三大容器平臺之爭塵埃落定,Kubernetes成為各家公司做微服務支撐的首選平臺。Kubernetes的勝出有社群運營的原因所在,但僅僅從技術角度來講,Kubernetes相對於其他容器平臺來講,是有微服務基因的,這也是網易雲為什麼從一開始就選擇Kubernetes作為容器平臺的原因。很多有IT架構背景的公司,站在IT運維的角度來講,可能會選擇其他容器平臺,但是網易雲的初創架構團隊,是從事部落格應用層開發的,站在應用層的角度出發,選擇Kubernetes就變成自然而然的事情了。
最近在反思,為什麼在支撐容器平臺和微服務的競爭中,Kubernetes會取得最終的勝出。因為在很多角度來講三大容器平臺從功能角度來說,最後簡直是一摸一樣,具體的比較可以參考本人前面的兩篇文章。
經過一段時間的思索,並採訪了從早期就開始實踐Kubernetes的網易雲架構師們,從而有了今天的分享。
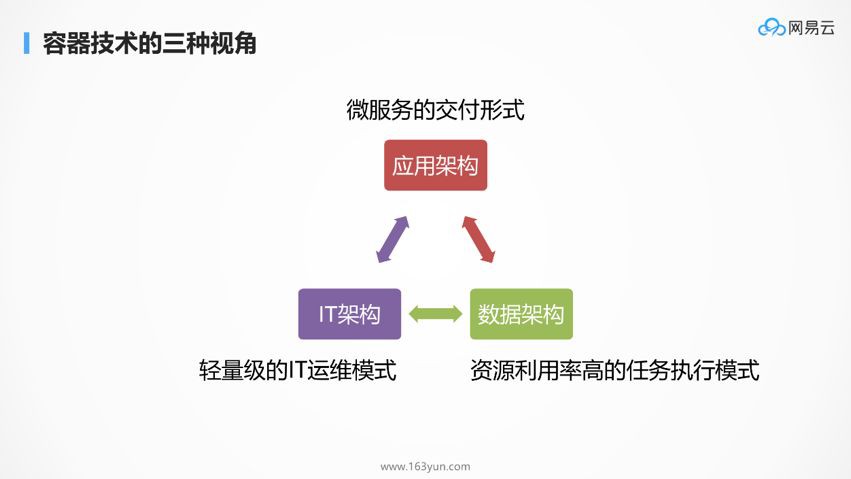
如圖所示,企業上的三大架構為IT架構,應用架構和資料架構,在不同的公司,不同的人,不同的角色,關註的重點不同。
對於大部分的企業來講,上雲的訴求是從IT部門發起的,發起人往往是運維部門,他們關註計算,網路,儲存,試圖透過雲端計算服務來減輕CAPEX和OPEX。
有的公司有ToC的業務,因而累積了大量的使用者資料,公司的運營需要透過這部分資料進行大資料分析和數字化運營,因而在這些企業裡面往往還需要關註資料架構。
從事網際網路應用的企業,往往首先關註的是應用架構,是否能夠滿足終端客戶的需求,帶給客戶良好的使用者體驗,業務量往往會在短期內出現爆炸式的增長,因而關註高併發應用架構,並希望這個架構可以快速迭代,從而搶佔風口。
在容器出現之前,這三種架構往往透過虛擬機器雲平臺的方式解決。
當容器出現之後,容器的各種良好的特性讓人眼前一亮,他的輕量級、封裝、標準、易遷移、易交付的特性,使得容器技術迅速被廣泛使用。
然而一千個人心中有一千個哈姆雷特,由於原來工作的關係,三類角色分別從自身的角度看到了容器的優勢給自己帶來的便捷。
對於原來在機房裡面管計算、網路、儲存的IT運維工程師來講,容器更像是一種輕量級的運維樣式,在他們看來,容器和虛擬機器的最大的區別就是輕量級,啟動速度快,他們往往引以為豪的推出虛擬機器樣式的容器。
對於資料架構來講,他們每天都在執行各種各樣的資料計算任務,容器相對於原來的JVM,是一種隔離性較好,資源利用率高的任務執行樣式。
從應用架構的角度出發,容器是微服務的交付形式,容器不僅僅是做部署的,而是做交付的,CI/CD中的D的。
所以這三種視角的人,在使用容器和選擇容器平臺時方法會不一樣。
二、Kubernetes才是微服務和DevOps的橋梁

從IT運維工程師的角度來看:容器主要是輕量級、啟動快。而且自動重啟,自動關聯。彈性伸縮的技術,使得IT運維工程師似乎不用再加班。
Swarm的設計顯然更加符合傳統IT工程師的管理樣式。
他們希望能夠清晰地看到容器在不同機器的分佈和狀態,可以根據需要很方便地SSH到一個容器裡面去檢視情況。
容器最好能夠原地重啟,而非隨機排程一個新的容器,這樣原來在容器裡面安裝的一切都是有的。
可以很方便的將某個執行的容器打一個映象,而非從Dockerfile開始,這樣以後啟動就可以復用在這個容器裡面手動做的100項工作。
容器平臺的整合性要好,用這個平臺本來是為了簡化運維的,如果容器平臺本身就很複雜,像Kubernetes這種本身就這麼多行程,還需要考慮它的高可用和運維成本,這個不划算,一點都沒有比原來省事,而且成本還提高了。
最好薄薄得一層,像一個雲管理平臺一樣,只不過更加方便做跨雲管理,畢竟容器映象很容易跨雲遷移。
Swarm的使用方式比較讓IT工程師以熟悉的味道,其實OpenStack所做的事情它都能做,速度還快。
然而容器作為輕量級虛擬機器,暴露出去給客戶使用,無論是外部客戶,還是公司內的開發,而非IT人員自己使用的時候,他們以為和虛擬機器一樣,但是發現了不一樣的部分,就會很多的抱怨。
例如自修複功能,重啟之後,原來SSH進去手動安裝的軟體不見了,甚至放在硬碟上的檔案也不見了,而且應用沒有放在Entrypoint裡面自動啟動,自修複之後行程沒有跑起來,還需要手動進去啟動行程,客戶會抱怨你這個自修複功能有啥用?
例如有的使用者會ps一下,發現有個行程他不認識,於是直接kill掉了,結果是Entrypoint的行程,整個容器直接就掛了,客戶抱怨你們的容器太不穩定,老是掛。
容器自動排程的時候,IP是不保持的,所以往往重啟原來的IP就沒了,很多使用者會提需求,這個能不能保持啊,原來配置檔案裡面都配置的這個IP的,掛了重啟就變了,這個怎麼用啊,還不如用虛擬機器,至少沒那麼容易掛。
容器的系統盤,也即作業系統的那個盤往往大小是固定的,雖然前期可以配置,後期很難改變,而且沒辦法每個使用者可以選擇系統盤的大小。有的使用者會抱怨,我們原來本來就很多東西直接放在系統盤的,這個都不能調整,叫什麼雲端計算的彈性啊。
如果給客戶說容器掛載資料盤,容器都啟動起來了,有的客戶想像雲主機一樣,再掛載一個盤,容器比較難做到,也會被客戶罵。
如果容器的使用者不知道他們在用容器,當虛擬機器來用,他們會覺得很難用,這個平臺一點都不好。
Swarm上手雖然相對比較容易,但是當出現問題的時候,作為運維容器平臺的人,會發現問題比較難解決。
Swarm內建的功能太多,都耦合在了一起,一旦出現錯誤,不容易debug。如果當前的功能不能滿足需求,很難定製化。很多功能都是耦合在Manager裡面的,對Manager的操作和重啟影響面太大。
從大資料平臺運維的角度來講,如何更快的排程大資料處理任務,在有限的時間和空間裡面,更快的跑更多的任務,是一個非常重要的要素。
所以當我們評估大資料平臺牛不牛的時候,往往以單位時間內跑的任務數目以及能夠處理的資料量來衡量。
從資料運維的角度來講,Mesos是一個很好的排程器,既然能夠跑任務,也就能夠跑容器,Spark和Mesos天然的整合,有了容器之後,可以用更加細粒度的任務執行方式。
在沒有細粒度的任務排程之前,任務的執行過程是這樣的。任務的執行需要Master的節點來管理整個任務的執行過程,需要Worker節點來執行一個個子任務。在整個總任務的一開始,就分配好Master和所有的Work所佔用的資源,將環境配置好,等在那裡執行子任務,沒有子任務執行的時候,這個環境的資源都是預留在那裡的,顯然不是每個Work總是全部跑滿的,存在很多的資源浪費。
在細粒度的樣式下,在整個總任務開始的時候,只會為Master分配好資源,不給Worker分配任何的資源,當需要執行一個子任務的時候,Master才臨時向Mesos申請資源,環境沒有準備好怎麼辦?好在有Docker,啟動一個Docker,環境就都有了,在裡面跑子任務。在沒有任務的時候,所有的節點上的資源都是可被其他任務使用的,大大提升了資源利用效率。
這是Mesos的最大的優勢,在Mesos的論文中,最重要闡述的就是資源利用率的提升,而Mesos的雙層排程演演算法是核心。
原來大資料運維工程師出身的,會比較容易選擇Mesos作為容器管理平臺。只不過原來是跑短任務,加上marathon就能跑長任務。但是後來Spark將細粒度的樣式deprecated掉了,因為效率還是比較差。
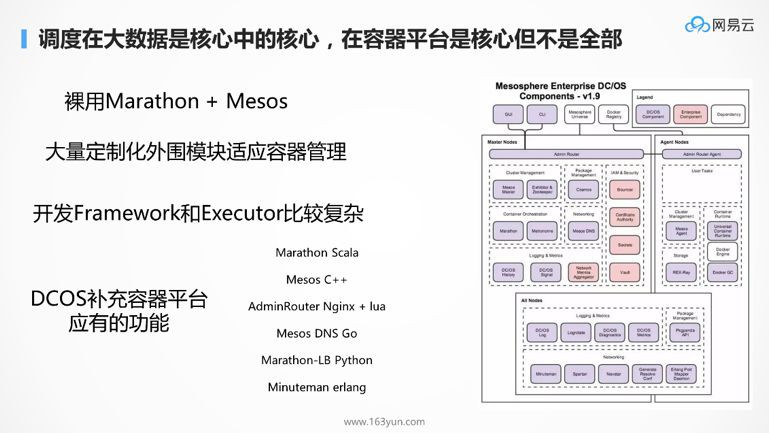
排程在大資料領域是核心中的核心,在容器平臺中是重要的,但是不是全部。所以容器還需要編排,需要各種外圍元件,讓容器跑起來執行長任務,並且相互訪問。Marathon只是萬裡長徵的第一步。
所以早期用Marathon + Mesos的廠商,多是裸用Marathon和Mesos的,由於周邊不全,因而要做各種的封裝,各家不同。大家有興趣可以到社群上去看裸用Marathon和Mesos的廠商,各有各的負載均衡方案,各有各的服務發現方案。
所以後來有了DCOS,也就是在Marathon和Mesos之外,加了大量的周邊元件,補充一個容器平臺應有的功能,但是很可惜,很多廠商都自己定製過了,還是裸用Marathon和Mesos的比較多。
而且Mesos雖然排程牛,但是隻解決一部分排程,另一部分靠使用者自己寫framework以及裡面的排程,有時候還需要開發Executor,這個開發起來還是很複雜的,學習成本也比較高。
雖然後來的DCOS功能也比較全了,但是感覺沒有如Kubernetes一樣使用統一的語言,而是採取大雜燴的方式。在DCOS的整個生態中,Marathon是Scala寫的,Mesos是C++寫的,Admin Router是Nginx+lua,Mesos-DNS是Go,Marathon-lb是Python,Minuteman是Erlang,這樣太複雜了吧,林林總總,出現了Bug的話,比較難自己修複。
而Kubernetes不同,初看Kubernetes的人覺得他是個奇葩所在,容器還沒創建出來,概念先來一大堆,檔案先讀一大把,編排檔案也複雜,元件也多,讓很多人望而卻步。我就想建立一個容器玩玩,怎麼這麼多的前置條件。如果你將Kubernetes的概念放在介面上,讓客戶去建立容器,一定會被客戶罵。
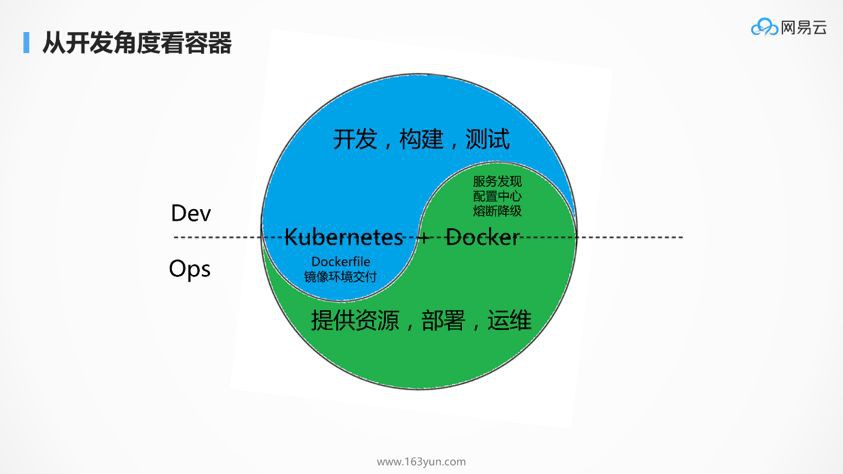
在開發人員角度,使用Kubernetes絕對不是像使用虛擬機器一樣,開發除了寫程式碼,做構建,做測試,還需要知道自己的應用是跑在容器上的,而不是當甩手掌櫃。開發人員需要知道,容器是和原來的部署方式不一樣的存在,你需要區分有狀態和無狀態,容器掛了起來,就會按照映象還原了。開發人員需要寫Dockerfile,需要關心環境的交付,需要瞭解太多原來不瞭解的東西。實話實說,一點都不方便。
在運維人員角度,使用Kubernetes也絕對不是像運維虛擬機器一樣,我交付出來了環境,應用之間互相怎麼呼叫,我才不管,我就管網路通不通。在運維眼中做了過多他不該關心的事情,例如服務的發現,配置中心,熔斷降級,這都應該是程式碼層面關心的事情,應該是Spring Cloud和Dubbo關心的事情,為什麼要到容器平臺層來關心這個。
Kubernetes + Docker,卻是Dev和Ops融合的一個橋梁。
Docker是微服務的交付工具,微服務之後,服務太多了,單靠運維根本管不過來,而且很容易出錯,這就需要研發開始關心環境交付這件事情。例如配置改了什麼,建立了哪些目錄,如何配置許可權,只有開發最清楚,這些資訊一方面很難透過檔案的方式,又及時又準確的同步到運維部門來,就算是同步過來了,運維部門的維護量也非常的大。
所以,有了容器,最大的改變是環境交付的提前,是每個開發多花5%的時間,去換取運維200%的勞動,並且提高穩定性。
而另一方面,本來運維只管交付資源,給你個虛擬機器,虛擬機器裡面的應用如何相互訪問我不管,你們愛咋地咋地,有了Kubernetes以後,運維層要關註服務發現,配置中心,熔斷降級。
兩者融合在了一起。在微服務化的研發的角度來講,Kubernetes雖然複雜,但是設計的都是有道理的,符合微服務的思想。
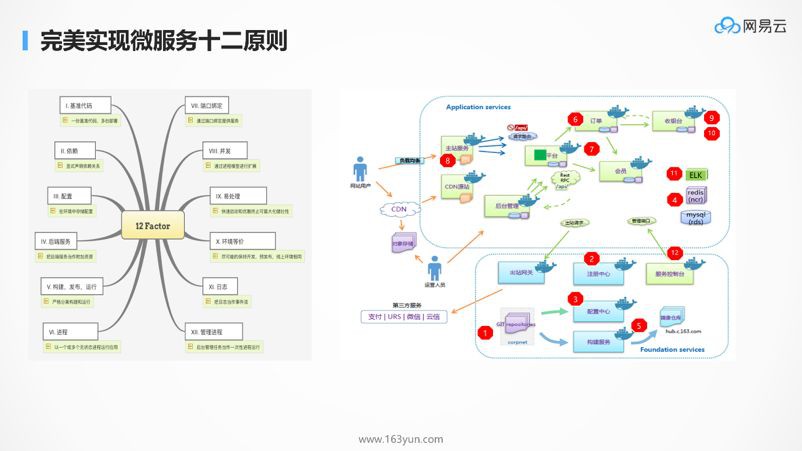
微服務有哪些要點呢?第一張圖是Spring Cloud的整個生態。
第三張圖是構建一個高併發的微服務,需要考慮的所有的點。
在實施微服務的過程中,不免要面臨服務的聚合與拆分,當後端服務的拆分相對比較頻繁的時候,作為手機App來講,往往需要一個統一的入口,將不同的請求路由到不同的服務,無論後面如何拆分與聚合,對於手機端來講都是透明的。
有了API閘道器以後,簡單的資料聚合可以在閘道器層完成,這樣就不用在手機App端完成,從而手機App耗電量較小,使用者體驗較好。
有了統一的API閘道器,還可以進行統一的認證和鑒權,儘管服務之間的相互呼叫比較複雜,介面也會比較多,API閘道器往往只暴露必須的對外介面,並且對介面進行統一的認證和鑒權,使得內部的服務相互訪問的時候,不用再進行認證和鑒權,效率會比較高。
有了統一的API閘道器,可以在這一層設定一定的策略,進行A/B測試,藍綠釋出,預發環境導流等等。API閘道器往往是無狀態的,可以橫向擴充套件,從而不會成為效能瓶頸。
影響應用遷移和橫向擴充套件的重要因素就是應用的狀態,無狀態服務,是要把這個狀態往外移,將Session資料,檔案資料,結構化資料儲存在後端統一的儲存中,從而應用僅僅包含商務邏輯。
狀態是不可避免的,例如ZooKeeper、DB、Cache等,把這些所有有狀態的東西收斂在一個非常集中的叢集裡面。
整個業務就分兩部分,一個是無狀態的部分,一個是有狀態的部分。
無狀態的部分能實現兩點,一是跨機房隨意地部署,也即遷移性,一是彈性伸縮,很容易的進行擴容。
有狀態的部分,如DB、Cache、ZooKeeper有自己的高可用機制,要利用到他們自己的高可用的機制來實現這個狀態的叢集。
雖說無狀態化,但是當前處理的資料,還是會在記憶體裡面的,當前的行程掛掉資料,肯定也是有一部分丟失的,為了實現這一點,服務要有重試的機制,介面要有冪等的機制,透過服務發現機制,重新呼叫一次後端的服務的另一個實體就可以了。
資料庫是儲存狀態,最重要的也是最容易出現瓶頸的。有了分散式資料庫可以使得資料庫的效能可以隨著節點的增加線性的增加。
分散式資料庫最最下麵是RDS,是主備的,透過MySQL的核心開發能力,我們能夠實現主備切換資料零丟失,所以資料落在這個RDS裡面,是非常放心的,哪怕是掛了一個節點,切換完了以後,你的資料也是不會丟的。
再往上就是橫向怎麼承載大的吞吐量的問題,上面有一個的負載均衡NLB,用LVS、HAProxy、Keepalived,下麵接了一層Query Server。Query Server是可以根據監控的資料進行橫向的擴充套件的,如果出現了故障,可以隨時進行替換的修複的,對於業務層是沒有任何感知的。
另外一個就是雙機房的部署,DDB這面開發了一個資料運河NDC的元件,可以使得不同的DDB之間在不同的機房裡面進行同步,這時候不但在一個資料中心裡面是分散式的,在多個資料中心裡面也會有一個類似雙活的一個備份,高可用性有非常好的保證。
在高併發場景下快取是非常重要的。要有層次的快取,使得資料儘量靠近使用者。資料越靠近使用者能承載的併發量也越大,響應時間越小。
在手機客戶端App上就應該有一層快取,不是所有的資料都每時每刻都從後端拿,而是隻拿重要的,關鍵的,時常變化的資料。
尤其是對於靜態資料,可以過一段時間去取一次,而且也沒必要到資料中心去取,可以透過CDN,將資料快取在距離客戶端最近的節點上,進行就近的下載。
有的時候CDN裡面沒有,還是要回到資料中心去下載,稱為回源,在資料中心的最外層,我們稱為接入層,可以設定一層快取,將大部分的請求攔截,從而不會對後臺的資料庫造成壓力。
如果是動態資料,還是需要訪問應用,透過應用中的商務邏輯生成,或者去資料庫中讀取,為了減輕資料庫的壓力,應用可以使用本地的快取,也可以使用分散式快取,如Memcached或者Redis,使得大部分的請求讀取快取即可,不必訪問資料庫。
當然動態資料還可以做一定的靜態化,也即降級成靜態資料,從而減少後端的壓力。
當系統扛不住,應用變化快的時候,往往要考慮將比較大的服務拆分為一系列小的服務。
這樣首先的好處就是開發比較獨立,當非常多的人在維護同一個程式碼倉庫的時候,往往對程式碼的修改就會相互影響,常常會出現,我沒改什麼測試就不透過了,而且程式碼提交的時候,經常會出現衝突,需要進行程式碼合併,大大降低了開發的效率。
另外一個好處就是上線獨立,物流模組對接了一家新的快遞公司,需要連同下單一起上線,這是非常不合理的行為,我沒改還要我重啟,我沒改還讓我釋出,我沒改還要我開會,都是應該拆分的時機。
另外再就是高併發時段的擴容,往往只有最關鍵的下單和支付流程是核心,只要將關鍵的交易鏈路進行擴容即可,如果這時候附帶很多其他的服務,擴容即使不經濟的,也是很有風險的。
再就是容災和降級,在大促的時候,可能需要犧牲一部分的邊角功能,但是如果所有的程式碼耦合在一起,很難將邊角的部分功能進行降級。
當然拆分完畢以後,應用之間的關係就更加複雜了,因而需要服務發現的機制,來管理應用相互的關係,實現自動的修複,自動的關聯,自動的負載均衡,自動的容錯切換。
當服務拆分了,行程就會非常的多,因而需要服務編排,來管理服務之間的依賴關係,以及將服務的部署程式碼化,也就是我們常說的基礎設施即程式碼。這樣對於服務的釋出、更新、回滾、擴容、縮容,都可以透過修改編排檔案來實現,從而增加了可追溯性,易管理性,和自動化的能力。
既然編排檔案也可以用程式碼倉庫進行管理,就可以實現一百個服務中,更新其中五個服務,只要修改編排檔案中的五個服務的配置就可以,當編排檔案提交的時候,程式碼倉庫自動觸發自動部署升級指令碼,從而更新線上的環境,當發現新的環境有問題的時候,當然希望將這五個服務原子性的回滾,如果沒有編排檔案,需要人工記錄這次升級了哪五個服務。有了編排檔案,只要在程式碼倉庫裡面revert,就回滾到上一個版本了。所有的操作在程式碼倉庫裡面都是可以看到的。
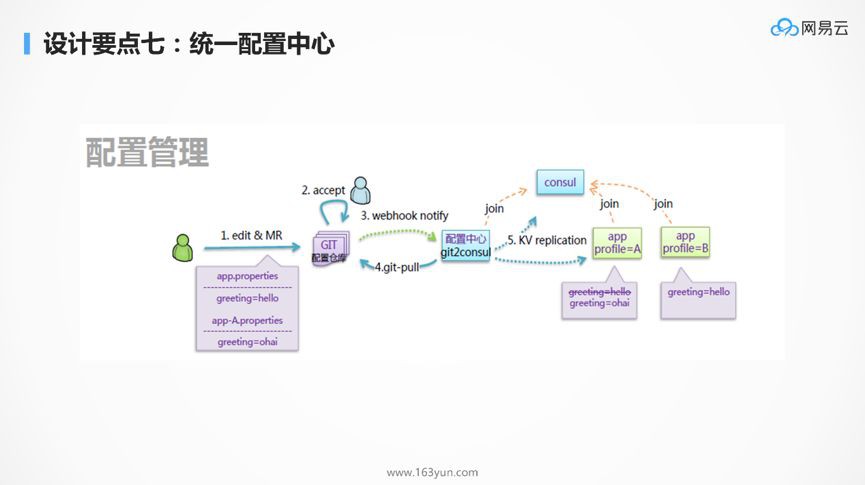
服務拆分以後,服務的數量非常的多,如果所有的配置都以配置檔案的方式,放在應用本地的話,非常難以管理,可以想象當有幾百上千個行程中,有一個配置出現了問題,你很難將它找出來,因而需要有統一的配置中心,來管理所有的配置,進行統一的配置下發。
在微服務中,配置往往分為幾類,一類是幾乎不變的配置,這種配置可以直接打在容器映象裡面,第二類是啟動時就會確定的配置,這種配置往往透過環境變數,在容器啟動的時候傳進去,第三類就是統一的配置,需要透過配置中心進行下發,例如在大促的情況下,有些功能需要降級,哪些功能可以降級,哪些功能不能降級,都可以在配置檔案中統一的配置。
同樣是行程數目非常多的時候,很難對成千上百個容器,一個一個登入進去檢視日誌,所以需要統一的日誌中心來收集日誌,為了使收集到的日誌容易分析,對於日誌的規範,需要有一定的要求,當所有的服務都遵守統一的日誌規範的時候,在日誌中心就可以對一個交易流程進行統一的追溯。例如在最後的日誌搜尋引擎中,搜尋交易號,就能夠看到在哪個過程出現了錯誤或者異常。
服務要有熔斷,限流,降級的能力,當一個服務呼叫另外一個服務,出現超時的時候,應及時的傳回,而非阻塞在那個地方,從而影響其他使用者的交易,可以傳回預設的託底資料。
當一個服務發現被呼叫的服務,因為過於繁忙,執行緒池滿,連線池滿,或者總是出錯,則應該及時熔斷,防止因為下一個服務的錯誤或繁忙,導致本服務的不正常,從而逐漸往前傳導,導致整個應用的雪崩。
當發現整個系統的確負載過高的時候,可以選擇降級某些功能或某些呼叫,保證最重要的交易流程的透過,以及最重要的資源全部用於保證最核心的流程。
還有一種手段就是限流,當既設定了熔斷策略,也設定了降級策略,透過全鏈路的壓力測試,應該能夠知道整個系統的支撐能力,因而就需要制定限流策略,保證系統在測試過的支撐能力範圍內進行服務,超出支撐能力範圍的,可拒絕服務。當你下單的時候,系統彈出對話方塊說“系統忙,請重試”,並不代表系統掛了,而是說明系統是正常工作的,只不過限流策略起到了作用。
當系統非常複雜的時候,要有統一的監控,主要兩個方面,一個是是否健康,一個是效能瓶頸在哪裡。當系統出現異常的時候,監控系統可以配合告警系統,及時的發現,通知,幹預,從而保障系統的順利執行。
當壓力測試的時候,往往會遭遇瓶頸,也需要有全方位的監控來找出瓶頸點,同時能夠保留現場,從而可以追溯和分析,進行全方位的最佳化。
基於上面這十個設計要點,我們再回來看Kubernetes,會發現越看越順眼。
首先Kubernetes本身就是微服務的架構,雖然看起來複雜,但是容易定製化,容易橫向擴充套件。
如圖黑色的部分是Kubernetes原生的部分,而藍色的部分是網易雲為了支撐大規模高併發應用而定製化的部分。
Kubernetes的API Server更像閘道器,提供統一的鑒權和訪問介面。
眾所周知,Kubernetes的租戶管理相對比較弱,尤其是對於公有雲場景,複雜的租戶關係的管理,我們只要定製化API Server,對接Keystone,就可以管理複雜的租戶關係,而不用管其他的元件。
在Kubernetes中幾乎所有的元件都是無狀態化的,狀態都儲存在統一的etcd裡面,這使得擴充套件性非常好,元件之間非同步完成自己的任務,將結果放在etcd裡面,互相不耦合。
例如圖中Pod的建立過程,客戶端的建立僅僅是在etcd中生成一個記錄,而其他的元件監聽到這個事件後,也相應非同步的做自己的事情,並將處理的結果同樣放在etcd中,同樣並不是哪一個元件遠端呼叫kubelet,命令他進行容器的建立,而是發現etcd中,Pod被系結到了自己這裡,方才拉起。
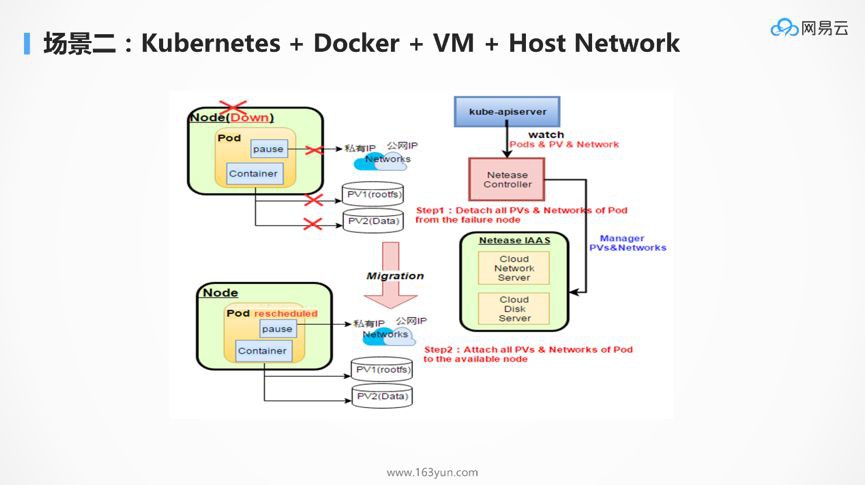
為了在公有雲中實現租戶的隔離性,我們的策略是不同的租戶,不共享節點,這就需要Kubernetes對於IaaS層有所感知,因而需要實現自己的Controller,Kubernetes的設計使得我們可以獨立建立自己的Controller,而不是直接改程式碼。
API-Server作為接入層,是有自己的快取機制的,防止所有的請求的壓力直接到後端的資料庫上。但是當仍然無法承載高併發請求的時候,瓶頸依然在後端的etcd儲存上,這和電商應用一摸一樣。當然能夠想到的方式也是對etcd進行分庫分表,不同的租戶儲存在不同的etcd叢集中。
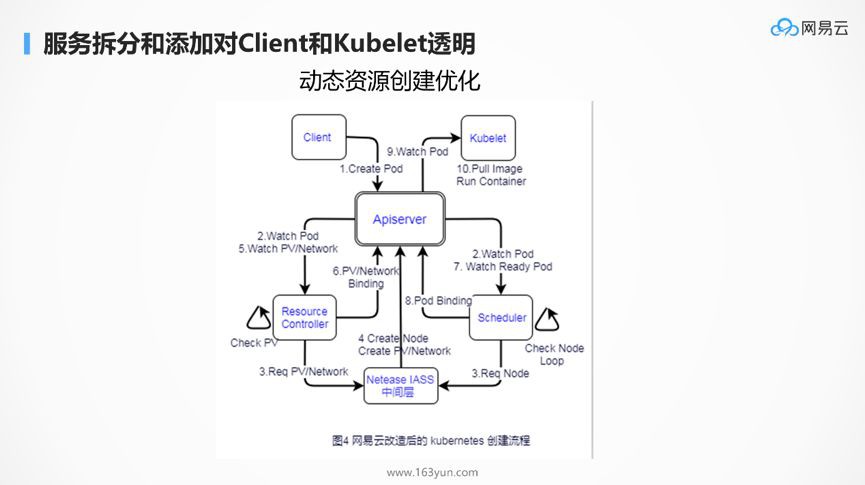
有了API Server做API閘道器,後端的服務進行定製化,對於client和kubelet是透明的。
如圖是定製化的容器建立流程,由於大促和非大促期間,節點的數目相差比較大,因而不能採用事先全部建立好節點的方式,這樣會造成資源的浪費,因而中間添加了網易雲自己的模組Controller和IaaS的管理層,使得當建立容器資源不足的時候,動態呼叫IaaS的介面,動態的建立資源。這一切對於客戶端和kubelet無感知。
為瞭解決超過3萬個節點的規模問題,網易雲需要對各個模組進行最佳化,由於每個子模組僅僅完成自己的功能,Scheduler只管排程,Proxy只管轉發,而非耦合在一起,因而每個元件都可以進行獨立的最佳化,這符合微服務中的獨立功能,獨立最佳化,互不影響。而且Kubernetes的所有元件的都是Go開發的,更加容易一些。所以Kubernetes上手慢,但是一旦需要定製化,會發現更加容易。
五、Kubernetes更加適合微服務和DevOps的設計
好了,說了Kubernetes本身,接下來說說Kubernetes的理念設計,為什麼這麼適合微服務。
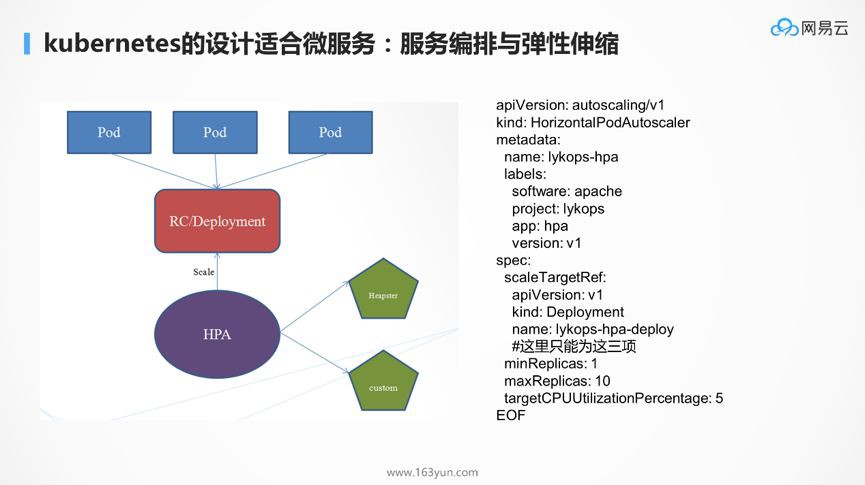
前面微服務設計的十大樣式,其中一個就是區分無狀態和有狀態,在Kubernetes中,無狀態對應deployment,有狀態對應StatefulSet。
deployment主要透過副本數,解決橫向擴充套件的問題。
而StatefulSet透過一致的網路ID,一致的儲存,順序的升級,擴充套件,回滾等機制,可以保證有狀態應用,很好地利用自己的高可用機制。因為大多數叢集的高可用機制,都是可以容忍一個節點暫時掛掉的,但是不能容忍大多數節點同時掛掉。而且高可用機制雖然可以保證一個節點掛掉後回來,有一定的修複機制,但是需要知道剛才掛掉的到底是哪個節點,StatefulSet的機制可以讓容器裡面的指令碼有足夠的資訊,處理這些情況,實現哪怕是有狀態,也能儘快修複。
在微服務中,比較推薦使用雲平臺的PaaS,例如資料庫,訊息匯流排,快取等。但是配置也是非常複雜的,因為不同的環境需要連線不同的PaaS服務。
Kubernetes裡面的headless service是可以很好的解決這個問題的,只要給外部的服務建立一個headless service,指向相應的PaaS服務,並且將服務名配置到應用中。由於生產和測試環境分成Namespace,雖然配置了相同的服務名,但是不會錯誤訪問,簡化了配置。
微服務少不了服務發現,除了應用層可以使用Spring Cloud或者Dubbo進行服務發現,在容器平臺層當然是用Service了,可以實現負載均衡,自修複,自動關聯。
服務編排,本來Kubernetes就是編排的標準,可以將yml檔案放到程式碼倉庫中進行管理,而透過deployment的副本數,可以實現彈性伸縮。
對於配置中心,Kubernetes提供了configMap,可以在容器啟動的時候,將配置註入到環境變數或者Volume裡面。但是唯一的缺點是,註入到環境變數中的配置不能動態改變了,好在Volume裡面的可以,只要容器中的行程有reload機制,就可以實現配置的動態下發了。
統一日誌和監控往往需要在Node上部署Agent,來對日誌和指標進行收集,當然每個Node上都有,daemonset的設計,使得更容易實現。
當然目前最最火的Service Mesh,可以實現更加精細化的服務治理,進行熔斷,路由,降級等策略。Service Mesh的實現往往透過sidecar的方式,攔截服務的流量,進行治理。這也得力於Pod的理念,一個Pod可以有多個容器,如果當初的設計沒有Pod,直接啟動的就是容器,會非常的不方便。
所以Kubernetes的各種設計,看起來非常的冗餘和複雜,入門門檻比較高,但是一旦想實現真正的微服務,Kubernetes是可以給你各種可能的組合方式的。實踐過微服務的人,往往會對這一點深有體會。
下麵我們來看一下,微服務化的不同階段,Kubernetes的使用方式。
也即沒有微服務化的階段,基本上一個行程就能搞定,兩個行程做高可用,不需要使用容器,虛擬機器就非常好。
當微服務開始拆分了,如何保證拆分後功能的一致性,需要持續整合作為保證,如前面的論述,容器是非常好的持續整合工具,是解決CI/CD中D的,所以一開始用host網路就可以,這樣可以保證部署方式和原來相容。
如果想用私有雲進行部署,直接部署在物理機上,在效能要求沒有很高,但是又要和其他物理機很好的通訊的情況下,可以用bridge打平網路的方式比較好。透過建立網橋,將物理網絡卡,容器網絡卡都連線到一個網橋上,可以實現所有的容器和物理機在同樣的一個二層網路裡面。
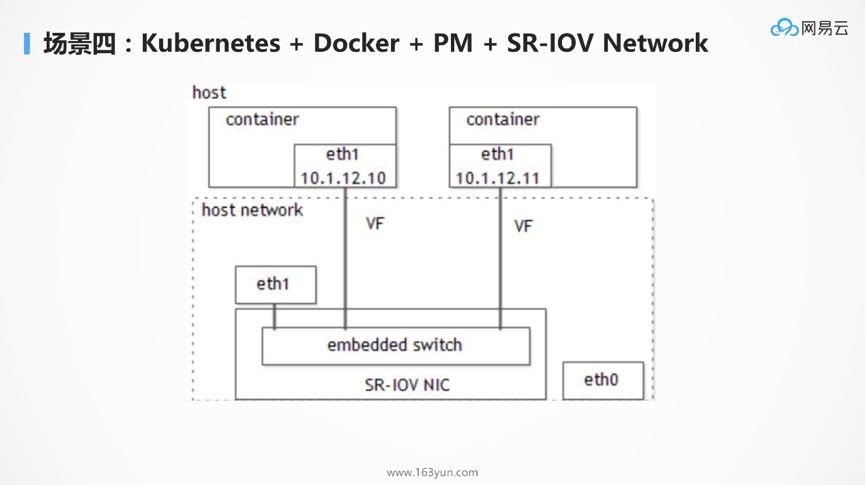
如果效能要求比較高,例如要部署類似快取,則可以使用sr-iov網絡卡。
如果想實現租戶的簡單隔離,則往往使用各種Overlay的網路樣式,這是最常用的部署方式。圖中的資料來自網路。Flannel、Calico都是非常好的網路外掛,雖然Flannel一開始使用使用者態的樣式效能不好,後來使用核心態,效能大大改善,使用gw樣式後,和Calico效能相當。
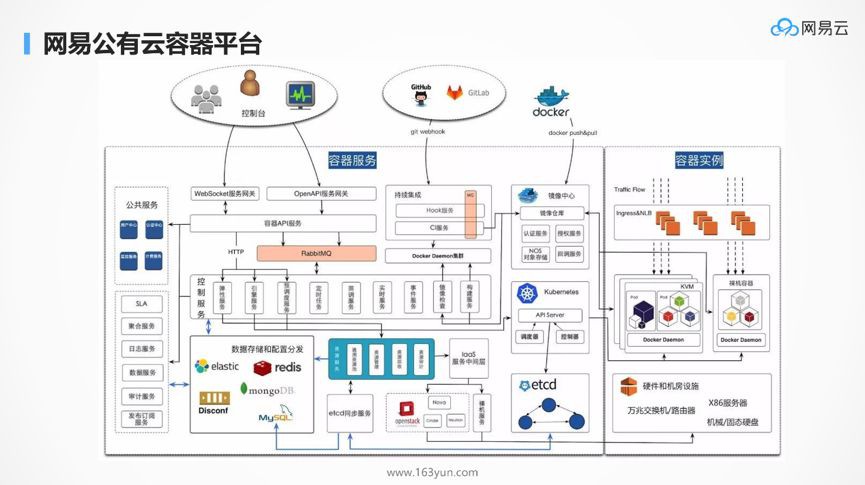
網易雲採用了Kubernetes和IaaS深度融合的方式,類似AWS的Fargate的樣式,一方面可以使得原來使用虛擬機器的使用者平滑地遷移到容器,另一方面可以實現公有雲的租戶隔離。
如圖是融合的網易雲容器服務的架構,這個管理OpenStack和Kubernetes的管理平臺,也是用的微服務架構,有API閘道器,熔斷限流功能,拆分成不同的服務,部署在Kubernetes上的,所以處處是微服務。
本次培訓內容包括:容器原理、Docker架構及工作原理、Docker網路與儲存方案、Harbor、Kubernetes架構、元件、核心機制、外掛、核心模組、Kubernetes網路與儲存、監控、日誌、二次開發以及實踐經驗等,點選瞭解具體培訓內容。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。