
作者 | 陳濤
引言
但凡是千禧年之前出生的國人,心裡大體都有一個武俠情結,那是一個由金庸、古龍的一本本武俠小說以及港臺武俠劇堆砌出來的武林世界。雖說現在的電影可以發達到讓觀眾看到各種奇幻特效,但回味起來,似乎還不如金庸筆下一個令狐沖給江湖朝堂帶來的翻覆動蕩刺激。
俠骨文心笑看雲霄飄一羽, 孤懷統攬曾經滄海慨平生,武俠的迷人在於一個個小人物不單單被分成正邪兩派,每個人都有自己的獨立意志,透過不懈努力,最終得以在江湖這個大舞臺上各展身手,江山人才代出,各領風騷數年,刀光劍影間,讓人大呼好不過癮。
計算機技術領域,何嘗又不是一個江湖。往具體了說,比如有 Windows 和 Linux 系統級別的纏鬥;往抽象了說,有私有雲和IOE的概念對壘等。雖說技術不像俠客論劍般交手那麼直接,但是背後的暗潮湧動還是能讓人嗅到一絲火花的氣息。
今天我們要討論的當然不是江湖,而是要掰扯掰扯“資料湖”。
資料湖下的兩大派系
資料湖這一概念最早應該是在 2011 年由 CITO Research 網站的 CTO 和作家 Dan Woods 提出[1]。簡單來說,資料湖是一個資訊系統,並且符合下麵兩個特徵:
在我的理解中,目前的資料湖形態大體分為以下三種:
計算儲存一家親

計算資源和儲存資源整合在一起,以一個叢集來應對不同業務需求。可以想象,如果後期公司體量增大,不同的業務線對資料湖有不同的計算需求,業務之前會存在對計算資源的爭搶;同時,後期擴容時,計算和儲存得相應地一同擴充套件,也不是那麼的方便。
計算儲存一家親 Pro

為了應對上述方案中的資源爭搶問題,一般的解決方案就是為每個業務線分配一個資料湖,叢集的隔離能夠讓每個業務線有自己的計算資源,可以保證很好的業務隔離性。但是隨之而來的問題也是顯而易見的:資料孤島。試想幾個業務線可能需要同一個資料集來完成各自的分析,但是由於儲存叢集也被一個個分開,那麼勢必需要將這個資料集挨個複製到各個叢集中去。如此,資料的冗餘就太大了,儲存開銷太大。同時,計算和儲存的擴容問題也仍然存在。
計算儲存分家

俗話說的好,距離產生美。在這個樣式中,計算和儲存被分隔開來。每個業務線可以有自己的計算叢集,來滿足其業務需求。而後臺都指向同一個共享儲存池,由此解決了第二個方案中的資料冗餘問題。並且由於計算、儲存分離,在後期擴容時,也可以各自分別擴容。這一分離性也符合彈性計算的特徵,讓按需分配成為可能。
我們將方案一和方案二可以歸為“計算儲存融合”這一派系,目前最有代表的應該就是 Hadoop 的 HDFS,這套大資料預設的儲存後臺有著高容錯、易擴充套件等優點,十分適合部署在廉價裝置上;而方案三可以單獨拿出來,歸為“計算儲存分離”派系,最有代表的是 Amazon EMR。EMR 藉助 AWS 得天獨厚的雲端計算能力,並且輔以 S3 物件儲存支援,讓大資料分析變得十分簡單、便宜。
在私有雲場景中,我們一般會採用虛擬化技術來建立一個個計算叢集,來支援上層大資料應用的計算需求。儲存這邊一般採用 Ceph 的物件儲存服務來提供資料湖的共享儲存後臺,然後透過S3A來提供兩者之間的連線,能夠讓Hadoop的應用能夠無縫訪問 Ceph 物件儲存服務。

綜上所述,我們可以看到在“資料湖”這一概念下,其實隱約已經分成了兩個派系:“計算儲存融合”, “計算儲存分離”。下麵,讓我們談談這兩個派系的優缺點。
青梅煮酒
在這一節,我們會把“計算儲存融合”和“計算儲存分離”這兩個框架擺上臺面,來討論一下他們各自的優缺點。
計算儲存融合 – HDFS

HDFS 客戶端往 HDFS 寫入資料時,一般分為以下幾個簡要步驟:
HDFS 讀取資料步驟不在此贅述。對於 HDFS 寫入資料的步驟,我認為重要比較重要的有以下幾點:
作為“計算儲存融合”的代表 HDFS,其中心思想是透過d ata locality 這一概念來實現的,也就是說,Hadoop 在執行 Mapper 任務時,會儘量讓計算任務落在更接近對應的資料節點,由此來減少資料在網路間的傳輸,達到很大的讀取效能。而正是由於 data locality 這一特性,那麼就需要讓 block 足夠大(預設 128M),如果太小的話,那麼 data locality 的效果就會大打折扣。
但是大的 block 也會帶來 2 個弊端:
計算儲存分離 – S3A
我們在前文中已經介紹過,在私有雲部署中,資料湖的計算儲存分離框架一般由 Ceph 的物件儲存來提供共享儲存。而 Ceph 的物件儲存服務是由 RGW 提供的,RGW 提供了 S3 介面,可以讓大資料應用透過 S3A 來訪問 Ceph 物件儲存。由於儲存與計算分離,那麼檔案的 block 資訊不再需要存放到 NameNode 上,NameNode 在 S3A 中不再需要,其效能瓶頸也不復存在。
Ceph 的物件儲存服務為資料的管理提供了極大的便利。比如 cloudsync 模組可以讓 Ceph 物件儲存中的資料十分方便地上傳到其他公有雲;LCM 特性也使得資料冷熱分析、遷移成為可能等等。另外,RGW 支援糾刪碼來做資料冗餘,並且已經是比較成熟的方案了。雖然 HDFS 也在最近支援了糾刪碼,但是其成熟些有待考證,一般 HDFS 客戶也很少會去使用糾刪碼,更多地還是採用多副本冗餘。

我們透過這張圖來簡單分析一下 S3A 上傳資料的步驟: HDFS 客戶端在上傳資料時,需要透過呼叫 S3A 把請求封裝成 HTTP 然後傳送給 RGW,然後由 RGW 拆解後轉為 rados 請求傳送給 Ceph 叢集,從而達到資料上傳的目的。
由於所有的資料都需要先經過 RGW,然後再由 RGW 把請求遞交給 OSD,RGW 顯然很容易成為效能瓶頸。當然我們可以透過部署多個 RGW 來把負載均攤,但是在請求 IO 路徑上,請求無法直接從客戶端傳送到 OSD,在結構上永遠多了 RGW 這一跳。
另外,由於物件儲存的先天特性,List Objects 和 Rename 的代價比較大,相對來說會比 HDFS 慢。並且在社群版本中,RGW 無法支援追加上傳,而追加上傳在某些大資料場景下還是需要的。
由此,我們羅列一下 HDFS 和 S3A 的優缺點:
| 優勢 | 劣勢 | |
| HDFS | 1.data locality特性讓資料讀取效率很高
2.客戶端寫入、讀取資料時直接與DataNode互動 |
1.NameNode存放大小元資料、block資訊,可能會成為效能瓶頸
2.計算儲存沒有分離,後期擴充套件性不好,沒有彈性 3.由於block大,資料落盤時的均衡性不好,寫入頻寬也不夠大。 |
|
S3A |
1.儲存於計算分離,方便後期各自擴充套件
2.RGW能夠更方便地管理資料 3.成熟的糾刪碼方案,讓儲存利用率更高 |
1.所有請求都需要先發往RGW再發往OSD
2.社群版不支援追加上傳 3.List Object和rename代價大,比較慢 |
顯然,S3A 消除了計算和儲存必須一起擴充套件的問題,並且在儲存管理上有著更大的優勢,但是所有請求必須先透過 RGW,然後再交由 OSD,不像 HDFS 那般,可以直接讓 HDFS 客戶端與 DataNode 直接傳輸資料。顯然到了這裡,我們可以看到“計算儲存融合”與“計算儲存分離”兩大陣營都尤其獨特的優勢,也有不足之處。
那麼,有沒有可能將兩者優點結合在一起?也就是說,保留物件儲存的優良特性,同時又能讓客戶端不再需要 RGW 來完成對Ceph 物件儲存的訪問?
柳暗花明
聊到 UMStor Hadapter 之前,我們還是需要先說一下 NFS-Ganesha 這款軟體,因為我們正是由它而獲取到了靈感。NFS-Ganesha 是一款由紅帽主導的開源的使用者態 NFS 伺服器軟體,相比較 NFSD,NFS-Ganesha 有著更為靈活的記憶體分配、更強的可移植性、更便捷的訪問控制管理等優點。
NFS-Ganesha 能支援許多後臺儲存系統,其中就包括 Ceph 的物件儲存服務。

上圖是使用 NFS-Ganesha 來共享一個 Ceph 物件儲存下的 bucket1 的使用示例,可以看到 NFS-Ganesha 使用了 librgw 來實現對 Ceph 物件儲存的訪問。librgw 是一個由 Ceph 提供的函式庫,其主要目的是為了可以讓使用者端透過函式呼叫來直接訪問 Ceph 的物件儲存服務。librgw 可以將客戶端請求直接轉化成 librados 請求,然後透過 socket 與 OSD 通訊,也就是說,我們不再需要傳送 HTTP 請求傳送給 RGW,然後讓 RGW 與 OSD 通訊來完成一次訪問了。

從上圖可得知,App over librgw 在結構上是優於 App over RGW 的,請求在 IO 呼叫鏈上少了一跳,因此從理論上來說,使用 librgw 可以獲得更好的讀寫效能。
這不正是我們所尋求的方案嗎?如果說“計算儲存融合”與“計算儲存分離”兩者的不可調和是一把鎖,那麼 librgw 就是開這一把鎖的鑰匙。
UMStor Hadapter
基於 librgw 這個核心,我們打造了一款新的 Hadoop 儲存外掛 – Hadapter。libuds 是整個 Hadapter 的核心函式庫,它封裝 librgw。當 Hadoop 客戶端傳送以 uds:// 為字首的請求時,Hadoop 叢集就會將請求下發給 Hadapter,然後由 libuds 呼叫 librgw 的函式,讓 librgw 直接呼叫 librados 函式庫來請求 OSD,由此完成一個請求的完成處理。
Hadapter 本身只是一個 jar 包,只要將這個 jar 包放到對應大資料節點就可以直接使用,因此部署起來也十分便捷。同時我們還對 librgw 做了一些二次開發,比如,讓 librgw 能夠支援追加上傳,彌補了 S3A 在追加上傳上的短板。

我們對 HDFS、S3A、Hadapter 做了大量的效能對比測試,雖然不同的測試集有其獨特的 IO 特性,不過我們在大多數測試中都獲取到了類似的結果:HDFS > Hadapter > S3A。我們在這裡用一個比較典型的 MapReduce 測試: word count 10GB dataset 來看一下三者表現。

為了控制變數,所有的節點都採用相同的配置,同時 Ceph 這邊的冗餘策略也和 HDFS 保持一致,都採用三副本。Ceph 的版本為 12.2.3,而 Hadoop 則採用了 2.7.3 版本。所有計算節點均部署了 Hadapter。在該測試下,我們最終獲取到的結果為:
|
HDFS |
S3A |
Hadapter |
|
|
Time Cost |
3min 2.410s |
6min 10.698s |
3min 35.843s |
可以看到,HDFS 憑藉其 data locality 特性而獲取的讀效能,還是取得了最好的成績;而 Hadapter 這邊雖然比 HDFS 慢,但不至於太差,只落後了 35s;而 S3A 這邊則差出了一個量級,最終耗時為 HDFS 的兩倍。我們之前所說的的,理論上 librgw 比 RGW 會取得更好的讀寫效能,在這次測試中得到了印證。
客戶案例
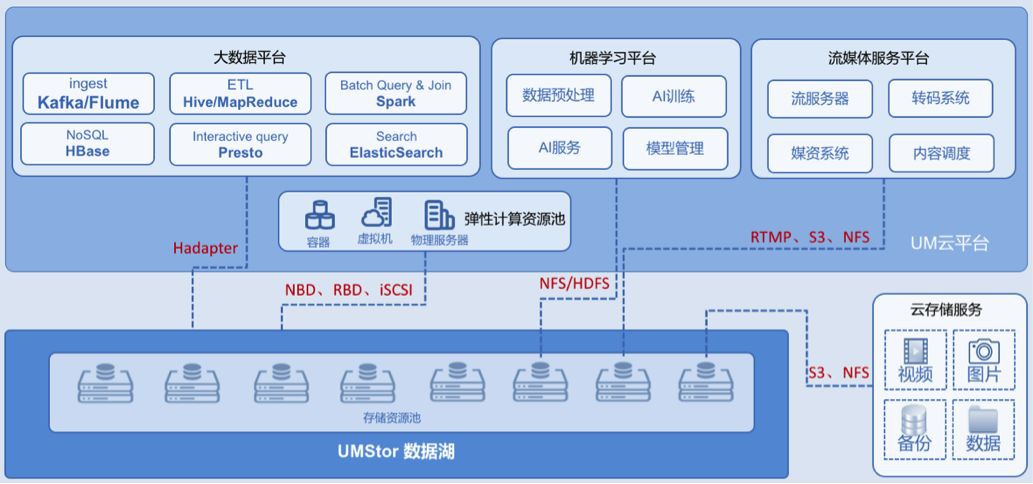
Hadapter 在去年迎來了一位重量級客人。該客戶是一家運營商專業影片公司,我們為它搭建了一套結合了大資料、機器學習、流媒體服務以及彈性計算資源池的儲存後臺解決方案。叢集規模達到 35PB 左右。
Hadapter 在這套大資料平臺下,主要為 Hbase、Hive、 Spark、 Flume、 Yarn 等應用提供後臺支援,目前已經上線。
結語
好了,現在我們把 HDFS、S3A、Hadapter 都拿出來比較一下:
|
優勢 |
劣勢 |
|
|
HDFS |
1.data locality特性讓資料讀取效率很高
2.客戶端寫入、讀取資料時直接與DataNode互動 |
1.NameNode存放大小元資料、block資訊,可能會成為效能瓶頸
2.計算儲存沒有分離,後期擴充套件性不好,沒有彈性 3.由於block大,資料落盤時的均衡性不好,寫入頻寬也不夠大。 |
|
S3A |
1.儲存於計算分離,方便後期各自擴充套件
2.RGW能夠更方便地管理資料 3.成熟的糾刪碼方案,讓儲存利用率更高 |
1.所有請求都需要先發往RGW再發往OSD
2.社群版不支援追加上傳 3.List Object和rename代價大,比較慢 |
|
Hadapter |
兼有RGW的優點
1.支援追加上傳 2.允許Hadoop客戶端直接與Ceph OSD通訊,繞開了RGW,從而取得更好的讀寫效能 |
1.List Object和rename代價大,比較慢 |
雖然上述列舉了不少 HDFS 的缺點,不過不得不承認,HDFS 仍舊是“計算儲存融合”陣營的定海神針,甚至可以說,在大部分大資料玩家眼中,HDFS 才是正統。不過,我們也在 Hadapter 上看到了“計算儲存分離”的新未來。目前 UMStor 團隊正主力打造 Hadapter 2.0,希望能帶來更好的相容性以及更強的讀寫效能。
這場較量,或許才拉開序幕。
