

HPC系統實際上就是一個平行計算系統,很多初學者剛接觸平行計算的時候會對MPI、OpenMPI和OpenMP產生非常大的疑惑,主要原因是對這幾個概念本身理解的不清晰以及這幾個縮寫的字母確實是如此的近似。下麵先透過一張圖來看看MPI、OpenMPI和OpenMP的區別。

MPI(Message Passing Interface)是資訊傳遞介面,是獨立於語言的通訊協議(標準),是一個庫。MPI的實現有MPICH、MPI-1、MPI-2、OpenMPI、IntelMPI、platformMPI等等,OpenMPI(open Message Passing Interface)是MPI的一種實現,也是一種庫專案。
OpenMP(Open Multiprocessing)是一種應用程式介面(即Application Program Interface),是一種並行的實現和方法,也可以認為是共享儲存結構上的一種程式設計模型。
在當前的平行計算系統中,OpenMP和OpenMPI都是需要的(從上面的各自概念可以看出),OpenMP用於本地的平行計算(共享記憶體記憶體架構),支援目前所有平臺上的程式共享記憶體式平行計算,它相當於是給出了一個讓並行程式設計更加容易實現的模型,而OpenMPI則是用於機器之間的通訊(分散式記憶體架構)。
從系統架構來看,目前的商用伺服器大體可以分為三類,即對稱多處理器結構SMP (SymmetricMulti-Processor) ,非一致儲存訪問結構 NUMA(Non-Uniform MemoryAccess) ,以及海量並行處理結構MPP(Massive ParallelProcessing) 。

它們的特徵分別是共享儲存型多處理機有兩種模型,即均勻儲存器存取(Uniform-Memory-Access,簡稱UMA)模型和非均勻儲存器存取(Nonuniform-Memory-Access,簡稱NUMA)模型。而COMA和ccNUMA都是NUMA結構的改進。
SMP (SymmetricMulti-Processor)
SMP對稱多處理系統內有許多緊耦合多處理器,在這樣的系統中,所有的CPU共享全部資源,如匯流排,記憶體和I/O系統等,作業系統或管理資料庫的複本只有一個,這種系統有一個最大的特點就是共享所有資源。多個CPU之間沒有區別,平等地訪問記憶體、外設、一個作業系統。作業系統管理著一個佇列,每個處理器依次處理佇列中的行程。如果兩個處理器同時請求訪問一個資源(例如同一段記憶體地址),由硬體、軟體的鎖機制去解決資源爭用問題,SMP伺服器CPU利用率狀態如下。

所謂對稱多處理器結構,是指伺服器中多個CPU對稱工作,無主次或從屬關係。各CPU共享相同的物理記憶體,每個CPU訪問記憶體中的任何地址所需時間是相同的,因此 SMP 也被稱為一致儲存器訪問結構 (UMA:Uniform Memory Access) 。對 SMP 伺服器進行擴充套件的方式包括增加記憶體、使用更快的 CPU 、增加 CPU 、擴充 I/O(槽口數與匯流排數) 以及新增更多的外部裝置 (通常是磁碟儲存) 。
SMP伺服器的主要特徵是共享,系統中所有資源(CPU 、記憶體、 I/O 等)都是共享的。也正是由於這種特徵,導致了SMP 伺服器的主要問題,那就是它的擴充套件能力非常有限。對於SMP伺服器而言,每一個共享的環節都可能造成SMP伺服器擴充套件時的瓶頸,而最受限制的則是記憶體。由於每個 CPU 必須透過相同的記憶體匯流排訪問相同的記憶體資源,因此隨著 CPU 數量的增加,記憶體訪問衝突將迅速增加,最終會造成CPU資源的浪費。實驗證明,SMP伺服器CPU利用率最好的情況是2至4個CPU 。
NUMA(Non-UniformMemory Access)
NUMA技術可以把幾十個 CPU( 甚至上百個 CPU) 組合在一個伺服器內,彌補了SMP 在擴充套件能力上的限制,NUMA 伺服器 CPU 模組結構如下。
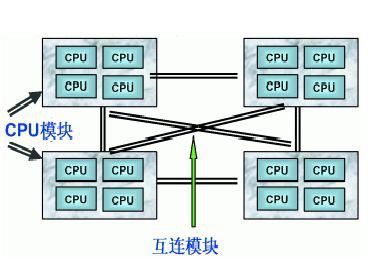
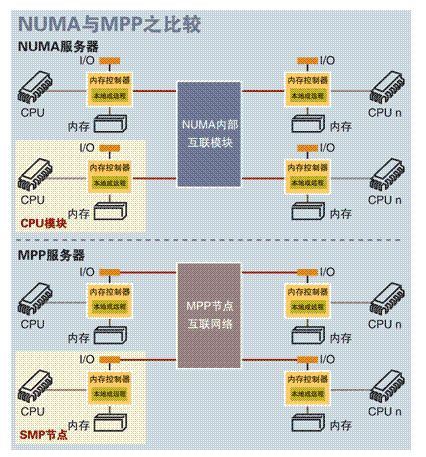
NUMA伺服器的基本特徵是具有多個 CPU模組,每個CPU模組由多個CPU(如4個)組成,並且具有獨立的本地記憶體、 I/O槽口等。由於其節點之間可以透過互聯模組(如稱為Crossbar Switch) 進行連線和資訊互動,因此每個CPU可以訪問整個系統的記憶體(這是NUMA系統與MPP系統的重要差別) 。顯然,訪問本地記憶體的速度將遠遠高於訪問遠地記憶體(系統內其它節點的記憶體)的速度,這也是非一致儲存訪問NUMA的由來。由於這個特點,為了更好地發揮系統效能,開發應用程式時需要儘量減少不同CPU模組之間的資訊互動。
利用NUMA技術,可以較好地解決原來SMP系統的擴充套件問題,在一個物理伺服器內可以支援上百個CPU。
但NUMA技術同樣有一定缺陷,由於訪問遠地記憶體的延時遠遠超過本地記憶體,因此當CPU 數量增加時,系統效能無法線性增加。如HP公司釋出Superdome伺服器時,曾公佈了它與HP其它UNIX伺服器的相對效能值,結果發現,64路CPU的Superdome (NUMA結構)的相對效能值是20,而8路N4000( 共享的SMP結構)的相對效能值是6.3。從這個結果可以看到,8倍數量的CPU換來的只是3倍效能的提升。
MPP(MassiveParallel Processing)
MPP和NUMA有所不同, MPP提供了另外一種進行系統擴充套件的方式,它由多個 SMP 伺服器透過一定的節點網際網路絡進行連線,協同工作,完成相同的任務,從使用者的角度來看是一個伺服器系統。其基本特徵是由多個 SMP 伺服器(每個 SMP 伺服器稱節點)透過節點網際網路絡連線而成,每個節點只訪問自己的本地資源(記憶體、儲存等),是一種完全無共享(Share Nothing) 結構,因而擴充套件能力最好,理論上其擴充套件無限制,目前的技術可實現 512 個節點互聯,數千個CPU。
在MPP系統中,每個SMP節點也可以執行自己的作業系統、資料庫等。但和NUMA不同的是,它不存在異地記憶體訪問的問題。換言之,每個節點內的CPU不能訪問另一個節點的記憶體。節點之間的資訊互動是透過節點網際網路絡實現的,這個過程一般稱為資料重分配(Data Redistribution) 。
但是MPP伺服器需要一種複雜的機制來排程和平衡各個節點的負載和並行處理過程。目前一些基於MPP技術的伺服器往往透過系統級軟體(如資料庫)來遮蔽這種複雜性。舉例來說,Teradata就是基於MPP技術的一個關係資料庫軟體,基於此資料庫來開發應用時,不管後臺伺服器由多少個節點組成,開發人員所面對的都是同一個資料庫系統,而不需要考慮如何排程其中某幾個節點的負載。
MPP大規模並行處理系統是由許多松耦合的處理單元組成的,要註意的是這裡指的是處理單元而不是處理器。每個單元內的 CPU都有自己私有的資源,如匯流排,記憶體,硬碟等。在每個單元內都有作業系統和管理資料庫的實體複本。這種結構最大的特點在於不共享資源。
NUMA、MPP和SMP之間效能的區別
-
NUMA的節點互聯機制是在同一個物理伺服器內部實現的,當某個CPU需要進行遠地記憶體訪問時,它必須等待,這也是NUMA伺服器無法實現CPU增加時效能線性擴充套件。
-
MPP的節點互聯機制是在不同的SMP伺服器外部透過I/O實現的,每個節點只訪問本地記憶體和儲存,節點之間的資訊互動與節點本身的處理是並行進行的。因此MPP在增加節點時效能基本上可以實現線性擴充套件。
-
SMP所有的CPU資源是共享的,因此完全實現線性擴充套件。
MPP、SMP和NUMA應用的區別
NUMA架構可以在一個物理伺服器內整合許多CPU,使系統具有較高的事務處理能力,由於遠地記憶體訪問時延遠長於本地記憶體訪問,因此需要儘量減少不同 CPU模組之間的資料互動。顯然,NUMA架構更適用於OLTP事務處理環境,當用於資料倉庫環境時,由於大量複雜的資料處理必然導致大量的資料互動,將使CPU的利用率降低。
MPP系統不共享資源,因此對它而言,資源比SMP要多,當需要處理的事務達到一定規模時,MPP的效率要比SMP好。
由於MPP系統因為要在不同處理單元之間 傳送資訊,在通訊時間少的時候,那MPP系統可以充分發揮資源的優勢,達到高效率。也就是說: 操作相互之間沒有什麼關係,處理單元之間需要進行的通訊比較少,那採用MPP系統就要好。因此,MPP系統在決策支援和資料挖掘方面顯示了優勢。
MPP系統因為要在不同處理單元之間傳送資訊,所以它的效率要比SMP要差一點。在通訊時間多的時候,那MPP系統可以充分發揮資源的優勢。因此當前使用的OTLP程式中,使用者訪問一個中心資料庫,如果採用SMP系統結構,它的效率要比採用MPP結構要快得多。
前期詳細分享過<從高效能運算(HPC)技術演變解析方案、生態和行業發展趨勢>分析,並整理成電子書,請點選“閱讀原文”連結查閱。
>>>>>>>>>>>>>讀者福利<<<<<<<<<<<<<<

知識擴充套件閱讀
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多HPC技術資料。

求知若渴, 虛心若愚—Stay hungry, Stay foolish
