作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
早在年初的一文讀懂「Attention is All You Need」| 附程式碼實現中就已經承諾過會分享 CNN 在 NLP 中的使用心得,然而一直不得其便。這幾天終於下定決心來整理一下相關的內容了。
背景
事不宜遲,先來介紹一下模型的基本情況。
模型特點
本模型——我稱之為 DGCNN——是基於 CNN 和簡單的 Attention 的模型,由於沒有用到 RNN 結構,因此速度相當快,而且是專門為這種 WebQA 式的任務定製的,因此也相當輕量級。
SQUAD 排行榜前面的模型,如 AoA、R-Net 等,都用到了 RNN,並且還伴有比較複雜的註意力互動機制,而這些東西在 DGCNN 中基本都沒有出現。
這是一個在 GTX1060 上都可以幾個小時訓練完成的模型!
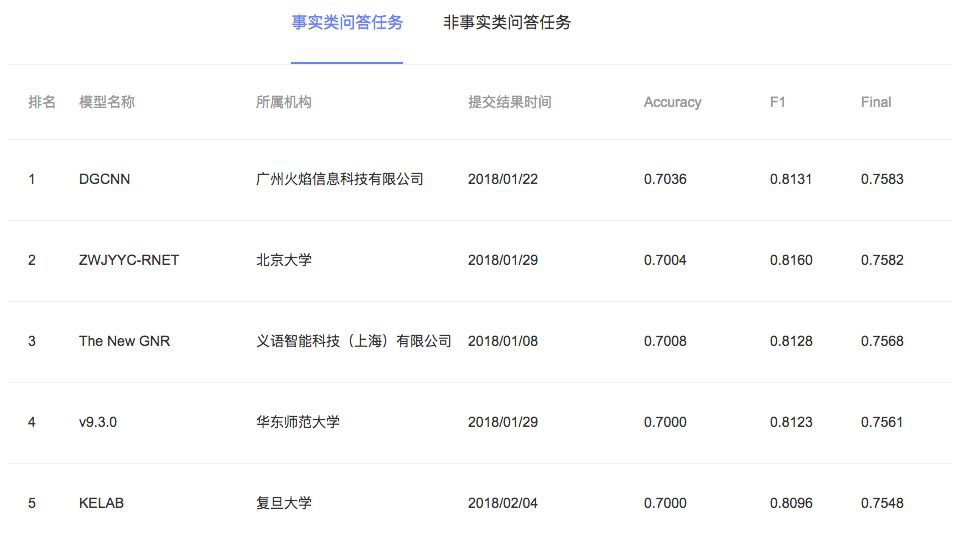
▲ 截止到2018.04.14的排行榜
DGCNN,全名為 Dilate Gated Convolutional Neural Network,即“膨脹門摺積神經網路”,顧名思義,融合了兩個比較新的摺積用法:膨脹摺積、門摺積,並增加了一些人工特徵和 trick,最終使得模型在輕、快的基礎上達到最佳的效果。
在本文撰寫之時,本文要介紹的模型還位於榜首,得分(得分是準確率與 F1 的平均)為 0.7583,而且是到目前為止唯一一個一直沒有跌出前三名、並且獲得周冠軍次數最多的模型。
比賽情況
其實這個模型是我代表“廣州火焰科技有限公司”參加 CIPS-SOGOU 問答比賽的產物。這個比賽在去年十月份開始,然而有點虎頭蛇尾,到現在依然還是不上不下的(沒有結束的跡象,也沒有繼續新任務的跡象)。
其實剛開始的兩三個月,競爭還是蠻激烈的,很多公司和大學都提交了模型,排行榜一直不斷掃清。所以我覺得 SOGOU 這樣虎頭蛇尾未免有點對不起大家當初提交的熱情。
最關鍵是,它究竟是有什麼計劃、有什麼變動,包括比賽的結束時間,一直都沒公開發出什麼通知,就一直把選手晾在那裡。我後來打聽到,截止時間是今年的 CIPS 舉辦前…一個比賽持續舉辦一年?
賽題簡述
到目前為止,SOGOU 的這個比賽只舉辦了事實類的部分,而事實類的部分基本上是跟百度之前開放的 WebQA 語料集 [1] 一樣的,即“一個問題 + 多段材料”的格式,希望從多段材料中共同決策出問題的精準答案(一般是一個物體片段)。

相比 WebQA,搜狗提供的訓練集噪聲大得多,這也使得預測難度加大。
此外,我認為這種 WebQA 式的任務是偏向於檢索匹配以及初步的語意理解技術,跟國外類似的任務 SQUAD(一段長材料 + 多個問題)是有比較大的區別的,SQUAD 的語料中,部分問題還涉及到了比較複雜的推理,因此 SQUAD 排行榜前面的模型都比較複雜、龐大。
模型
現在我們正式進入模型的介紹中。
架構總覽
先來看個模型總圖:

▲ DGCNN模型總圖
從示意圖可以看到,作為一個“閱讀理解”、“問答系統”模型,圖中的模型幾乎是簡單到不能再簡單了。
模型的整體架構源於 WebQA 的參考論文 Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Factoid Question [2]。這篇論文有幾個特點:
1. 直接將問題用 LSTM 編碼後得到“問題編碼”,然後拼接到材料的每一個詞向量中;
2. 人工提取了 2 個共現特徵;
3. 將最後的預測轉化為了一個序列標註任務,用 CRF 解決。
而 DGCNN 基本上就是沿著這個思路設計的,我們的不同點在於:
1. 把原模型中所有的 LSTM 部分都替換為 CNN;
2. 提取了更豐富的共現特徵(8 個);
3. 去掉 CRF,改為“0/1 標註”來分開識別答案的開始和終止位置,這可以看成一種“半指標半標註”的結構。
摺積結構
這部分我們來對圖中的 Conv1D Block 進行解析。
門機制
模型中採用的摺積結構,來自 FaceBook 的 Convolutional Sequence to Sequence Learning [3],而在《分享一個 slide:花式自然語言處理》[4] 一文中也提到過。
假設我們要處理的向量序列是 X=[x1,x2,…,xn],那麼我們可以給普通的一維摺積加個門:

註意這裡的兩個 Conv1D 形式一樣(比如摺積核數、視窗大小都一樣),但權值是不共享的,也就是說引數翻倍了,其中一個用 sigmoid 函式啟用,另外一個不加啟用函式,然後將它們逐位相乘。
因為 sigmoid 函式的值域是 (0,1),所以直覺上來看,就是給 Conv1D 的每個輸出都加了一個“閥門”來控制流量。這就是 GCNN 的結構了,或者可以將這種結構看成一個啟用函式,稱為 GLU(Gated Linear Unit)。
除了有直觀的意義外,用 GCNN 的一個好處是它幾乎不用擔心梯度消失問題,因為有一個摺積是不加任意啟用函式的,所以對這部分求導是個常數(乘以門),可以說梯度消失的機率非常小。如果輸入和輸出的維度大小一致,那麼我們就把輸入也加到裡邊,即使用殘差結構:
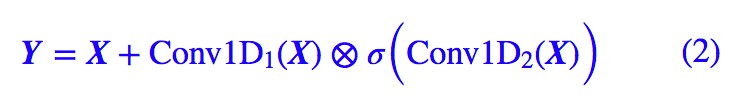
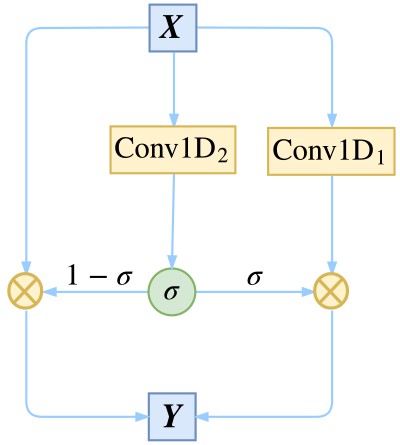
▲ 殘差與門摺積的結合,達到多通道傳輸的效果
值得一提的是,我們使用殘差結構,並不只是為瞭解決梯度消失,而是使得資訊能夠在多通道傳輸。我們可以將上式改寫為更形象的等價形式,以便我們更清晰看到資訊是如何流動的:

從 (3) 式中我們能更清楚看到資訊的流向:以 1−σ 的機率直接透過,以 σ 的機率經過變換後才透過。這個形式非常像遞迴神經網路中的 GRU 模型。
補充推導:

由於 Conv1D1 並沒有加啟用函式,所以它只是一個線性變換,從而 Conv1D1(X)−X 可以結合在一起,等效於單一一個 Conv1D1。說白了,在訓練過程中,Conv1D1(X)−X 能做到的事情,Conv1D1(X) 也能做到。從而 (2) 和 (3) 兩者是等價的。
膨脹摺積
接下來,為了使得 CNN 模型能夠捕捉更遠的的距離,並且又不至於增加模型引數,我們使用了膨脹摺積。
普通摺積跟膨脹摺積的對比,可以用一張圖來演示:

▲ 普通摺積 vs. 膨脹摺積
同樣是三層的摺積神經網路(第一層是輸入層),視窗大小為 3。普通摺積在第三層時,每個節點只能捕捉到前後 3 個輸入,而跟其他輸入完全不沾邊。
而膨脹摺積在第三層時則能夠捕捉到前後 7 個輸入,但引數量和速度都沒有變化。這是因為在第二層摺積時,膨脹摺積跳過與中心直接相鄰的輸入,直接捕捉中心和次相鄰的輸入(膨脹率為 2),也可以看成是一個“視窗大小為 5 的、但被挖空了兩個格的摺積”,所以膨脹摺積也叫空洞摺積(Atrous Convolution)。
在第三層摺積時,則連續跳過了三個輸入(膨脹率為 4),也可以看成一個“視窗大小為 9、但被挖空了 6 個格的摺積”。而如果在相關的輸入輸出連一條線,就會發現第三層的任意一個節點,跟前後 7 個原始輸入都有聯絡。
按照“儘量不重不漏”的原則,膨脹摺積的摺積率一般是按照 1、2、4、8、…這樣的幾何級數增長。當然,這裡指明瞭是“儘量”,因為還是有些重覆的。這個比例參考了 Google 的 wavenet 模型。
Block
現在就可以解釋模型圖中的各個 Conv1D Block 了,如果輸入跟輸出維度大小一致時,那麼就是膨脹摺積版的 (3) 式;如果輸出跟輸出維度大小不一致時,就是簡單的 (1) 式,視窗大小和膨脹率在圖上都已經註明。
註意力
從模型示意圖可以看到,本文的 DGCNN 模型中,Attention 主要用於取代簡單的 Pooling 來完成對序列資訊的整合,包括將問題的向量序列編碼為一個總的問題向量,將材料的序列編碼為一個總的材料向量。
這裡使用的 Attention 稍微不同於 Attention is All You Need 中的 Attention,本文這種 Attention 可以認為是一種“加性註意力”,形式為:

這裡的 v,W 都為可訓練引數。而 Act 為啟用函式,一般會取 tanh,也可以考慮 swish 函式。註意用 swish 時,最好把偏置項也加上去,變為:

這種 Attention 的方案參考自 R-Net 模型(註:不一定是 R-Net 首創,只是我是從 R-Net 中學來的)。
位置向量
為了增強 CNN 的位置感,我們還補充了位置向量,拼接到材料的每個詞向量中。位置向量的構造方法直接沿用 Attention is All You Need 中的方案:

輸出設計
這部分是我們整個模型中頗具特色的地方。
思路分析
到現在,模型的整體結構應該已經呈現出來了。首先我們透過摺積和註意力把問題編碼為一個固定的向量,這個向量拼接到材料的每個詞向量中,並且還拼接了位置向量、人工特徵。
這時候我們得到了一個混合了問題、材料資訊的特徵序列,直接對這個序列進行處理即可,所以後面接了幾層摺積進行編碼處理,然後直接對序列進行標註,而不需要再對問題進行互動了。
在 SQUAD 的評測中,材料是肯定有答案的,並且答案所在的位置也做好了標註,所以 SQUAD 的模型一般是對整個序列做兩次 softmax,來預測答案的開始位置和終止位置,我們一般稱之為“指標網路”。
然而我們這裡的 WebQA 式問答,材料中不一定有答案,所以我們不用 softmax,而是對整個序列都用 sigmoid,這樣既允許了材料中沒有答案,也允許答案在材料中多次出現。
雙標註輸出
既然用到標註,那麼理論上最簡單的方案是輸出一個 0/1 序列:直接標註出材料中的每個詞“是(1)”或“否(0)”答案。
然而,這樣的效果並不好,因為一個答案可能由連續多個不同的片語成,要讓模型將這些不同的詞都有同樣的標註結果,有可能“強模型所難”。於是我們還是用兩次標註的方式,來分別標註答案的開始位置和終止位置。

這樣一來,模型的輸出設計跟指標方式和純序列標註都不一樣,或者說是兩者的簡化及融合。
大局觀
最後,為了增加模型的“大局觀”,我們將材料的序列編碼為一個整體的向量,然後接一個全連線層來得到一個全域性的打分,並把這個打分的結果乘到前面的標註中,即變成:

這個全域性打分對模型的收斂和效果具有重要的意義,它的作用是更好地判斷材料中是否存在答案,一旦材料中沒有答案,直接讓 即可,不用“煞費苦心”讓每個詞的標註都為 0。
即可,不用“煞費苦心”讓每個詞的標註都為 0。
人工特徵
文章的前面部分,我們已經多次提到過人工特徵,那麼這些人工特徵的作用有多大呢?簡單目測的話,這幾個人工特徵對於模型效果的提升可能超過 2%。可見設計好的特徵對模型效果的特徵、模型複雜度的降低,都有著重要的作用。
人工特徵是針對材料中的詞來設計的,列舉如下(Q 即 question,代表問題;E 即 evidence,代表材料)。
Q-E全匹配
也就是判斷材料中的詞是否在問題出現過,出現過則為 1,沒出現過則為 0。這個特徵的思路是直接告訴模型問題中的詞在材料中什麼地方出現了,那些地方附近就很有可能有答案。這跟我們人類做閱讀理解的思路是吻合的。
E-E共現
這個特徵是計算某個材料中的詞在其他材料中的出現比例。比如有 10 段材料,第一段材料有一個詞 w,在其餘九段材料中,有 4 段都包含了這個詞,那麼第一段材料的詞 w 就獲得一個人工特徵 4/10。
這個特徵的思路是一個詞出現在的材料越多,這個詞越有可能是答案。
Q-E軟匹配
以問題大小為視窗來對材料的每個視窗算 Jaccard 相似度、相對編輯距離。
比如問題“白雲山 的 海拔 是 多少 ?”,材料“白雲山 坐落 在 廣州 , 主峰 海拔 3 8 2 米”。問題有 6 個詞,那麼視窗大小就為 6,將材料拆分為:

其中 X 代表佔位符。有了這個拆分,我就可以算每一塊與問題的 Jaccard 相似度了,將相似度的結果作為當前詞(也就是紅色詞)的一個特徵,上述例子算得 [0.13, 0.11, 0.1, 0.09, 0.09, 0.09, 0.09, 0.09, 0.09, 0.1, 0]。
同樣地,我們還可以算每一塊與問題的編輯距離,然後除以視窗大小,就得到一個 0~1 之間的數,我稱之為“相對編輯距離”,上述例子算得 [0.83, 0.83, 0.83, 0.83, 1, 1, 1, 0.83, 1, 1, 1]。
Jaccard 相似度是無序的,而編輯距離是有序的,因此這兩個做法相對於從有序和無序兩個角度來衡量問題和材料之間的相似度。這兩個特徵的思路跟第一個特徵一樣,都是告訴模型材料中哪部分會跟問題相似,那部分的附近就有可能有答案。
這兩個特徵的主要思路來自 Keras 群中的 Yin 神,感謝~
字元特徵
SQUAD 排名靠前的模型中,基本都是以詞向量和字元向量共同輸入到模型中的,而為了提升效果,我們似乎也要把字向量和詞向量同時輸入。但我們並不想將模型做得太龐大,於是我們在人工特徵這裡,加入了字元級特徵。
其實思路也很簡單,前面介紹的 4 個特徵,都是以詞為基本單位來計算的,事實上也可以以字為基本單位算一次,然後把每個詞內的字的結果平均一下,作為詞的特徵就行了。
比如在“Q-E 全匹配”特徵中,假設問題只有“演”這個詞,而材料則有“合演”這個詞,如果按照詞來看,“合演”這個詞沒有在問題出現過,所以共現特徵為 0,而如果考慮字的話,“合演”就被拆開為兩個字“合”和“演”,按照同樣的方式算共現特徵,“合”得到 0、“演”得到 1,將兩者平均一下,得到 0.5,作為“合演”這個詞的字元級“Q-E 全匹配”特徵。
其他三個特徵也同樣處理,這樣我們就得到了另外 4 個特徵,一定得到 8 個人工特徵。
實現
現在,模型的各個部分基本上都解釋清楚了。其實模型整體簡單明瞭,講起來也容易,應該會有種“大道至簡”的感覺。下麵介紹一些實現要點。
模型設定
下麵是實現模型的一些基本要點。
中文分詞
從前面的介紹中可以看到,本模型是基於詞來實現的,並且基於前面說的人工特徵簡單引入了字元級別的資訊。不過,為了使得模型整體上更加靈活,能夠應答更多的問題,本文僅僅對輸入進行了一個基本的分詞,使得分詞的顆粒度儘量低一些。
具體實現為:自己寫了一個基於一元模型的分詞模組,自行準備了一個約 50 萬詞的詞典,而所有的英文、數字都被拆開為單個的字母和數字,比如 apple 就變成了五個“詞”:a p p l e,382 就變成了三個“詞”:3 8 2。
由於沒有新詞發現功能,這樣一來,整個詞表的詞就不會超過 50 萬。事實上,我們最後得到的模型,模型總詞數只有 30 萬左右。
當然,讀者可以使用結巴分詞,關閉結巴分詞的新詞發現,並且手動對數字和英文進行拆分,效果是一樣的。
部分引數
1. 詞向量的維度為 128 維,由比賽方提供的訓練語料、WebQA 語料、50 萬百度百科條目、100 萬百科知道問題用 Word2Vec 預訓練而成,其中 Word2Vec 的模型為 Skip Gram,視窗為 5,負取樣數為 8,迭代次數為 8,訓練時間約為 12 小時;
2. 詞向量在 DGCNN 模型的訓練過程中保持固定;
3. 所有 Conv1D 的輸出維度皆為 128 維,位置向量也是 128 維;
4. Conv1D 的最大長度取為 100,如果一個 batch 中某些樣本涉及到 padding,那麼對 padding 部分要做好 mask;
5. 由於最後變成一個二分類的標註形式,並且考慮到正負類不均衡,使用二分類的 focal loss 作為損失函式;
6. 用 adam 最佳化器進行訓練,先用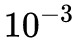 的學習率訓練到最優(大概 6 個 epoch 內),然後載入最優模型,改用
的學習率訓練到最優(大概 6 個 epoch 內),然後載入最優模型,改用 學習率訓練到最優(3 個 epoch 內)。
學習率訓練到最優(3 個 epoch 內)。
正則項
在比賽後期,我們發現一種類似 DropPath 的正則化能輕微提升效果,不過提升幅度我也不大確定,總之當時是帶來了一定的提升。
這個正則化手段建立在 (3) 式的基礎上,我們的思路是在訓練階段對“門”進行擾動:


▲ 對GCNN的門進行擾動,作為模型的一個正則項
其中 ε 是 [−0.1,0.1] 內的均勻隨機數張量。這樣一來,我們給 GCNN 的“門”加入了“乘性噪聲”來使得具有更好的魯棒性(對抗引數的小擾動)。
這個正則化方案的提出,多多少少受到了 FractalNet: Ultra-Deep Neural Networks without Residuals [5] 和 Shake-Shake regularization [6] 裡邊的正則化技術啟發。
資料準備
資料預處理
由於 SOGOU 這個比賽允許使用外部資料,因此我們及大多數參賽隊伍都使用了 WebQA 資料集補充訓練。考慮到 WebQA 資料集相對規整一下,而 SOGOU 提供的語料噪聲相對大一些,所以我們將 SOGOU 和 WebQA 的語料集以 2:1 的比例混合。
不管是 WebQA 還是 SOGOU,所提供的語料都是“一個問題 + 多段材料 + 一個答案”的形式,並沒有特別指明答案出現在哪段材料的哪個位置。
因此,我們只好把材料中所有能跟答案全匹配的子串都視為答案所在處。對於某些樣本,這樣操作有點不合理,但是在不加額外的人工標註的情況下,這也是我們能做到的最優的思路了。
訓練語料還有一個問題答案的同義詞問題,比如問“憨豆的扮演者”,標準答案是“羅溫艾金森”,但是材料中不僅有“羅溫艾金森”,還有“羅溫·艾金森”、“羅溫.艾金森”、“洛溫·艾金森”等。
SOGOU 比賽比較好的一點是它提供了一個相對客觀的線下評測指令碼,這個評測指令碼考慮了同義詞的變化,因此我們可以從這個評測指令碼中找到答案的同義詞,從而可以把同義答案都標註出來。
還有一些諸如全形字元轉半形的操作,相信大家看了資料集自然也就想到了,因此不再贅述。
資料打勻
SOGOU 最後一共提供了 3 萬個問題的標註語料,並且給我們預先劃分好了訓練集(2.5 萬)和驗證集(0.5 萬)。但是如果直接用它的劃分來訓練,那驗證集的結構卻跟線上提交的結果出入比較大。
所以我們把所有的標註語料混合然後重新打亂,並且重新劃分訓練集(2 萬)和驗證集(1 萬),這樣在驗證集上的得分約為 0.76,跟線上提交的結果接近。
資料擴增
在模型的訓練過程中,使用了可以稱得上是資料擴增的三個操作。
1. 直接隨機地將問題和材料的部分詞 id 置零:問題和材料都是以詞 id 序列的方式輸入,0 是填充符(相當於),隨機置零就是隨機將詞用替換,減弱對部分詞的依賴;
2. 將同一段材料透過重覆拼接、隨機裁剪的方式,來得到新的材料(答案的數目、位置也隨之變化);
3. 對於答案出現多次的材料,隨機去掉某些答案的標註。比如答案“廣東”可能在某段材料中出現兩次,那麼做答案標註的時候,可能只標註第一個、或只標註第二個、或都標註。
印象中,第 1 個資料擴增手段影響比較大的,能有效提升模型的穩定性和精度,至於第 2、3 個方案相對微弱一些。
第 1 個資料擴增手段,跟直接對詞向量序列進行 dropout 的區別是:dropout 除了隨機置零外,還會進行尺度縮放,而這裡就是不想要它的尺度縮放,解釋性要好些。
解碼策略
很多參賽選手可能會忽略的一個細節是:答案的解碼方式可能有很大的最佳化空間,而最佳化解碼帶來的提升,可能遠比反覆對模型調參帶來的提升要大。
打分方式
何為答案解碼?不管是用 softmax 形式的指標,還是用本文的 sigmoid 形式的“半指標-半標註”,最後模型輸出的是兩列浮點數,分別代表了答案起始位置和終止位置的打分。
但問題是,用什麼指標確定答案區間呢?一般的做法是:確定答案的最大長度 max_words(我取了 10,但漢字算一個,字母和數字只算半個),然後遍歷材料所有長度不超過 max_words 的區間,計算它們起始位置和終止位置的打分的和或積,然後取最大值。
那麼問題來了,“和”好還是“積”好呢?又或者是“積的平方根”?
開始我按直覺來,感覺“積的平方根”是最合理的,後來測試了一下直接改成“積”,發現效果提升很明顯(1%)。於是我就反覆斟酌了這個解碼決策過程,發現裡面還其實有很多坑,這也是一種重要的超參,不能單純按照直覺來。
投票方式
比如同一段材料同一個片段出現多次時,是要把這些片段的打分求和、求平均還是隻取最大的?每段材料都得到了自己的答案,又怎麼把這麼多段材料的答案投票出最終的答案來?
比如有 5 段材料,每段材料得出的答案和分數依次是 (A, 0.7)、(B, 0.2)、(B, 0.2)、(B, 0.2)、(B, 0.2),那麼我們最終應該輸出 A 還是 B 呢?
有人說“三個臭皮匠,頂一個諸葛亮”,自然這裡的臭皮匠指的是指低分答案B,諸葛亮是指高分答案 A,4 個 B 的分數加起來為 0.8 > 0.7,這樣看起來應該輸出 B?
我覺得不大對。在我們的生活中,專家並不等於平民的簡單疊加,人多的確力量大,但很多時候 1+1 是小於 2 的。就好比上面的答案分佈,我們其實更傾向於選擇 A 答案,因為它接近滿分 1,而且相對其它答案更加“出類拔萃”。
所以,我們的投票方式必須體現兩點:1. 人多力量大;2. 1+1<2。所以求和以及求平均都不行,最簡單的方案應該是“平方和”:
1. 對於同一段材料,如果一個片段出現了多次,那麼只取最大的那個分,不平均也不求和,這是因為“同一段材料”相當於“同一個人”,同一個人就沒必要疊加太多了;
2. 經過這樣處理,每段材料都“選舉”出自己的答案了,每段材料就相當於一個“臭皮匠”或“諸葛亮”,每個答案都有自己的分數,就是代表這些“臭皮匠”或“諸葛亮”的決策,將相同答案的打分求“平方平均”作為該答案的最後打分,然後在不同答案中選最大的那個:

因為“平方”會把高分的樣本權重放大。
3. 相比步驟 2,我在比賽中使用了一個略微不同的打分公式:

這個公式同樣是平方求和的思想,只是再求了一次平均,並且分母“+1”。“平方”這個操作是對專家的加權,“+1”則是對小樣本的懲罰,這個公式比直接平方求和更加平緩。
註意,不僅僅是我們的模型,我在跟另外一參賽選手交流的時候,提示了他這個解碼方式,他用同樣的思路經過除錯後,也得到了比較大的提升。
模型融合
經過上述步驟,模型在 SOGOU 的線上測試集上達到 0.74~0.75 的分數應該是沒有問題的。但要達到最優的 0.7583,就要上模型融合了。
模型融合分單模型融合和多模型融合。單模型融合是指同一個模型架構,用不同的方式訓練多次,然後將結果平均;多模型融合則是給每個模型都做一次單模型融合,然後將多個單模型融合的結果再次融合。簡單起見,我們只做了單模型融合。
單模型建立在交叉驗證的基礎上。前面我們提到,將標註語料重新打亂後,重新劃分訓練集和驗證集,交叉驗證的話更徹底一些,它把標註語料重新打亂後,分為 k 份,每份都拿來做一次驗證集(每次都要重零開始訓練模型)。
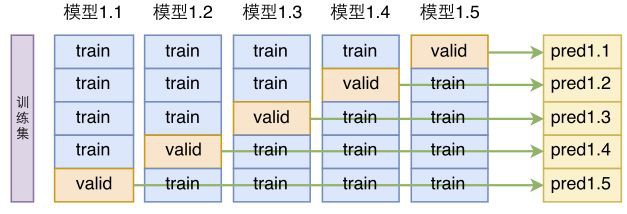
▲ 模型的k折交叉驗證
這樣一來,我們就得到了同一個模型的 k 個不同訓練結果,然後將這些結果平均一下,就是模型融合了:

▲ 基於交叉驗證的單模型融合
後文
效果評估
排行榜擺在那,所以模型的效果是看得見的,在 SOGOU 這個噪聲這麼大的封閉測試集上,我們模型最終得分都有 0.7583。
而且從訓練集來看,我覺得有些噪聲是故意加進去的,有些材料實在太離譜,感覺直接放在搜尋引擎或百度知道召回一批材料都不至於這麼糟糕,所以我認為實際使用中效果會更好。再加上純 CNN 的輕量級模型,這已經完全滿足工業需求了。
另外,我也在 SQUAD 上測了一下這個模型,發現準確率也就 50% 上下,當然沒精調,也沒融合,如果經過最佳化除錯,估計也就 60%+ 的準確率吧。
顯然這跟 0.7583 的得分差距是比較遠的,這也表明 WebQA 式的閱讀理解問答,跟 SQUAD 的純閱讀理解,是很不一樣的,雖然理論上它們的模型可以相互套用。
程式碼 & 測試
模型已經上線到火焰科技的官網上,可以點選以下連結線上測試:
http://www.birdbot.cn/view/tyzq-igQa.html
註:移動端訪問效果也許欠佳,請儘量在 PC 端訪問
至於程式碼就不公開了,原因有兩個:
一是這個比賽是代表公司參加的,不好直接將所有東西開源,而且模型確實簡單明快,看完文章後跟著文章實現並不難,如果讀者還不能實現的話,我建議還是打好程式碼基礎再玩閱讀理解和問答系統。
二是一旦開源,總有那麼些讀者連文章都不想看,直接把程式碼下載下來,然後跑不通就一連串問題“這個庫怎麼安裝”、“這句程式碼又報錯了”,實在應接不暇。
這篇文章終究不是掃盲文,所以請讀者們見諒。當然,沒有歧視初學者的意思,部落格也時常會有入門級的文章出現,只不過不是這篇罷了。
此外,作為一個及格的參賽者,SOGOU 的訓練語料也不好直接公開,需要測試的讀者,可以直接用 WebQA 資料集進行訓練。
千調百試
最後給大家看個截圖:

這個截圖基本上就代表了我的整個除錯過程了,其中包含了上百次的迭代除錯,每次更新又要做多次實驗。
這是我目前做比賽最投入的一次了。所以,雖然本文不是正式的 paper,但如果讀者確實從本文中收穫了什麼,那麼希望能取用一下本文。
最後的最後,感謝廣州火焰科技提供的軟體和硬體上的的支援,公司給我提供了非常友好的發展和成長的機會。
PS:後來發現,本文的模型其實跟 Fast Reading Comprehension with ConvNets 和 QANET: COMBINING LOCAL CONVOLUTION WITH GLOBAL SELF-ATTENTION FOR READING COMPREHENSION 這兩篇論文“撞車”了,但筆者當初做比賽時,確實從未參考過這兩篇論文。
當時是從 WebQA 的論文出發,打算復現 WebQA 的模型,然後覺得好奇就想試試 CNN 模型,然後就一發不可收了。
參考文獻
[1]. WebQA語料集
https://kexue.fm/archives/4338
[2]. Peng Li, Wei Li, Zhengyan He, Xuguang Wang, Ying Cao, Jie Zhou, and Wei Xu. Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Factoid Question Answering. arXiv:1607.06275.
[3]. Convolutional Sequence to Sequence Learning. Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, Yann N. Dauphin. arXiv, 2017
[4].《分享一個slide:花式自然語言處理》
https://kexue.fm/archives/4823
[5]. G. Larsson, M. Maire, and G. Shakhnarovich, “FractalNet: Ultra-Deep Neural Networks without Residuals,” ArXiv:1605.07648v4
[6]. Xavier Gastaldi. Shake-Shake regularization. arXiv:1705.07485.

點選以下標題檢視作者其他文章:

 #線 上 報 名#
#線 上 報 名#
NVIDIA TensorRT 線上分享
1 掃描下方二維碼填寫報名錶,報名成功請截圖儲存
2 新增小助手微信 pwbot02,備註 NVIDIA 獲取入群通道及直播地址
NVIDIA × PaperWeekly
揭秘NVIDIA TensorRT
NVIDIA開發者社群經理何琨
內容分享√線上Q&A;√
活動形式:PPT直播
活動時間
4 月 18 日(週三)20:00
長按識別二維碼,立刻報名
*報名完成請加微信「pwbot02」入群

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 進入作者部落格