概述
用過Docker的開發者都知道,Docker容器在本質上是宿主機上的一個行程。也就是常說的容器是作業系統級的虛擬化。容器與容器之間做了資源的隔離,所以在一個容器內部的各種操作會給人一種彷彿在獨立的系統環境中的感覺。外部應用對容器進行訪問時,也會有這種感覺。而做這種容器資源隔離的Linux核心機制就是namespace。

感受一下namespace的存在
在具體瞭解namespace之前,我們先感受一下namespace的存在。
我們可以使用命令sudo ls -l /proc/[pid]/ns檢視pid為[pid]的行程所屬的namespace。比如我檢視pid為1的行程


可以看到namespace共分為7種型別。分別為ipc、mnt、pid、uts、net、cgroups、user。
如果某個軟連結如ipc指向了同一個ipc namespace,那麼這兩個行程則是在同一個ipc namespace下的。如

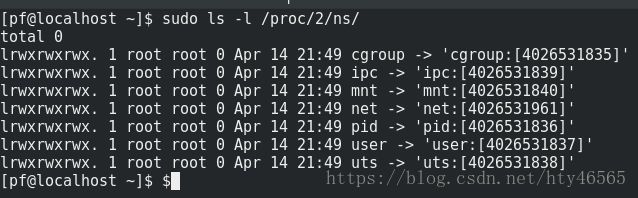
我們可以看到pid為2的行程與pid為1的行程同屬一個ipc namespace。因為它們的指向相同。
以此類推,這兩個行程的mnt、net、pid、user、cgroups、uts namespace也都相同。
如若兩個行程某個軟連結指向不同,即說明這兩個行程該資源已經被隔離了。
操作namespace的API
既然我們知道了實現容器資源隔離的Linux核心機制是namespace,那麼,我們就想瞭解一下Linux提供的namespace操作API。
包括有clone(),setns(),unshare(),接下來分別做簡單介紹:
clone()系統呼叫大家應該都比較熟悉,它的功能是建立一個新的行程。有別於系統呼叫fork(),clone()建立新行程時有許多的選項,透過選擇不同的選項可以創建出合適的行程。我們也可以使用clone()來建立一個屬於新的namespace的行程。這是Docker使用namespace的最基本的方法。

我們可以用man命令檢視clone()的呼叫方式。
fn:傳入子行程執行的程式主函式
child_stack:傳入子行程使用的棧空間
flags:使用哪些標誌位,與namespace相關的標誌位主要包括CLONE_NEWIPC、CLONE_NEWPID、CLONE_NEWNS、CLONE_NEWNET、CLONE_USER、CLONE_UTS。具體含義後面會詳述。
arg:傳入的使用者引數
這個系統呼叫顧名思義就是設定namespace。詳細說來,就是將行程加入到一個已經存在的namespace中。對應於Docker的操作就是在一個Docker容器中用exec執行一個新命令。因為一個Docker容器其實就是一個已經存在的namespace,而用Docker exec執行一個命令,就是將該命令在該容器的namespace中執行,也就是將該命令的行程加入到一個已經存在的namespace中。
依然用man命令看一下這個系統呼叫的使用。
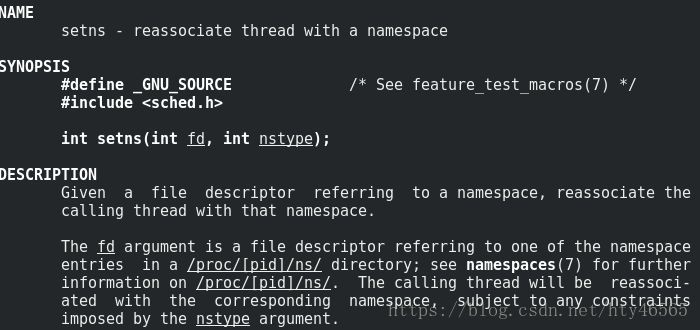
fd:表示要加入的namespace的檔案描述符。它是一個指向/proc/[pid]/ns目錄的檔案描述符,可以透過直接開啟該目錄下的連結得到。
nstype:讓呼叫者可以檢查fd指向的namespace型別是否符合實際的要求。引數為0表示不檢查。
這個系統呼叫與clone()很像,都是做一個新的隔離。而且都透過選擇flags來選擇隔離的資源。不同之處在於clone()建立了一個新的行程,而unshare()是在原行程上作隔離。
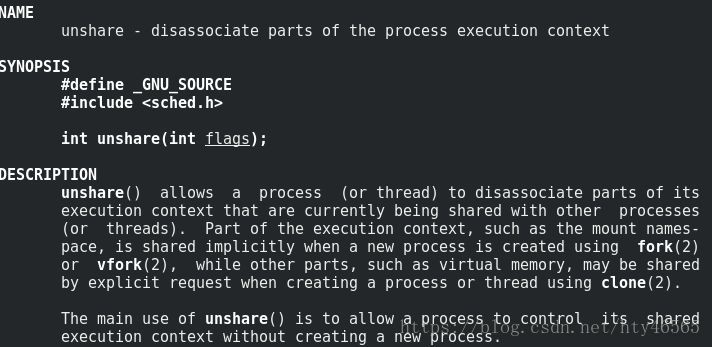
引數flags是標誌位,選擇需要隔離的資源。與clone()的falgs引數基本相同,這裡就不贅述了。
namespace分類詳述
mount namespace
mount namespace透過隔離檔案系統掛載點對檔案系統進行隔離。隔離之後,不同的mount namespace下的檔案結構發生變化也不會互相影響。或許有人註意到,在clone()的flags中,表示新mount namespace的標誌位是CLONE_NEWNS。這是因為mount namespace是歷史上第一個Linux namespace。
cgroup namespace
cgroup Namspace虛擬化了行程的cgroups檢視。cgroups是Linux內核的一個工具,用來做資源的限制的。這裡對此就不詳述了,下次會寫一篇專門講述cgroups機制的文章。
PID namespace
我們都知道,在Linux作業系統中,每一個行程的PID都是在系統中是唯一的。而在容器中,行程的PID可以和另一個容器中某行程的PID相同。這就是對PID的虛擬化。因為兩個容器處於不同的PID namespace下,所以這兩個容器的PID可以有重覆出現。
另外,每一個PID namespace下都會有一個PID為1的行程,它會像傳統Linux中的init行程一樣擁有特權,起特殊作用。
我們可以寫一段程式碼來感受下PID namespace的隔離。
#define _GNU_SOURCE
#include
#include
#include
#include
#include
#include
#define STACK_SIZE (1024*1024)
static char child_stack[STACK_SIZE];
char * const child_args[] = {
“/bin/bash”,
NULL
};
int child_main(void *args) {
printf(“在子行程中!\n”);
execv(child_args[0],child_args);
return 1;
}
int main()
{
printf(“程式開始:\n”);
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWPID|SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf(“已退出\n”);
return 0;
}
編譯執行程式碼,結果如下

我們可以看到,使用clone()新建立了一個行程併進行隔離之後,此當前行程的pid為1。當退出行程後當前行程號又恢復為4639。這個pid為1的行程就是PID namespace中的第一行程,也就是我剛才說的像是Linux下擁有特權的init行程。
我們也可以在新的PID namespace下看看ps命令的結果。

奇怪的是,為什麼在新PID Namespce下使用ps命令還是能看到所有的行程呢?難道不是已經將PID隔離了嗎?理論上應該是不能看到的。
這是因為ps命令或者top命令都是從Linux系統中的/proc目錄下取值的。因為這個時候我們和還沒有用mount namespace進行掛載點的隔離,所以我們總是可以看到這些PID。
IPC namespace
我們看下如下示例:
NULL
};
execv(child_args[0],child_args);
}
waitpid(child_pid, NULL, 0);
}
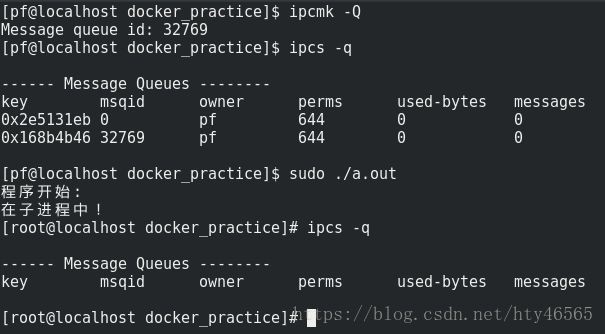
如圖,首先我們使用ipcmk -Q建立了一個訊息佇列。可以知道,這個訊息佇列是在該IPC namespace下的。然後我們依然透過clone()建立了一個新行程,該行程位於新的IPC namespace中。於是使用ipcs -q命令檢視該namespace下的訊息佇列,發現在剛才namespace下建立的訊息佇列在該namespace下並沒有出現。這就說明瞭IPC namespace將行程間通訊訊息佇列隔離了。
user namespace
user namespace主要隔離安全相關的識別符號和屬性,包括使用者ID、使用者組ID、root目錄、key以及特殊許可權。簡單來說,我們可以在Linux中用非root的使用者來建立一個容器,它建立的容器行程卻屬於擁有超級許可權的使用者。
UTS namespace
UTS(Unix Time-sharing System) namespace提供了主機名與域名的隔離。這樣,我們每一個容器都可以擁有自己獨立的主機名和域名了,在外部進行訪問時好似訪問了一個獨立的節點。
同樣,我們用clone()建立一個位於新的UTS namespace下的新行程。
NULL
};
sethostname(“Newnamespace”,12);
execv(child_args[0],child_args);
}
waitpid(child_pid, NULL, 0);
}

Newnamespace了,這就說明,在新的UTS namespace下,主機名被隔離了,我們允許每個容器擁有自己獨立的主機名和域名。network namespace
network namespace主要提供了關於網路資源的隔離,包括網路裝置、IPv4和IPv6協議棧、IP路由表、防火牆、套接字等。簡單說,我們在每個容器中都可以啟動一個Apache行程並佔用“80埠”而不會出現埠衝突。我們知道,假設計算機只有一個物理網路裝置時,該裝置只能位於一個network namespace下提供網路服務。解決的方法是透過建立veth pair在不同的network namespace間進行通訊。
總結
本文從功能角度分類討論了namespace。並舉了一些例子進行實際感受。實際上Docker底層的核心知識不僅包括用來資源隔離的namespace,還包括用來作資源限制與資源監控的cgroups。下一篇文章會簡述cgroups的功能及原理。
