條。
其他各個欄位的含義分別為:mean代表平均數;std代表標準差;min代表最小值;max代表最大值。
那麼如何對這些缺失資料進行處理?一種方法是刪掉這些資料,還有一種方法是在缺失值處插入一個新值。第二種方法中的值可以是平均數或者中位數,而具體使用平均數還是中位數需要根據實際情況來決定。例如年齡這個資料(1到100歲),這類平穩、變化的級差不大的資料,一般插入平均數,而變化的間隔比較大的資料,一般插入中位數。
處理價格的缺失值的具體操作如下:

2、異常值處理實戰
跟缺失值的處理過程類似,想要處理異常值,首先要發現異常值。而異常值的發現往往是透過畫散點圖的方法,因為相似的資料會在散點圖中集中分佈到一塊區域,而異常的資料會分佈到遠離這塊區域的地方。根據這個性質,可以很方便的找到資料中的異常值。具體操作如下圖:

首先需要從資料中抽出價格資料和評論資料。通常的做法可以藉助迴圈去抽取,但是這種方法太複雜,有一種簡單的方法是這個資料框進行轉置,這時候原先的列資料就變成了現在的行資料,可以很方便的獲取價格資料和評論資料。接下來透過plot()方法繪製散點圖,plot()方法第一個引數代表橫坐標,第二個引數代表縱坐標,第三個引數代表圖的型別,”o”代表散點圖。最後透過show()方法將其展現出來,這樣就可以直觀的觀測到離群點。這些離群點對資料的分析沒有幫助,在實際操作中往往需要將這些離群點代表的資料刪除或者轉成正常的值。下圖是繪製的散點圖:

根據上圖所示,將評論大於100000,價格大於1000的資料都處理掉,就可以達到處理異常值的效果。而具體的兩種處理方法的實現過程如下:
第一種是改值法,將其改為中位數、平均數或者其他的值。具體操作如下圖所示:

第二種是刪除處理法,即直接刪除這些異常資料,也是推薦使用的一種方法。具體操作如下圖所示:

3、分佈分析
分佈分析是指對資料的分佈狀態進行分析,即觀察其是線性分佈還是正態分佈。一般採用畫直方圖的方式來進行分佈分析。直方圖的繪製有以下幾個步驟:計算極差、計算組距和繪製直方圖。具體的操作如下圖所示:

其中,藉助arrange()方法來制定樣式,arrange()方法第一個引數代表最小值,第二個引數代表最大值,第三個引數代表組距,接下來使用hist()方法來繪製直方圖。
taob表中的淘寶商品價格直方圖如下圖所示,大致上符合正態分佈:

taob表中的淘寶商品評論直方圖如下圖所示,大致上是遞減的曲線:

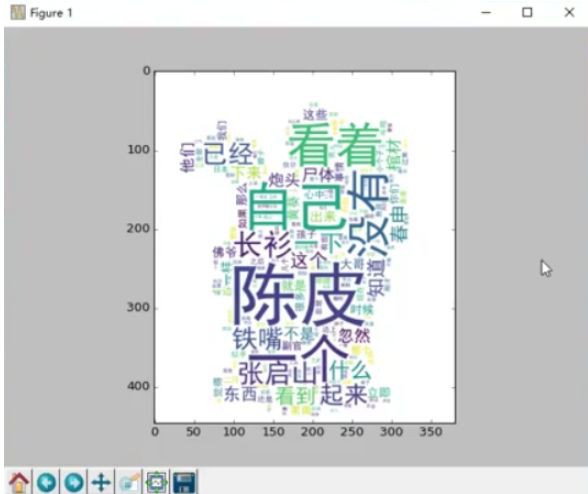
4、詞雲圖的繪製
有的時候常常需要根據一段文字資訊來進行詞雲圖的繪製,繪製的具體操作如下圖:

實現的大致流程是:先使用cut()對檔案進行切詞,在切詞完成之後,將這些詞語整理為固定格式,然後根據所需的詞雲圖的展現形式讀取相應的圖片(下圖中的詞雲圖是貓的形狀),接著使用wc.WordCloud()進行詞雲圖的轉換,最後透過imshow()展現出相應的詞雲圖。例如根據老九門.txt檔案繪製的詞雲圖效果如下圖所示:
三、常見分類演演算法介紹
常見的分類演演算法有很多,如下圖所示:

其中KNN演演算法和貝葉斯演演算法都是較為重要的演演算法,除此之外還有其他的一些演演算法,如決策樹演演算法、邏輯回歸演演算法和SVM演演算法。Adaboost演演算法主要是用於弱分類演演算法改造成強分類演演算法。
四、對鳶尾花進行分類案例實戰
假如現有一些鳶尾花的資料,這些資料包含了鳶尾花的一些特徵,如花瓣長度、花瓣寬度、花萼長度和花萼寬度這四個特徵。有了這些歷史資料之後,可以利用這些資料進行分類模型的訓練,在模型訓練完成後,當新出現一朵不知型別的鳶尾花時,便可以藉助已訓練的模型判斷出這朵鳶尾花的型別。這個案例有著不同的實現方法,但是藉助哪種分類演演算法進行實現會更好呢?
1、KNN演演算法
KNN演演算法簡介:
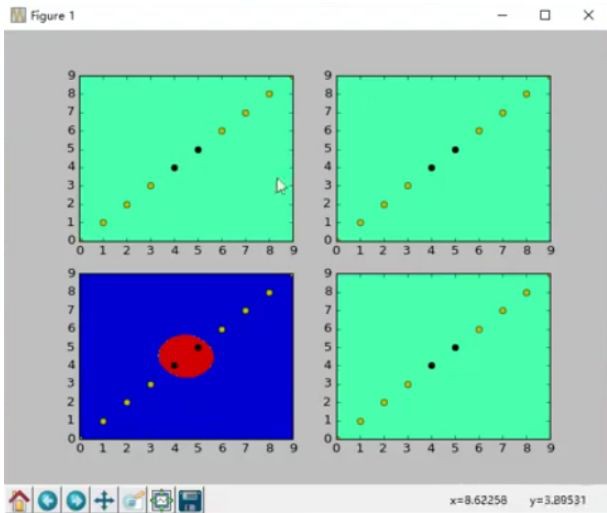
首先考慮這樣一個問題,在上文的淘寶商品中,有三類商品,分別是零食、名牌包包和電器,它們都有兩個特徵:price和comment。按照價格來排序,名牌包包最貴,電器次之,零食最便宜;按照評論數來排序,零食評論數最多,電器次之,名牌包包最少。然後以price為x軸、comment為y軸建立直角坐標系,將這三類商品的分佈繪製在坐標系中,如下圖所示:

顯然可以發現,這三類商品都集中分佈在不同的區域。如果現在出現了一個已知其特徵的新商品,用?表示這個新商品。根據其特徵,該商品在坐標系對映的位置如圖所示,問該商品最有可能是這三類商品中的哪種?
這類問題可以採用KNN演演算法進行解決,該演演算法的實現思路是,分別計算未知商品到其他各個商品的歐幾裡得距離之和,然後進行排序,距離之和越小,說明該未知商品與這類商品越相似。例如在經過計算之後,得出該未知商品與電器類的商品的歐幾裡得距離之和最小,那麼就可以認為該商品屬於電器類商品。
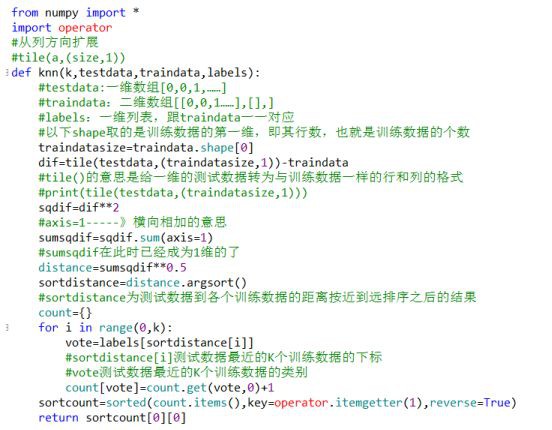
實現方式:
上述過程的具體實現如下:
當然也可以直接調包,這樣更加簡潔和方便,缺點在於使用的人無法理解它的原理:

使用KNN演演算法解決鳶尾花的分類問題:
首先載入鳶尾花資料。具體有兩種載入方案,一種是直接從鳶尾花資料集中讀取,在設定好路徑之後,透過read_csv()方法進行讀取,分離資料集的特徵和結果,具體操作如下:

還有一種載入方法是藉助sklearn來實現載入。sklearn的datasets中自帶有鳶尾花的資料集,透過使用datasets的load_iris()方法就可以將資料載入出來,隨後同樣獲取特徵和類別,然後進行訓練資料和測試資料的分離(一般做交叉驗證),具體是使用train_test_split()方法進行分離,該方法第三個引數代表測試比例,第四個引數是隨機種子,具體操作如下:

在載入完成之後,就可以呼叫上文中提到的KNN演演算法進行分類了。
2、貝葉斯演演算法
貝葉斯演演算法的介紹:
首先介紹樸素貝葉斯公式:P(B|A)=P(A|B)P(B)/P(A)。假如現在有一些課程的資料,如下表所示,價格和課時數是課程的特徵,銷量是課程的結果,若出現了一門新課,其價格高且課時多,根據已有的資料預測新課的銷量。
|
價格(A) |
課時數(B) |
銷量(C) |
|
低 |
多 |
高 |
|
高 |
中 |
高 |
|
低 |
少 |
高 |
|
低 |
中 |
低 |
|
中 |
中 |
中 |
|
高 |
多 |
高 |
|
低 |
少 |
中 |
顯然這個問題屬於分類問題。先對錶格進行處理,將特徵一與特徵二轉化成數字,即0代表低,1代表中,2代表高。在進行數字化之後,[[t1,t2],[t1,t2],[t1,t2]]——[[0,2],[2,1],[0,0]],然後對這個二維串列進行轉置(便於後續統計),得到[[t1,t1,t1],[t2,t2,t2]]——-[[0,2,0],[2,1,0]]。其中[0,2,0]代表著各個課程價格,[2,1,0]代表各個課程的課時數。
而原問題可以等價於求在價格高、課時多的情況下,新課程銷量分別為高、中、低的機率。即P(C|AB)=P(AB|C)P(C)/P(AB)=P(A|C)P(B|C)P(C)/P(AB)=》P(A|C)P(B|C)P(C),其中C有三種情況:c0=高,c1=中,c2=低。而最終需要比較P(c0|AB)、P(c1|AB)和P(c2|AB)這三者的大小,又
P(c0|AB)=P(A|C0)P(B|C0)P(C0)=2/4*2/4*4/7=1/7
P(c1|AB)=P(A|C1)P(B|C1)P(C1)=0=0
P(c2|AB)=P(A|C2)P(B|C2)P(C2)=0=0
顯然P(c0|AB)最大,即可預測這門新課的銷量為高。
實現方式:
跟KNN演演算法一樣,貝葉斯演演算法也有兩種實現方式,一種是詳細的實現:


另一種是整合的實現方式:

3、決策樹演演算法
決策樹演演算法是基於資訊熵的理論去實現的,該演演算法的計算流程分為以下幾個步驟:
-
先計算總資訊熵
-
計算各個特徵的資訊熵
-
計算E以及資訊增益,E=總資訊熵-資訊增益,資訊增益=總資訊熵-E
-
E如果越小,資訊增益越大,不確定因素越小
決策樹是指對於多特徵的資料,對於第一個特徵,是否考慮這個特徵(0代表不考慮,1代表考慮)會形成一顆二叉樹,然後對第二個特徵也這麼考慮…直到所有特徵都考慮完,最終形成一顆決策樹。如下圖就是一顆決策樹:

決策樹演演算法實現過程為:首先取出資料的類別,然後對資料轉化描述的方式(例如將“是”轉化成1,“否”轉化成0),藉助於sklearn中的DecisionTreeClassifier建立決策樹,使用fit()方法進行資料訓練,訓練完成後直接使用predict()即可得到預測結果,最後使用export_graphviz進行決策樹的視覺化。具體實現過程如下圖所示:

4、邏輯回歸演演算法
邏輯回歸演演算法是藉助於線性回歸的原理來實現的。假如存在一個線性回歸函式:y=a1x1+a2x2+a3x3+…+anxn+b,其中x1到xn代表的是各個特徵,雖然可以用這條直線去擬合它,但是由於y範圍太大,導致其魯棒性太差。若想實現分類,需要縮小y的範圍到一定的空間內,如[0,1]。這時候透過換元法可以實現y範圍的縮小:
令y=ln(p/(1-p))
那麼:e^y=e^(ln(p/(1-p)))
=> e^y=p/(1-p)
=>e^y*(1-p)=p => e^y-p*e^y=p
=> e^y=p(1+e^y)
=> p=e^y/(1+e^y)
=> p屬於[0,1]
這樣y就降低了範圍,從而實現了精準分類,進而實現邏輯回歸。
邏輯回歸演演算法對應的實現過程如下圖所示:

5、SVM演演算法
SVM演演算法是一種精準分類的演演算法,但是其可解釋性並不強。它可以將低維空間線性不可分的問題,變為高位空間上的線性可分。SVM演演算法的使用十分簡單,直接匯入SVC,然後訓練模型,併進行預測。具體操作如下:

儘管實現非常簡單,然而該演演算法的關鍵卻在於如何選擇核函式。核函式可分為以下幾類,各個核函式也適用於不同的情況:
-
線性核函式
-
多項式核函式
-
徑向基核函式
-
Sigmoid核函式
對於不是特別複雜的資料,可以採用線性核函式或者多項式核函式。對於複雜的資料,則採用徑向基核函式。採用各個核函式繪製的影象如下圖所示:
5、Adaboost演演算法
假如有一個單層決策樹的演演算法,它是一種弱分類演演算法(準確率很低的演演算法)。如果想對這個弱分類器進行加強,可以使用boost的思想去實現,比如使用Adaboost演演算法,即進行多次的迭代,每次都賦予不同的權重,同時進行錯誤率的計算並調整權重,最終形成一個綜合的結果。
Adaboost演演算法一般不單獨使用,而是組合使用,來加強那些弱分類的演演算法。
五、分類演演算法的選擇思路與技巧
首先看是二分類還是多分類問題,如果是二分類問題,一般這些演演算法都可以使用;如果是多分類問題,則可以使用KNN和貝葉斯演演算法。其次看是否要求高可解釋性,如果要求高可解釋性,則不能使用SVM演演算法。再看訓練樣本數量、再看訓練樣本數量,如果訓練樣本的數量太大,則不適合使用KNN演演算法。最後看是否需要進行弱-強演演算法改造,如果需要則使用Adaboost演演算法,否則不使用Adaboost演演算法。如果不確定,可以選擇部分資料進行驗證,併進行模型評價(耗時和準確率)。
綜上所述,可以總結出各個分類演演算法的優缺點為:
KNN:多分類,惰性呼叫,不宜訓練資料過大
貝葉斯:多分類,計算量較大,特徵間不能相關
決策樹演演算法:二分類,可解釋性非常好
邏輯回歸演演算法:二分類,特徵之間是否具有關聯無所謂
SVM演演算法:二分類,效果比較不錯,但可解釋性欠缺
Adaboost演演算法:適用於對弱分類演演算法進行加強
《Python人工智慧和全棧開發》2018年07月23日即將在北京開課,120天衝擊Python年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Python好文請點選【閱讀原文】哦
↓↓↓
