前言
像我這樣的菜鳥,總會有各種疑問,剛開始是對 JDK API 的疑問,對 NIO 的疑問,對 JVM 的疑問,當工作幾年後,對服務的可用性,可擴充套件性也有了新的疑問,什麼疑問呢?其實是老生常談的話題:服務的擴容問題。
正常情況下的服務演化之路
讓我們從最初開始。
1、單體應用 每個創業公司基本都是從類似 SSM 和 SSH 這種架構起來的,沒什麼好講的,基本每個程式員都經歷過。
2、RPC 應用 當業務越來越大,我們需要對服務進行水平擴容,擴容很簡單,只要保證服務是無狀態的就可以了,如下圖:
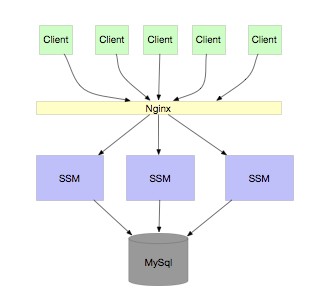
當業務又越來越大,我們的服務關係錯綜複雜,同時,有很多服務訪問都是不需要連線 DB 的,只需要連線快取即可,那麼就可以做成分離的,減少 DB 寶貴的連線。如下圖:
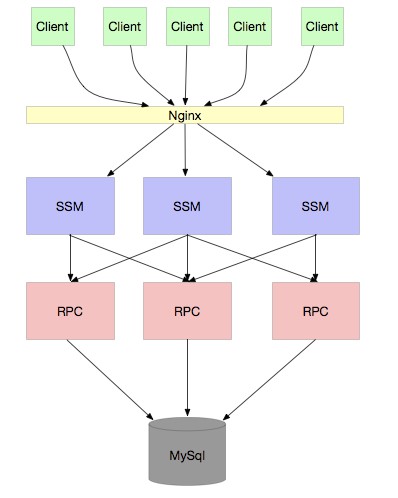
我相信大部分公司都是在這個階段。Dubbo 就是為瞭解決這個問題而生的。
分庫分表
如果你的公司產品很受歡迎,業務繼續高速發展,資料越來越多,SQL 操作越來越慢,那麼資料庫就會成為瓶頸,那麼你肯定會想到分庫分表,不論透過 ID hash 或者 range 的方式都可以。如下圖:
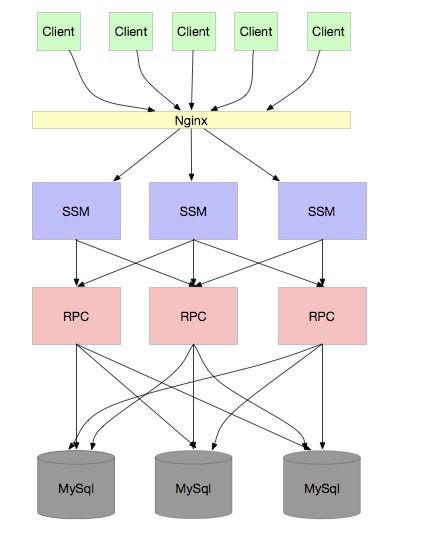
這下應該沒問題了吧。任憑你使用者再多,併發再高,我只要無限擴容資料庫,無限擴容應用,就可以了。
這也是本文的標題,分庫分表就能解決無限擴容嗎?
實際上,像上面的架構,並不能解決。
其實,這個問題和 RPC 的問題有點類似:資料庫連線過多!!!
通常,我們的 RPC 應用由於是使用中介軟體進行訪問資料庫,應用實際上是不知道到底要訪問哪個資料庫的,訪問資料庫的規則由中介軟體決定,例如 sharding JDBC。這就導致,這個應用必須和所有的資料庫連線,就像我們上面的架構圖一樣,一個 RPC 應用需要和 3 個 mysql 連線,如果是 30 個 RPC 應用,每個 RPC 的資料庫連線池大小是8 ,每個 mysql 需要維護 240 個連線,我們知道,mysql 預設連線數是 100,最大連線數是 16384,也就是說,假設每個應用的連線池大小是 8 ,超過 2048 個應用就無法再繼續連線了,也就無法繼續擴容了。註意,由於每個物理庫有很多邏輯庫,再加上微服務運動如火如荼, 2048 並沒有看起來那麼大。
也許你說,我可以透過前面加一個 proxy 來解決連線數的問題,實際上,代理的效能也會成為問題,為什麼?代理的連線數也是不能超過 16384 的,如果併發超過 16384,變成 163840,那麼 proxy 也解決不了問題。
怎麼辦?讓我們再看看上面的架構圖:
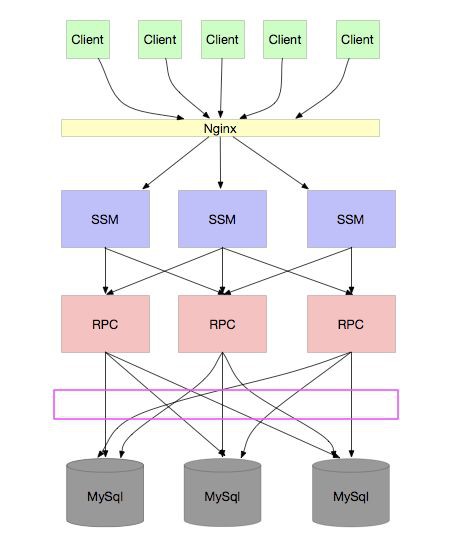
我們發現,問題是出在“每個 RPC 應用都要連所有的庫”,導致擴容應用的同時,每個資料庫連線數就要增加。就算增加資料庫,也不能解決連線數的問題。
那怎麼辦呢?
單元化
單元化,聽起來高大上,通常在一些 XXX 大會上,分享“關於兩地三中心”,“三地五中心”,“異地多活”等等牛逼的名詞的時候,單元化也會一起出現。
這裡我們不討論那麼牛逼的,就只說“資料庫連線數過多” 的問題。
實際上,思路很簡單:我們不讓應用連線所有的資料庫就可以了。
假設我們根據 range 分成了 10 個庫,現在有 10 個應用,我們讓每個應用只連一個庫,當應用增多變成 20個,資料庫的連線不夠用了,我們就將 10 個庫分成 20 個庫,這樣,無論你應用擴容到多少個,都可以解決資料庫連線數過多的問題。
註意:做這件事的前提是:你必須保證,訪問你這個應用的 request 請求的資料庫一定是在這個應用的。
換個說法,當使用者從 DNS 那裡進來的時候,就知道自己要去那個應用了,所以,規則在 DNS 之前就定好了,雖然這有點誇張,但肯定在進應用之前就知道要去哪個庫了。
所以,這通常需要一個規則,例如透過使用者 ID hash,由配置中心廣播 hash 規則。這樣,所有的元件都能保持一致的規則,從而正確的訪問到資料庫。如下圖:
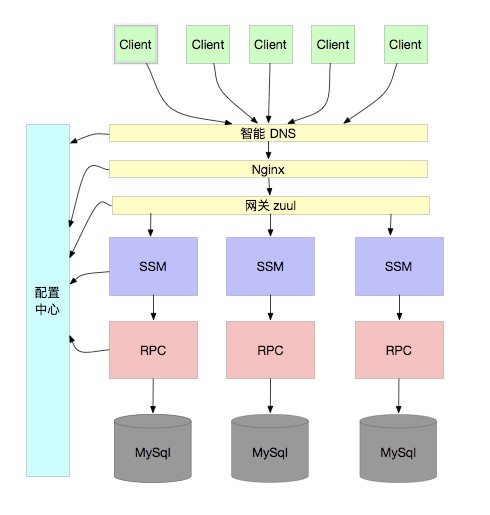
到這裡,我們終於解決了無限擴容的問題。
最後
本文從單體應用開始,逐步講述了一個正常後臺的演進歷程,知道了分庫分表並不能解決“無限擴容” 的問題,只有單元化才能解決這問題。而單元化則帶來更多的複雜性。但是好處不言而喻。
單元化帶來的更多的思路。
有了單元化,解決了無限擴容的問題,但是我們還沒有考慮單點的問題,即服務的可用性。要知道,我們這裡的資料庫都是單點的。
這就是另一個話題 —— 異地多活。限於篇幅,下次再聊。